
大数据技术-spark
Spark是什么
Apache Spark是一个分布式、内存级计算框架, 是一个大数据处理框架
基本概念
Application:用户编写的Spark应用程序。
Driver:Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:有向无环图,反映RDD之间的依赖关系。
Task:运行在Executor上的工作单元。
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
Spark的生态体系
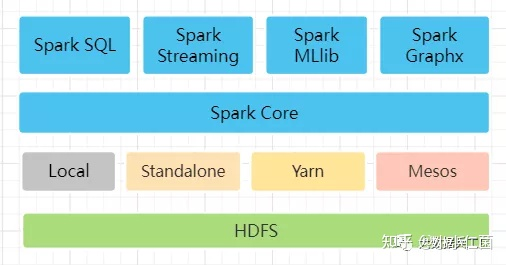
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
Spark架构
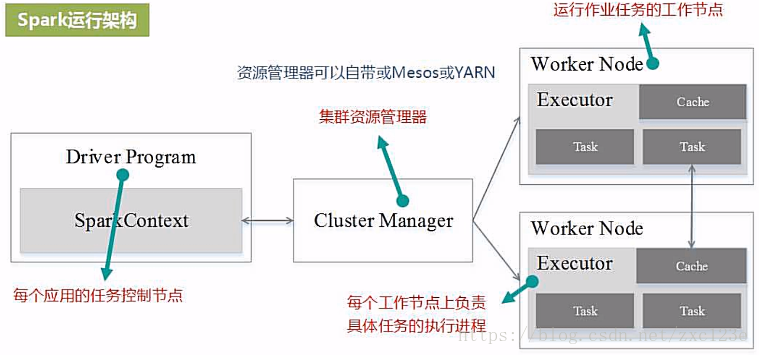
Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
Driver: 运行Application 的main()函数
Executor:执行器,是为某个Application运行在worker node上的一个进程
运行过程
构建Spark Application的运行环境,启动SparkContext
SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
Executor向SparkContext申请Task
SparkContext将应用程序分发给Executor
SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
Task在Executor上运行,运行完释放所有资源
RDD
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群的不同节点上进行并行计算。
RDD提供了一种高端受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map,join和group by)而创建得到新的RDD。
RDD执行过程:
RDD读入外部数据源进行创建
RDD经过一系列的转换(Transformation)操作,没一次都会产生不同的RDD供下一个转换操作使用
最后一个RDD经过“动作”操作进行转换并输出到外部数据源
优点:惰性调用、管道化、避免同步等待,不需要保存中间结果。这和Java8中Stream的概念极其类似
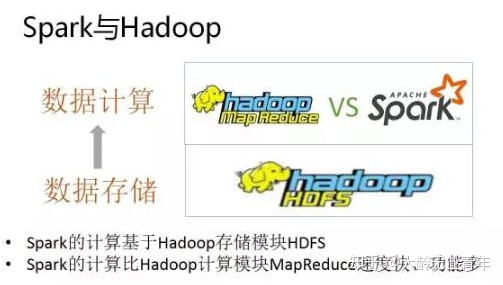
Spark和hadoop
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS
Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富
关系图如下:
相关文章
- 稳扎稳打 Silverlight 4.0 系列文章索引
- Step by Step-构建自己的ORM系列-开篇
- 由Effiproz DataBase来看.NET开源数据库发展
- 使用Mongodb存储上传物理文件并进行SQUID加速(基于aspx页面)
- Silverlight+WCF 新手实例 象棋 专题索引[四十篇后续章已出]
- 系统设计与规划--一点总结
- 讨论: TDD in HTML & JavaScript 之可行性和最佳实践
- 重温数据库访问——故事篇
- 精进不休 .NET 4.0 & .NET 4.5 系列文章索引
- MongoDB的应用
- [讨论]UI层到底使用哪种类?
- Asp.Net 网站优化 数据库优化措施 使用主从库(上)
- Asp.Net 网站优化系列 数据库优化 分字诀 分表(纵向拆分,横向分区)
- (收藏)《博客园精华集》分类索引
- Memcache and Mongodb
- 微軟将弃用 System.Data.OracleClient
- 大家用.net 大部分的工作是在干什么
- 数据之美
- NHibernate的缓存管理机制 - NHibernate 2.1.2
- 我对NHibernate的感受(4):令人欣喜的Interceptor机制