
使用指定GPU训练模型:os.environ[‘CUDA_VISIBLE_DEVICES‘]设置无效问题解决——随笔
之前想使用指定的GPU训练模型,查网上的帖子一般是通过设置环境变量来实现的,然后自己试了一下,在debug的时候发现无论怎么弄显示的device都是‘cuda:0’:
也没有多思考,于是就放弃了设置环境变量来指定GPU的方式,改为用以下方式来指定:
device = torch.device("cuda:5") data = data.to(device) model = model.to(device)在debug的时候,发现模型和数据都非常舒服的装载到了自己想要得gpu上,但是感觉这种方法多少有点麻烦,当有多个文件调用的时候,还要把device做为参数传来传去的,很不便捷。
终于在今天实验的时候发现之前对环境变量设置理解有些问题。

在pycharm中设置环境变量有两种方式,第一种方式是通过右上角Edit Configurations...界面设置:
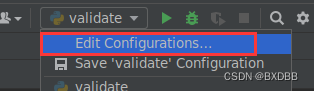
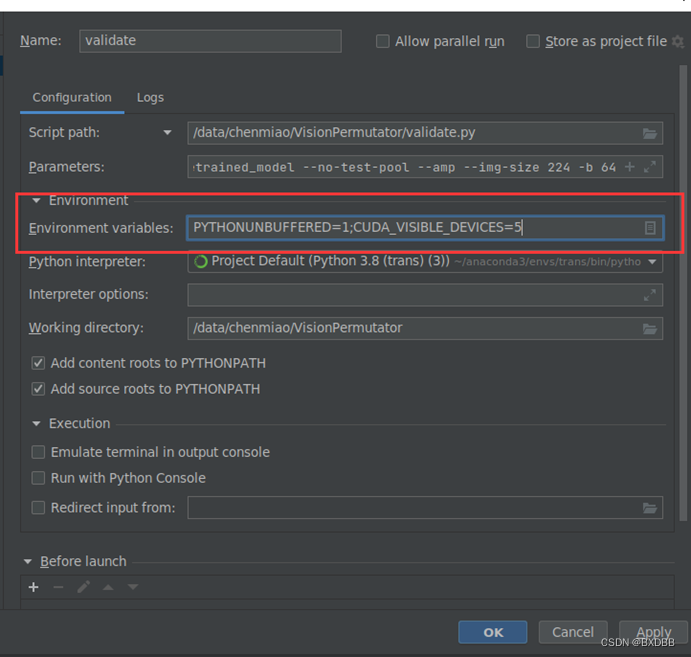
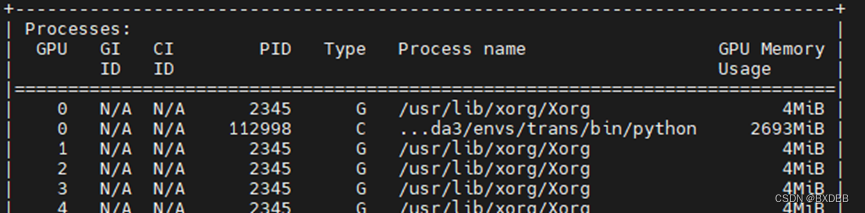
将cuda_visible_devices设置为5后,将模型model = model.cuda()和输入数据input = input.cuda()加载到gpu上,观察到:
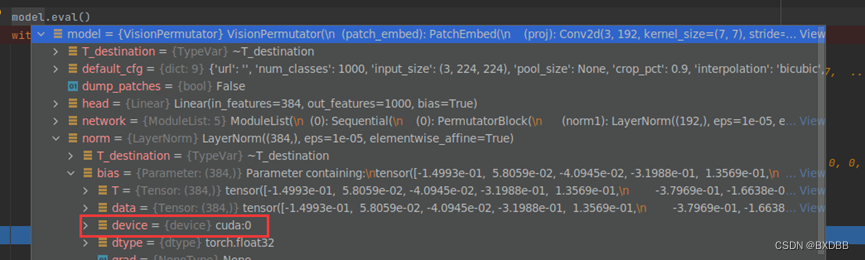

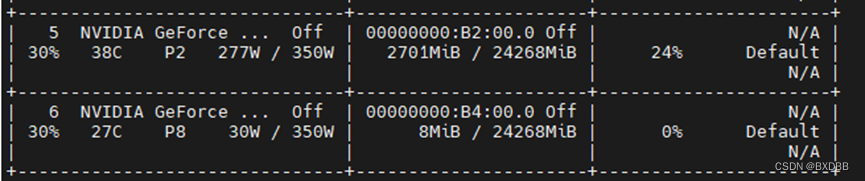
而通过nvidia-smi命令观察到GPU使用情况如图:
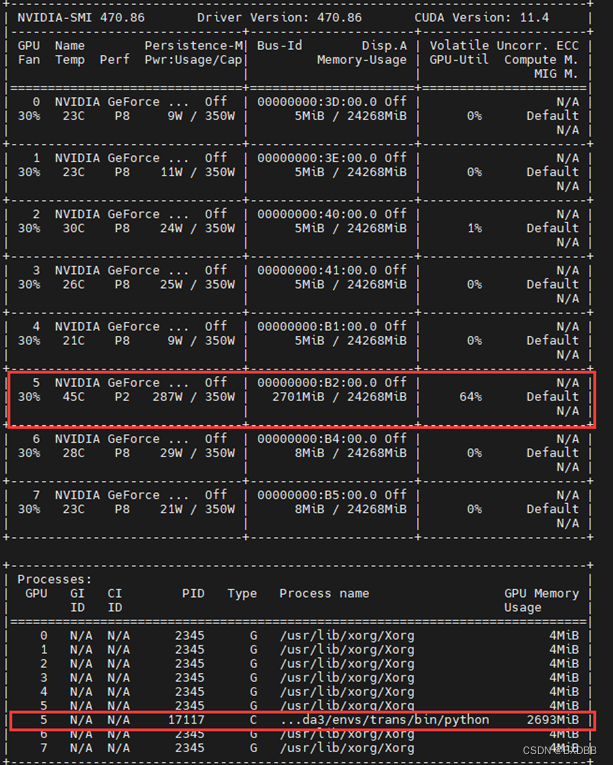
可见,设置环境变量CUDA_VISIBLE_DEVICES=5后,系统会对设置的GPU进行重新编号,从’0’开始。cuda()命令会将模型/数据加载到相对“可见”的第一个GPU上。
第二种方式是在代码里设置,也能达到同样的效果:

我看网上有帖子说环境变量os.environ['CUDA_VISIBLE_DEVICES']='5,6'的设置要放到import torch之前,否则会失效。但我自己试了一下,放到model.cuda()之前都没问题。


当然,如果调换一下顺序,在将模型加载到cuda之后设置环境变量,此时设置会失效,模型参数会放在cuda:0上,后续的input = input.cuda()后,input的device也为cuda:0。

所以只要是在使用cuda之前设置应该都可!(当然为了减少不必要的麻烦,比如说import的其他文件可能会先使用到cuda,还是尽早设置环境变量为好)
参考:
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击