
【C++从入门到放弃】初识C++(基础知识入门详解)
🧑💻作者: @情话0.0
📝专栏:《C++从入门到放弃》
👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢!

前言
C++是一种计算机高级程序设计语言,由C语言扩展升级而产生,最早于1979年由本贾尼·斯特劳斯特卢普在AT&T贝尔工作室研发。
C++既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计。
C++拥有计算机运行的实用性特征,同时还致力于提高大规模程序的编程质量与程序设计语言的问题描述能力。
一、C++关键字
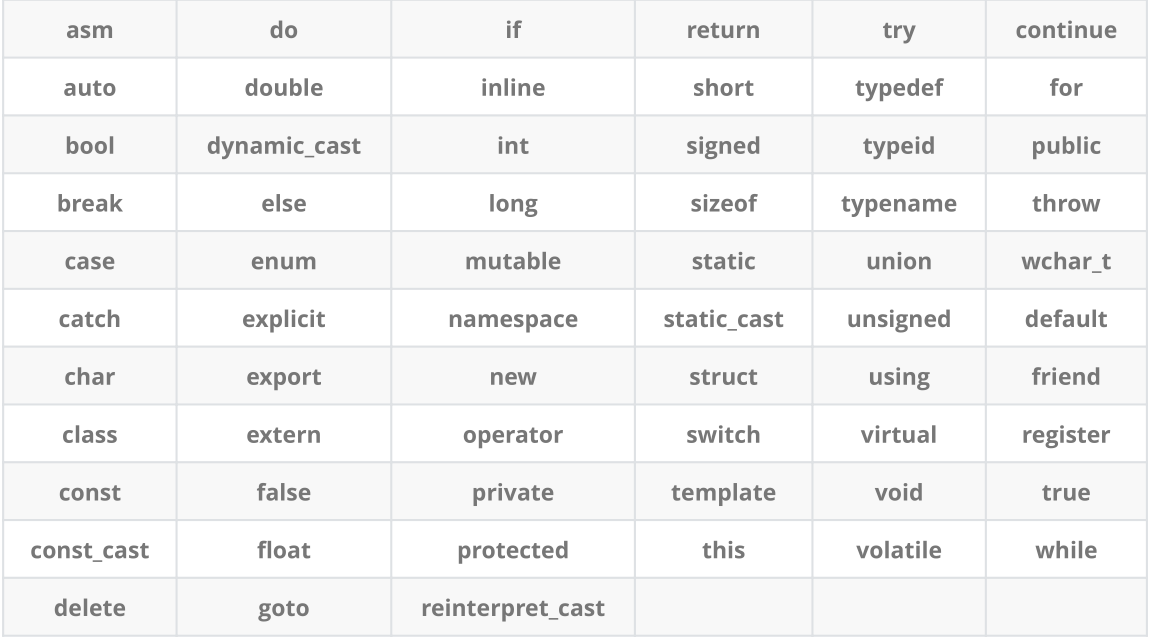
在学习C++之前,我们得大概的去认识C++的关键字有哪些,方便我们以后的学习。
在C++当中,总共有63个关键字,具体都有些什么看下图:
二、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
printf("%d
", rand);
return 0;
}
// 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
在C语言当中,编译器不知道该用自己定义的全局变量还是库函数当中的函数,造成了名字冲突;除此之外,假设在一个项目组当中多人合作,但是两人都定义了一个相同的变量,那么到时要使用该变量也会引起名字冲突。C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决。
1.命名空间的定义
定义命名空间,需要使用到 namespace 关键字,后面再跟上命名空间的名字,然后再接上一对 {}即可,{}中即为 命名空间的成员。
//普通的命名空间
namespace N1 //N1为命名空间的名称
//命名空间中的内容既可以定义变量,也可以定义函数,还可以定义结构体
{
int a;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
//命名空间可以嵌套
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//在同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
//那么下面这个命名空间 N1 会和上面的第一个命名空间 N1 结合在一块
namespace N1
{
int Mul(int left, int right)
{
return left * right;
}
}
注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
2.命名空间的使用
1. 加命名空间名称及作用域限定符
namespace N
{
int a=10;
}
int main()
{
printf("%d
",N::a);
return 0;
}
2.使用using将命名空间中成员引入
namespace N
{
int a=10;
}
using N::a;
int main()
{
printf("%d
",a);
return 0;
}
3.使用using namespace 命名空间名称引入
namespace N
{
int a = 10;
int b = 20;
int Add(int left, int right)
{
return left + right;
}
}
using namespce N;
int main()
{
printf("%d
", N::a);
printf("%d
", b);
Add(10, 20);
return 0;
}
三、C++输入与输出
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{
cout<<"Hello world!!!"<<endl;
return 0;
}
说明:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含头文件中。
- << 是流插入运算符, >> 是流提取运算符。
- 使用C++输入输出更方便,不需要像 printf/scanf 输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
#include <iostream>
using namespace std;
int main()
{
int a;
double b;
char c;
// 可以自动识别变量的类型
cin>>a;
cin>>b>>c;
cout<<a<<endl;
cout<<b<<" "<<c<<endl;
return 0;
}
四、缺省参数

对于备胎大家肯定都熟悉,也知道这两个字其中所富含的意思。,在C++当中函数的参数也可以配备胎。
1. 缺省参数的概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
void Func(int a = 0)
{
cout<<a<<endl;
}
int main()
{
Func(); // 没有传参时,使用参数的默认值
Func(10); // 传参时,使用指定的实参
return 0;
}
2. 缺省参数的分类
2.1 全缺省参数
void Func(int a = 1, int b = 2, int c = 3)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
2.2 半缺省参数
void Func(int a, int b = 2, int c = 3)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- 半缺省参数必须从右往左依次来给出,不能间隔着给。
void TestFunc(int a = 1,int b,int c = 3)
void TestFunc(int a,int b = 2,int c)
void TestFunc(int a = 1,int b = 2,int c) 这三种情况就不允许出现- 缺省参数不能在函数声明和定义中同时出现(如果声明和定义同时出现,并且两个位置给到的参数值不一样,那么编译器就不知道该用哪个缺省值,一般情况会在声明中给到缺省值)
- 缺省值必须是常量或者全局变量
五、函数重载
在C语言中,如果我们在一个工程里去实现几个功能相似的函数,但是由于一 些细节不同,往往就需要利用不同的函数名来进行区分。
比如,我们要实现两个数的相加。
void ADD1(int a,int b);
void ADD2(double a,double b);
void ADD3(float a,float b);
我们可以看出这样的代码很不美观,而且还得给出不同的函数名来加以区分,给程序员造成一定的麻烦。于是在C++中祖师爷就提出了可以使用一个函数名去实现多个函数,也就是所谓的函数重载。
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。
比如:一个人指着药说“太难吃了”,这里我们可以理解的是这个药不可口,这个人不喜欢吃;这个人又指着螃蟹说”太难吃了“,在这里他的意思不是说这个螃蟹不可口,而是吃起来太麻烦了。这个也就是一个很简单一词多义。
1.函数重载的概念
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。
#include<iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
// 2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
return 0;
}
2.名字修饰
C++支持函数重载的原理就在于名字修饰,可是为什么C++支持函数重载,但是C语言不支持函数重载呢?
在C/C++中,一个程序要执行起来,必须得经过以下四个阶段:预处理、编译、汇编、链接。
在编译阶段,编译器会对每个函数实现的名字进行修饰,然后在函数调用的时候会与修饰后的名字匹配,将匹配好的函数的地址给到函数调用处,通过 call 指令来到对应的函数实现处来进行该函数的实现。C++支持函数重载而C语言不支持函数重载的原因就在于它们的函数名字修饰规则不同。在C语言中,函数修饰后的名字不变,所以对于函数来说它就不知道自己该去调用哪个函数,而C++在函数修饰后会因为参数类型的不同而出现不同的函数名,那么每个函数就会根据自己的参数类型去调用合适的函数实现。
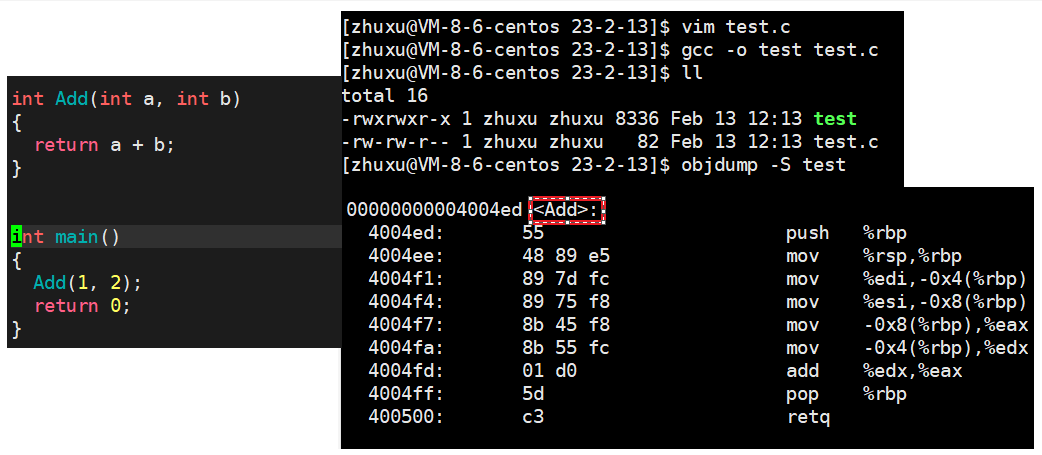
下面这两幅图分别是在Windows下vs的C语言和C++对函数名的修饰(通过不给到函数的实现,只给出函数的声明来得到):


我们可以看到在C语言中并不会对函数进行什么修饰,而在C++中会对其以自己的修饰规则进行修修以到达函数重载,可以看到在Windows环境下的修饰规则有点复杂,一般我们是看不懂,而在Linux下gcc修饰规则比较简单,下面通过在Linux环境下再看一看gcc以及g++的修饰规则。
采用C语言编译器编译后的结果:在LInux下,采用gcc编译完成之后,函数名字的修饰么有发生什么变化。
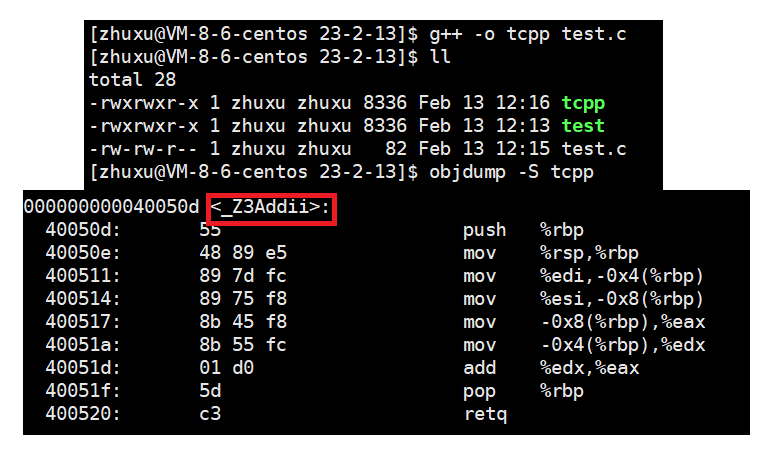
采用C++编译器编译后的结果:在L下采用g++编译完成之后,函数名字的修饰发生了变化,可以看到编译器将函数的参数类型信息添加到了修饰后的名字当中,_Z是LInux规定的,后面的3表示该函数名有三个字母,Add函数名,后面这两个字母都是参数类型的首字母,这个就表示参数都是 int 类型的。
六、引用
1.引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。这也就类似给一个人取外号一样。
void TestRef()
{
int a = 10;
//类型& 引用变量名(对象名) = 引用实体
int& ra = a;//定义引用类型
printf("%p
", &a);
printf("%p
", &ra);
}
引用类型必须和引用实体的类型相同,char类型就不能去引用 int 类型的变量实体。
2.引用特性
- 引用在定义时必须初始化
- 一个变量可以被多次引用
- 引用一旦引用了一个实体,就不可以去引用其他的实体
void Test()
{
int a = 1;
// int& ra; // 该条语句编译时会出错
int& ra = a;
int& rra = a;
int b = 2;
int& ra = b; // 该条语句编译时会出错
}
3. 常引用
void TestConstRef()
{
const int a = 1;
//int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a;
// int& b = 2; // 该语句编译时会出错,b为常量
const int& b = 2;
double d = 3.14;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;
}
4. 使用场景
4.1 做参数
这样做可以避免在传参时额外的参数拷贝,如果不采用引用的话,那么就得在内存中多开辟空间给到这两个参数
void Swap(int& left, int& right)
{
int tmp = left;
left = right;
right = tmp;
}
4.2 做返回值
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
5. 引用与指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。但是在底层实现上实际是有空间的,因为引用是按照指针方式来实现的,并且引用和指针的底层汇编代码是一样的。
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
七、内联函数
被 inline 修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
内联函数的特性
- inline是一种以空间换时间的做法,省去了调用函数的额外开销,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
八、auto关键字
在C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
int a = 10;
auto b = a;//此时编译器会根据 a 的类型来对 b 的类型进行推导为 int
auto c = 'a';
auto d = TestAuto();
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
1 auto使用细则
1.1 auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
1.2在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
auto a = 1, b = 2;
auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
2 auto不能推导的场景
- auto不能作为函数的参数(编译器无法对形参的实际类型进行推导)
- auto不能直接用来声明数组
九、基于范围的for循环
1. 范围for的语法
for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。这样的话在遍历整个集合来说就不需要说明所循环的范围。
void Test()
{
int arr[] = { 1, 2, 3, 4, 5 };
for(auto& e : arr)//要改变数组的值得使用引用
e *= 2;
for(auto e : arr)
cout << e << " ";
return 0;
}
2. 范围for的使用条件
for循环迭代的范围必须是确定的,对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
//该情况就不行,因为范围不确定
void Test(int arr[])
{
for(auto& e : arr)
cout<< e <<endl;
}
十、指针空值nullptr
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0);
f(NULL);
return 0;
}
一般来说,我们都会认为 f(0) 调用第一个函数,f(NULL)调用第二个函数,但是通过运行结果来看都调用了第一个函数,这是为什么呢?
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
在这里,我们发现 NULL 被宏定义为了两种场景,有可能是整形0,有可能是指针类型的0,这也就解释了为什么刚才会出现这种情况。为了避免出现这样的情况,在C++中就引用了nullptr表示指针空值。
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,表示指针空值时最好使用nullptr。
总结
此篇文章也是我学习C++的第一篇总结,文章若有什么问题还望各位大佬指出,互相学习。

相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击