
Python实战-新能源王者宁德时代股权穿透研究(附完整代码)
2023-04-18 15:42:43 时间
继上一篇对贵州茅台和华能信托的股权穿透研究后,又持续对代码做了优化更新,本篇研究新能源王者宁德时代
目录
1、查找网站爱企查
首先选择好查公司股权的网站,这里选择爱企查:https://aiqicha.baidu.com/s?q=
这是网站的首页,默认查企业
2、搜索新能源王者宁德时代
那接下来就是搜索新能源王者宁德时代:
代码如下:
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
上面代码中有几个注意点:
2.1 company_name 参数是:宁德时代
2.2 要加sleep,有可能因为网速原因,页面没加载完,这个根据实际情况来增加这个时间的长短
2.3 可能会报webdriver浏览器驱动和浏览器版本不一致的问题,可以参考我的另外文章:
chrome浏览器版本和Chromedriver不匹配问题解决办法
3、定位筛选第一个公司:宁德时代
通过上面的代码,可以搜索出很多跟宁德时代相关的公司:
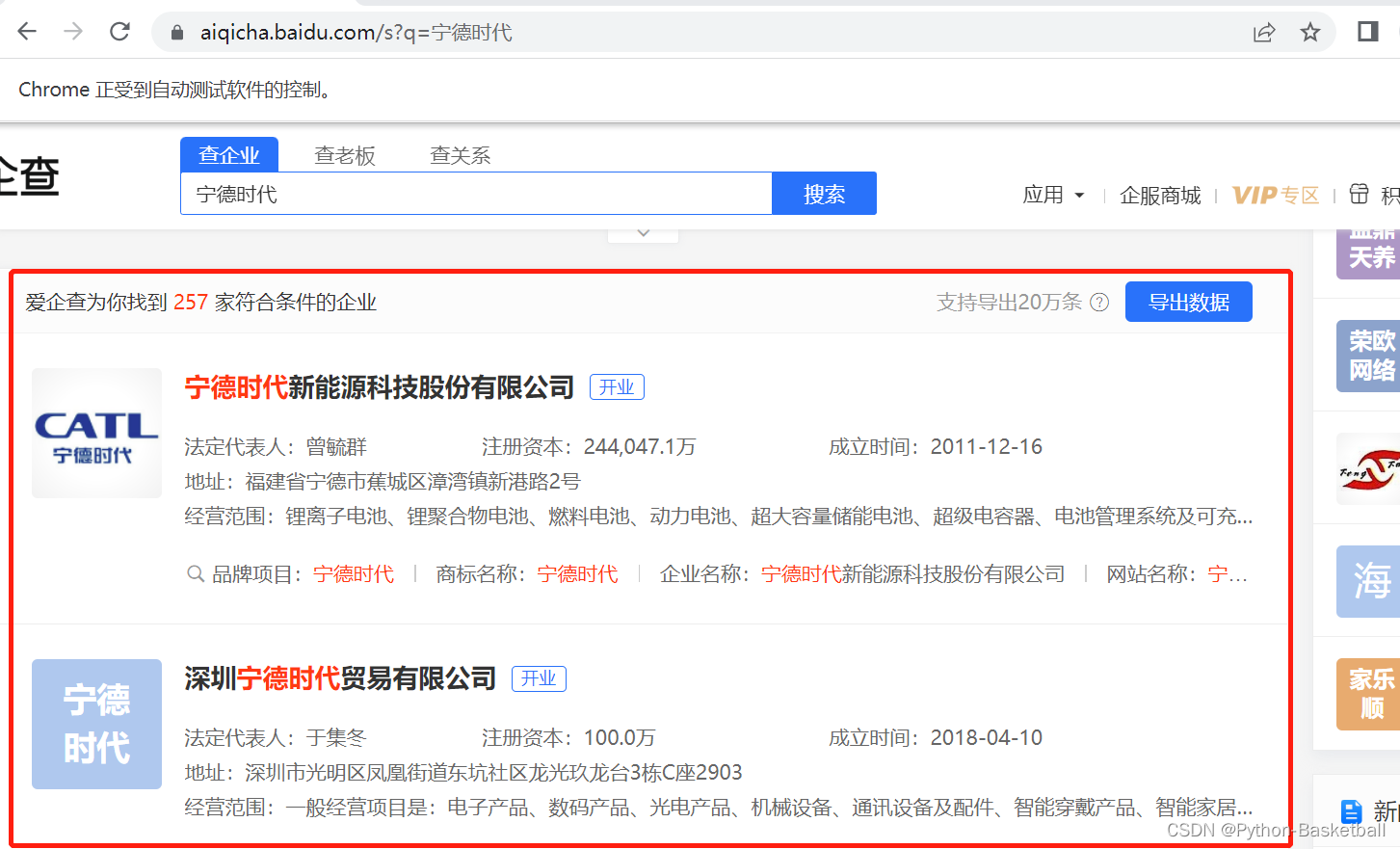
代码中实现如下:
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
获取了所有跟宁德时代相关的公司,我们要取得第一个,代码如下:
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
table = pd.read_html(data)
df = table[1]
browser.quit() # 退出模拟浏览器
4、股权穿透到第一层
可以看到宁德时代的股东很多,第一大股东是:
宁波梅山保税港区瑞庭投资有限公司
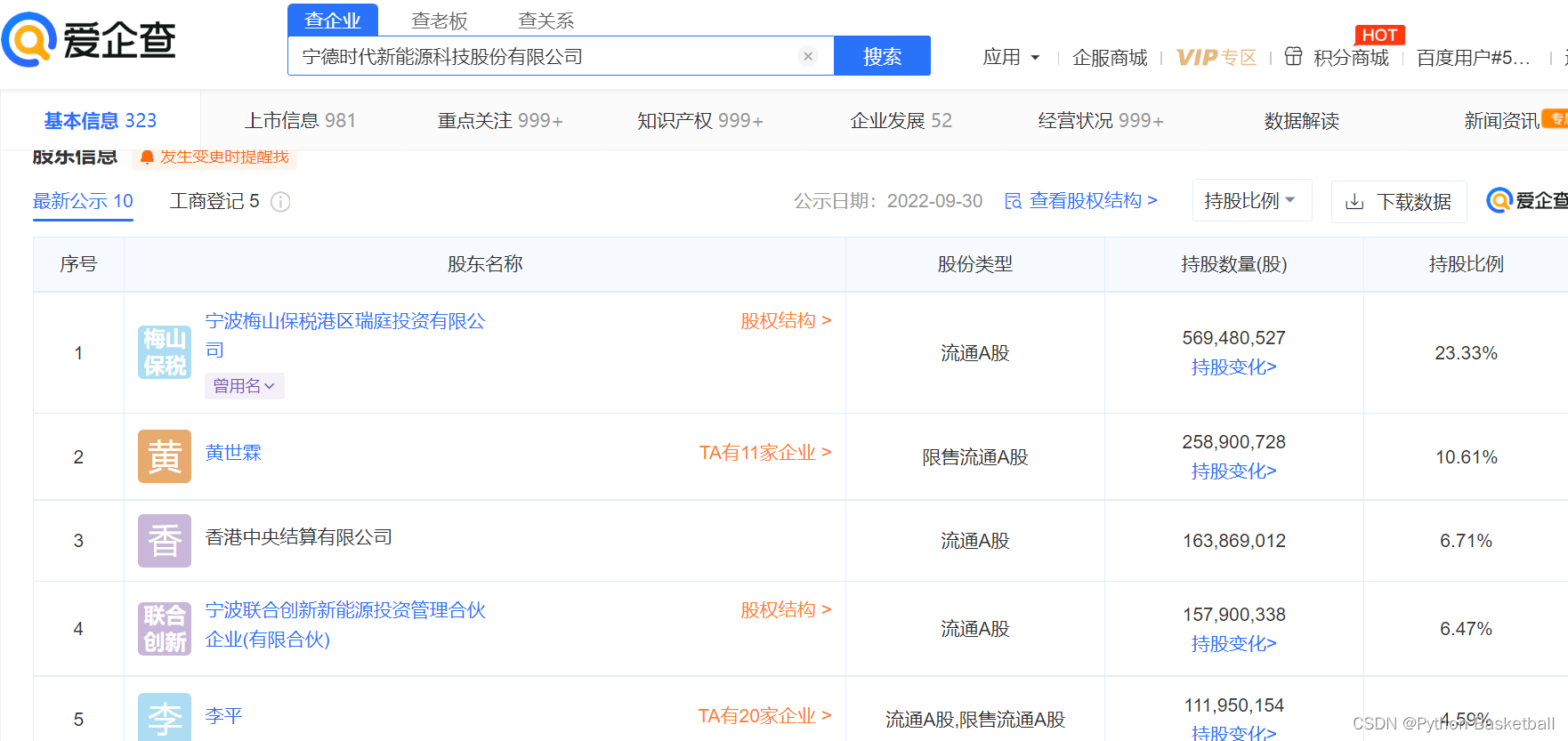
这里面我们继续对第一大股东进行穿透:
company = df['股东名称'][0]
company_split = company.split(' ')
for i in company_split:
if '实际控制人' in i:
print(company)
break
if i.startswith("TA有"):
continue
if i.startswith("实际控制人"):
continue
if len(i) > 6: # 不要用if '有限公司' in i,这个不太好,例如国资委不含有“有限公司 ”字样
return i
会把宁波梅山保税港区瑞庭投资有限公司返回,继续对宁波梅山保税港区瑞庭投资有限公司进行穿透研究
5、股权穿透到第二层
对宁波梅山保税港区瑞庭投资有限公司进行穿透研究,可以看到
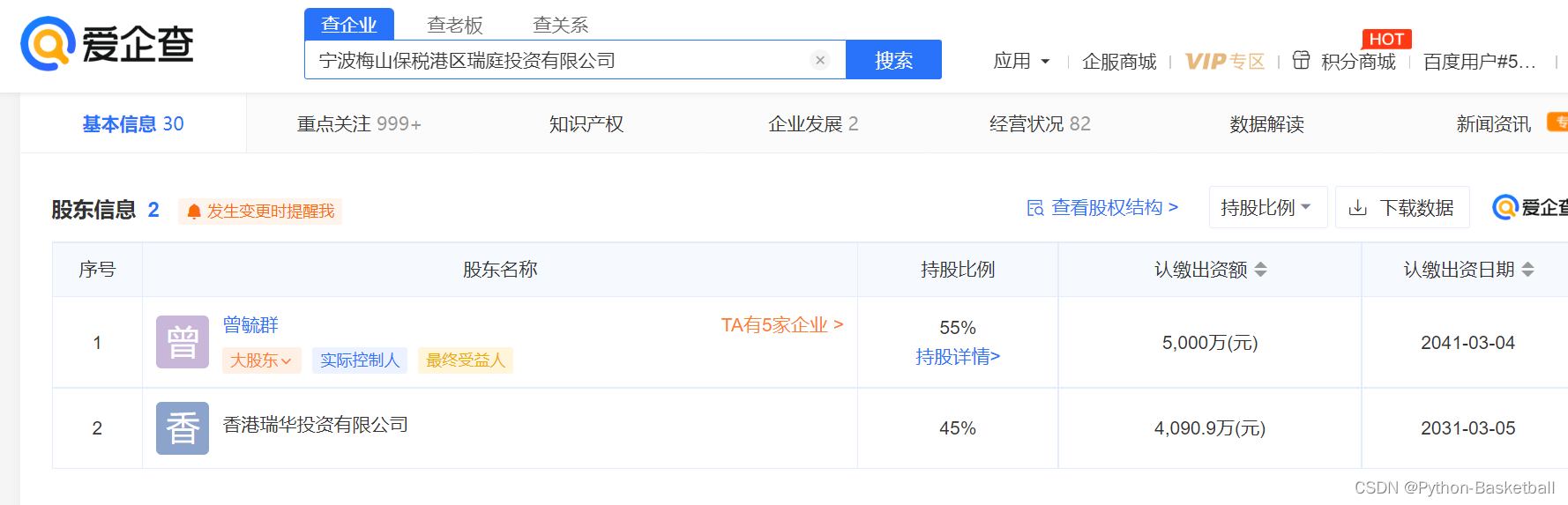
可以看到宁波梅山保税港区瑞庭投资有限公司的第一大股东是曾毓群,其实继续执行了上述代码。
打印结果是:
宁波梅山保税港区瑞庭投资有限公司
曾 曾毓群 TA有5家企业 >大股东 实际控制人最终受益人
55.0
Process finished with exit code 0
完整代码如下:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
from selenium import webdriver
import re
import time
import pandas as pd
def baidu(company_name):
browser = webdriver.Chrome()
url = 'https://xin.baidu.com/s?q=' + company_name
browser.get(url)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
p_href = '<h3 data-v-387da8b0="" class="title"><a data-v-387da8b0="" target="_blank" href="(.*?)"'
href = re.findall(p_href, data)
url2 = 'https://xin.baidu.com' + href[0]
browser.get(url2)
time.sleep(2) # 休息2秒,防止页面没加载完
data = browser.page_source
table = pd.read_html(data)
df = table[1]
browser.quit() # 退出模拟浏览器
company = df['股东名称'][0]
company_split = company.split(' ')
for i in company_split:
if '实际控制人' in i:
print(company)
break
if i.startswith("TA有"):
continue
if i.startswith("实际控制人"):
continue
if len(i) > 6: # 不要用if '有限公司' in i,这个不太好,例如国资委不含有“有限公司 ”字样
return i
num_sum = 0.0
num = 0
for i in df['持股比例']:
if i == '-':
num = 1
break
i = float(i[0:-6]) # 清除百分号,并转为浮点数
print(i)
num_sum = i + num_sum
num += 1
if num_sum > 80:
break
#print("持股比例:", num)
# In[17]:
for i in range(num):
company_i = df['股东名称'][i]
company_split = company_i.split(' ')
for j in company_split:
if '有限公司' in j:
print(j)
company = '宁德时代'
while True:
try:
company = baidu(company)
print(company)
except:
break
company
相关文章
- Python使用tkinter组件Label显示简单数学公式
- 内网渗透之DCOM横向移动
- 以目标为导向的语义交流的共同语言——一个课程学习框架
- python爬虫前奏【成信笔记】
- HTML 5 File API:文件拖放上传功能
- 教你快速创建 Python 虚拟环境
- pyenv 实现Python多版本自由切换
- 用 Python 对 Excel文件进行批量操作
- Python - 接入钉钉机器人
- Python - 抓取 iphone13 pro 线下店供货信息并发送到钉钉机器人,最后设置为定时任务
- crontab - 解决 mac 下通过 crontab 设置了 Python 脚本的定时任务却无法运行
- [源码解析] PyTorch分布式(5) ------ DistributedDataParallel 总述&如何使用
- Python科普系列——类与方法(上篇)
- SAP对STO的交货单执行PGI,报错 -Fld selectn for mvmt type 643 acct 400020 differs
- Spring Boot 实现通用 Auth 认证的 4 种方式
- 盘点4种使用Python批量合并同一文件夹内所有子文件夹下的Excel文件内所有Sheet数据
- OushuDB 学习经验分享(三):技术特点
- Java和Python思维方式的不同之处
- Python中日志记录新技能
- 奥比中光Gemini OpenCV—Python使用