
数据结构与算法:桶排序—如何根据年龄给100万用户数据排序
一、定义
桶排序是一种线性时间的排序算法。
桶排序需要创建若干个桶来协助排序。
每一个桶(bucket)代表一个区间范围,里面可以承载一个或多个元素。
桶排序的第1步,就是创建这些桶,并确定每一个桶的区间范围具体需要建立多少个桶,
如何确定桶的 区间范围,有很多种不同的方式。
我们这里创建的桶数量等于原始数列的元素数量,除最后一个桶只包含数列最大值外, 前面各个桶的区间按照比例来确定。
区间跨度 = (最大值-最小值)/ (桶的数量 - 1)
二、思路
假设有一个非整数数列如下: 4.5,0.84,3.25,2.18,0.5
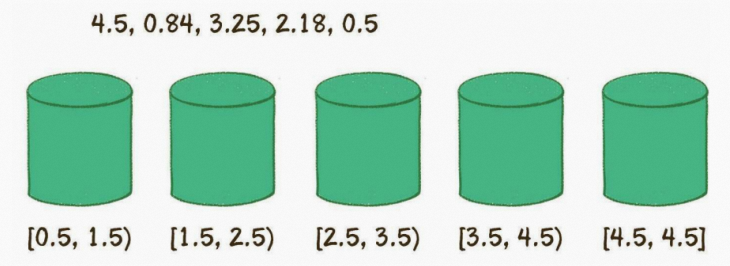
第2步,遍历原始数列,把元素对号入座放入各个桶中。
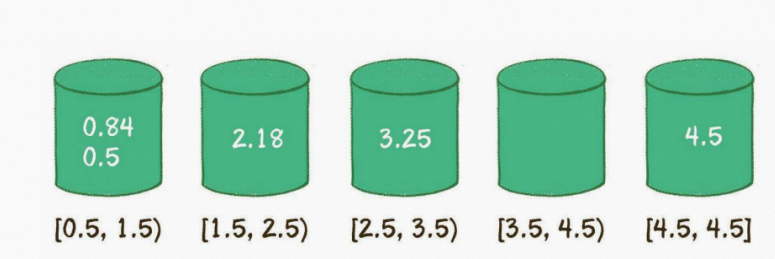
第3步,对每个桶内部的元素分别进行排序(显然,只有第1个桶需要排序)
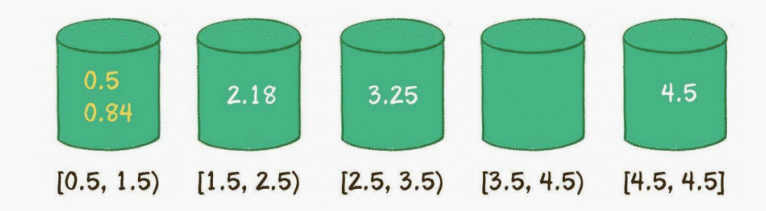
第4步,遍历所有的桶,输出所有元素: 0.5,0.84,2.18,3.25,4.5
三、代码实现
四、复杂度
时间复杂度:O(n)
空间复杂度:O(n)
稳定性:稳定
五、适用场景
桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成m个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为O(nlogn)的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
六、案例
1、需求
我们有10GB的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,但是我们的内存有限,只有几百MB,没办法一次性把10GB的数据都加载到内存中。这个时候该怎么办呢?
2、桶排序解决方案
我们可以先扫描一遍文件,看订单金额所处的数据范围。假设经过扫描之后我们得到,订单金额最小是1元,最大是10万元。我们将所有订单根据金额划分到100个桶里,第一个桶我们存储金额在1元到1000元之内的订单,第二桶存储金额在1001元到2000元之内的订单,以此类推。每一个桶对应一个文件,并且按照金额范围的大小顺序编号命名(00,01,02...99)。
理想的情况下,如果订单金额在1到10万之间均匀分布,那订单会被均匀划分到100个文件中,每个小文件中存储大约100MB的订单数据,我们就可以将这100个小文件依次放到内存中,用快排来排序。等所有文件都排好序之后,我们只需要按照文件编号,从小到大依次读取每个小文件中的订单数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了。
不过,你可能也发现了,订单按照金额在1元到10万元之间并不一定是均匀分布的 ,所以10GB订单数据是无法均匀地被划分到100个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存。这又该怎么办呢?
针对这些划分之后还是比较大的文件,我们可以继续划分,比如,订单金额在1元到1000元之间的比较多,我们就将这个区间继续划分为10个小区间,1元到100元,101元到200元,201元到300元....901元到1000元。如果划分之后,101元到200元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止。
相关文章
- AI绘画:数字时代的提示工程新兴应用
- pip Command Not Found – Mac 和 Linux 错误被解决
- Spring Cloud Alibaba全家桶(三)——微服务负载均衡器Ribbon与LoadBalancer
- 【springcloud 微服务】Spring Cloud Ribbon 负载均衡使用策略详解
- 【机会约束、鲁棒优化】具有排放感知型经济调度中机会约束和鲁棒优化研究【IEEE6节点、IEEE118节点算例】(Matlab代码实现)
- 【微服务】一文读懂网关概念+Nginx正反向代理+负载均衡+Spring Cloud Gateway(多栗子)
- Nginx配置使用详解
- [Python]TempConvert.py(温度转换)解释拓展
- 建造者设计模式
- Nginx配置详解,一文带你搞懂Nginx
- 多线程具体实现
- 【项目设计】高并发内存池
- 使用nginx进行负载均衡
- nacos启动遇到的错误
- Dijkstra-单源最短路径算法
- Nginx负载均衡配置教程-Linux
- 【云服务器 ECS 实战】负载均衡 SLB 概述及配置选型
- 抗体的N端或C端进行修饰ADC偶联物的过程-瑞禧
- RDS服务配置
- 华为云服务-运维篇-负载均衡介绍与平台算法使用