
聊聊C语言的内存分配

1.ANSI C
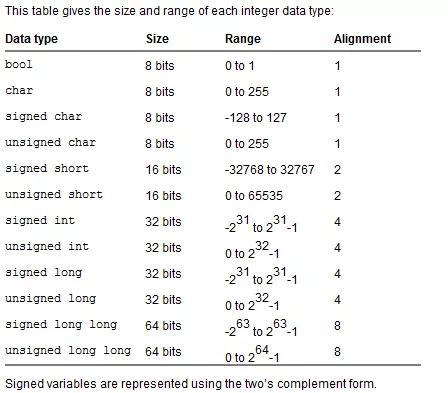
在ANSI C中数据类型包括:整形,浮点型,指针和聚合型(如数组和结构等)
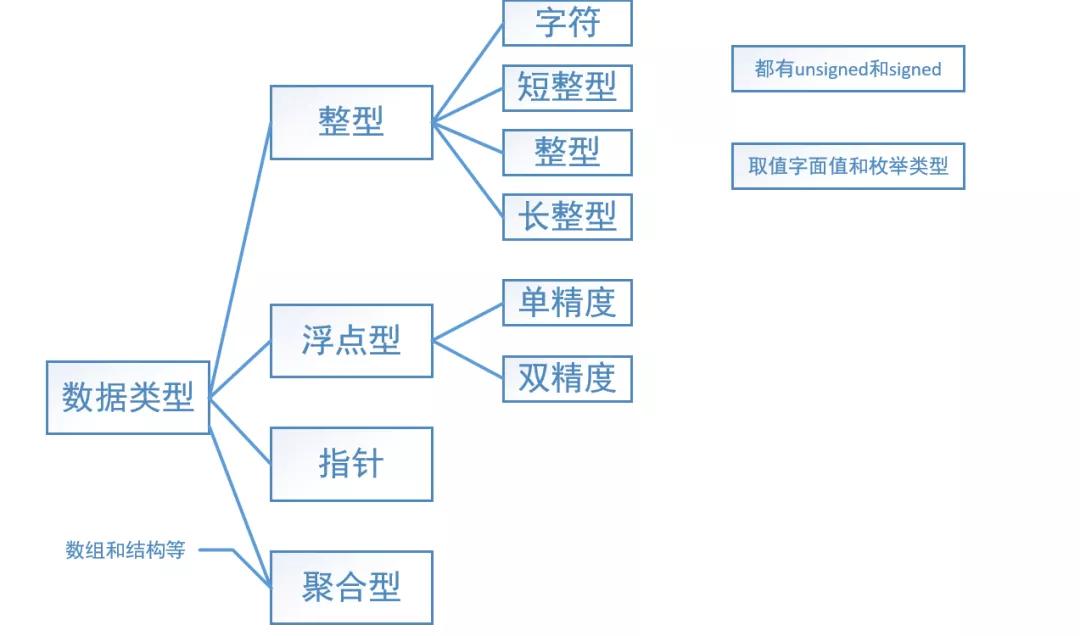
整形:
字符,短整型,整型和长整型,他们都分别有有符号(singed)和无符号(unsingned)
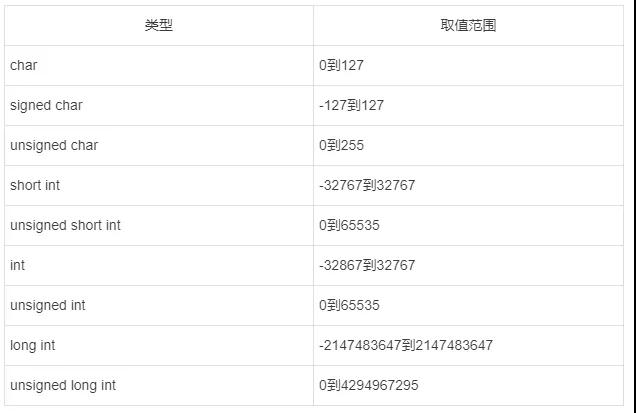
取值范围:
没有带signed或者unsigned,默认signed
长整型至少应该和整型一样长,而整型至少应该和短整型一样长
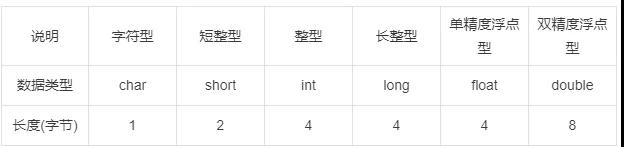
在32位环境中,各种数据类型的长度一般如下:
2ARM C
具体我们以IAR为编译器,版本7.2
注意:
在32位ARM中,字是32位,半字是16位,字节是8位
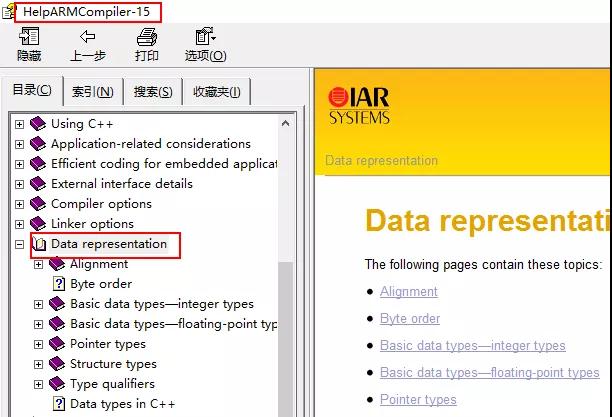
可以看到以下关于整型的数据类型
下面使用typedef重新定义数据类型,没有使用到long,因为都是32位的有一个int就够了
- typedef unsigned char uint8; //!< 无符号8位整型变量
- typedef signed char int8; //!< 有符号8位整型变量
- typedef unsigned short uint16; //!<无符号16位整型变量
- typedef signed short int16; //!< 有符号16位整型变量
- typedef unsigned int uint32; //!< 无符号32位整型变量
- typedef signed int int32; //!<有符号32位整型变量
- typedef float fp32; //!< 单精度浮点数(32位长度)
- typedef double fp64; //!< 双精度浮点数(64位长度)
3C语言内存分配方法
在标准C语言中,编译出来的可执行程序分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分。如下代码
- #include <stdlib.h>
- int a = 0; //a在全局已初始化数据区
- char *p1; //p1在BSS区(未初始化全局变量)
- void main()
- {
- int b; //b在栈区
- int c; //C为全局(静态)数据,存在于已初始化数据区
- char s[] = "abc"; //s为数组变量,存储在栈区,
- char *p2,*p3; //p2、p3在栈区
- p2 = (char *)malloc(10);//分配得来的10个字节的区域在堆区
- p3 = (char *)malloc(20);//分配得来的20个字节的区域在堆区
- free(p2);
- free(p3);
- }
使用linux编译之后得到的可执行文件如下

可以看到代码区(text)、数据区(data)和未初始化数据区(bss)。
代码段(text):存放代码的地方。只能访问,不能修改,代码段就是程序中的可执行部分,直观理解代码段就是函数堆叠组成的。
数据段(data):全局变量和静态局部变量存放的地方。也被称为数据区、静态数据区、静态区:数据段就是程序中的数据,直观理解就是C语言程序中的全局变量。注意是全局变量或静态局部变量,局部变量不算。
未初始化数据区(bss):bss段的特点就是被初始化为0,bss段本质上也是属于数据段。
那么问题来了,为什么要区分data段和bss段呢?
以下面代码为例,a.c和b.c的差异只是有没有给arr数组赋值。
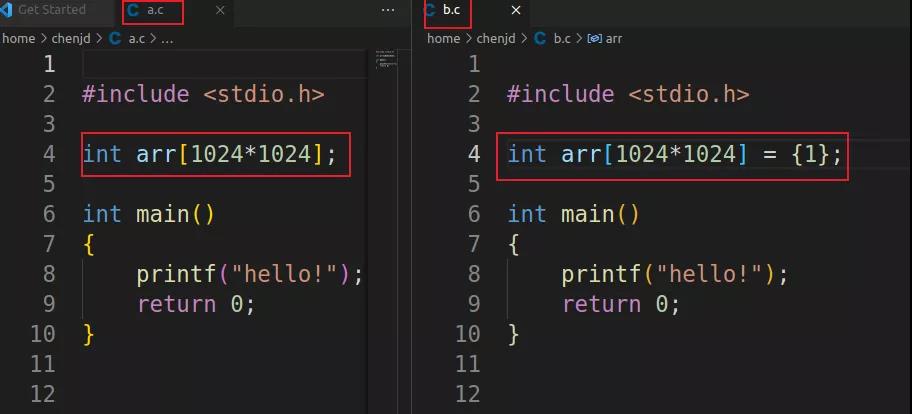
可以看到a.out的bss段大,b.out的data段大。但是b.out的文件大小明显比a.out的大很多。
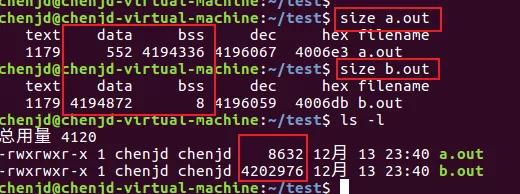
那么就可以简单理解为,data段会增大可执行文件的大小,而bss段不会。
这里我说下自己的理解,我并没有找到资料验证:
data段是全局变量,但是需要初始化值,上面我的例子是全部初始全部为1,但也可能是1024*1024个不同的数据,而这些数据需要保存起来,表现出来也就是需要保存在可执行文件中。
bss段也是全局变量,但不需要初始化值,只需要保存一下这个全部变量的保存的数据类型和大小即可。即使它的数组容量是1024*1024,也不会占用很多可执行文件的大小。
这里再说明一个问题:如果一个全部变量初始化为0,那么它也是bss段,不是data段,即使你代码中把它初始化为0了。这点大家可以自行验证。
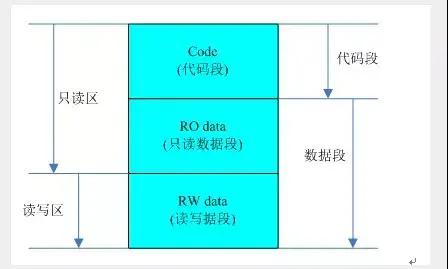
关于数据段,也就是data段,也会分为RO data(只读数据段)和RW data(读写数据段)。
从字面意思就可以区分他们的意思,不同的是:
只读数据段:程序使用的一些不会被更改的数据,使用这些数据的方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
读写数据段:程序中是可以被更改的数据,且初始化过的,所以需要防止在RAM中,且初始化的内容放在存储器中(表现为放入可执行文件中)。
这样又可以分区只读区和读写区域,如下所所示(当然bss段和下文的堆栈也是读写区)
上面说到“编译出来的可执行程序分为代码区(text)、数据区(data)和未初始化数据区(bss)3个部分”,那运行中就会多出来一些区域,这就是我们茶说的堆栈,注意堆栈是两个区域堆和栈。
栈:局部变量、函数一般在栈空间中。运行时自动分配&自动回收:栈是自动管理的,程序员不需要手工干预。方便简单。是提前分配好的连续的地址空间。栈的增长方向是向下的,即向着内存地址减小的方向。
堆:堆内存管理者总量很大的操作系统内存块,各进程可以按需申请使用,使用完释放。程序手动申请&释放:手工意思是需要写代码去申请malloc和释放free。可以是不连续的地址空间。堆的增长方向是向上的,即向着内存地址增加的方向。
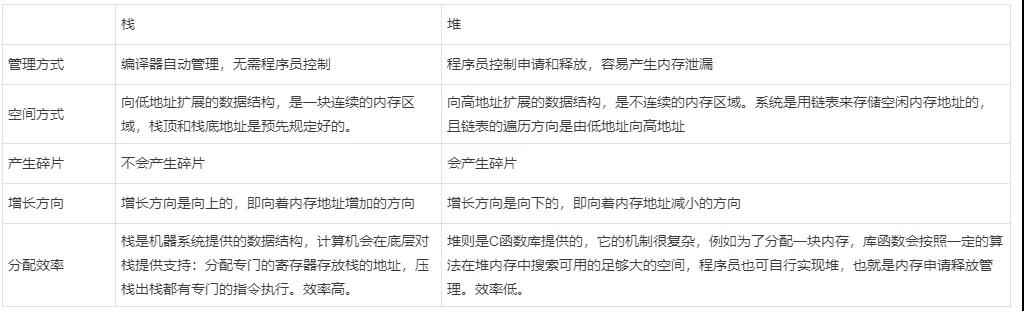
下面是简单的演示代码
- #include <stdlib.h>
- #include <stdio.h>
- int bss_var; //未初始化全局数据存储在BSS区
- int data_var=42; //初始化全局数据存储在数据区
- int main(int argc,char *argv[])
- {
- char *p ,*b;
- printf("Adr bss_var:0x%x ",&bss_var);
- printf("Adr data_var:0x%x ",&data_var);
- printf("the %s is at adr:0x%x ","main",&main);
- p=(char *)alloca(32); //从栈中分配空间
- if(p!=NULL)
- {
- printf("the p start is at adr:0x%x ",p);
- printf("the p end is at adr:0x%x ",p+31);
- }
- b=(char *)malloc(32*sizeof(char)); //从堆中分配空间
- if(b!=NULL)
- {
- printf("the b start is at adr:0x%x ",b);
- printf("the b end is at adr:0x%x ",b+31);
- }
- free(b); //释放申请的空间,以避免内存泄漏
- while(1);
- }
运行结果如下
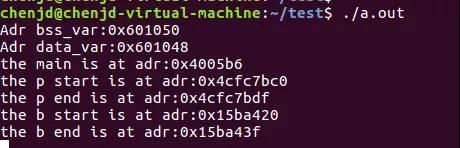
内存分配示意图如下
相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击