
数据分析案例-电影数据可视化分析
数据介绍
数据为2011-2021电影数据
可视化分析
首先导入本次项目需要的包和数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
sns.set_style('ticks')
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data = pd.read_excel('data.xlsx')
data.head()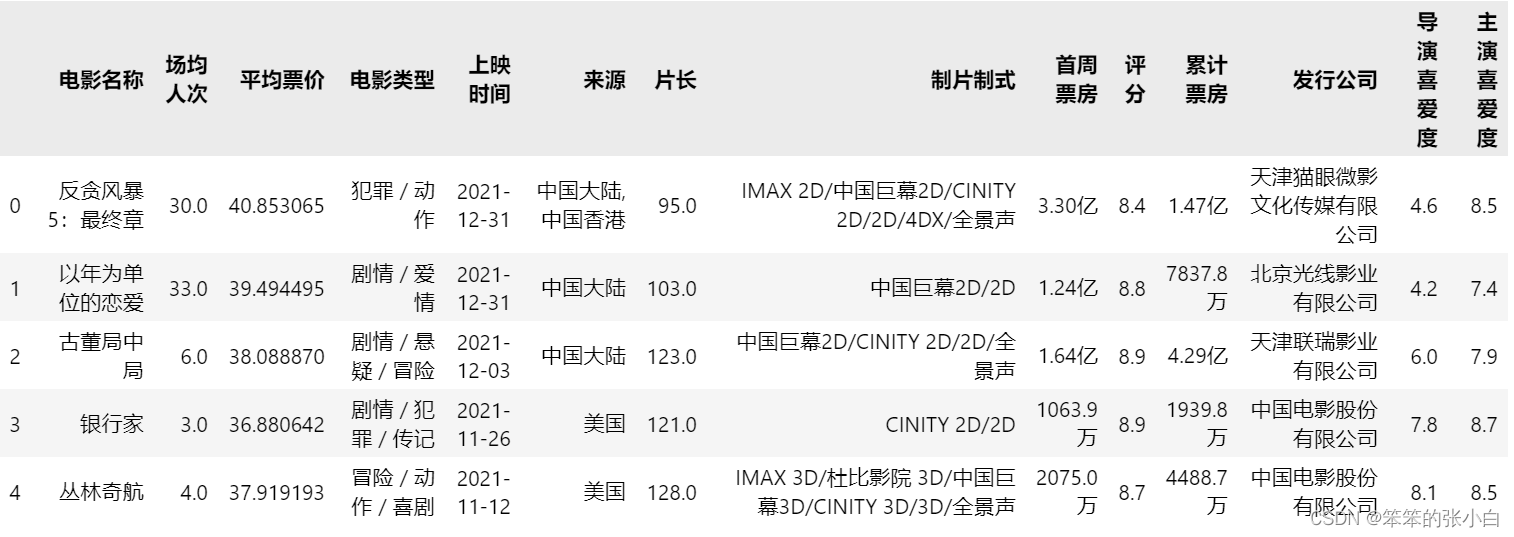
数据预处理
data.dropna(inplace=True)
data.reset_index(drop=True,inplace=True)
data.drop_duplicates(['电影名称'],inplace=True)
data['年份'] = data['上映时间'].apply(lambda x:x.split('-')[0])
# 将首周票房中的--数据删除
data[data['首周票房']=='--'].index
data.drop(index=data[data['首周票房']=='--'].index,inplace=True)
data.reset_index(drop=True,inplace=True)
# 将首周票房亿单位转化为万,且只保留数字
data['首周票房'] = data['首周票房'].apply(lambda x: float(x[:-1])*1000 if x[-1] == '亿' else float(x[:-1]))
# 将累计票房亿单位转化为万,且只保留数字
data['累计票房'] = data['累计票房'].apply(lambda x: float(x[:-1])*1000 if x[-1] == '亿' else float(x[:-1]))可视化
# 分析各个年份的总票房
df1 = data.groupby('年份').sum()['累计票房']
plt.figure(figsize=(10,8))
plt.title('各个年份的总票房',fontsize=14)
plt.xlabel('年份',fontsize=14)
plt.ylabel('总票房(万元)',fontsize=14)
plt.bar(x=df1.index,height=df1.values)
plt.show()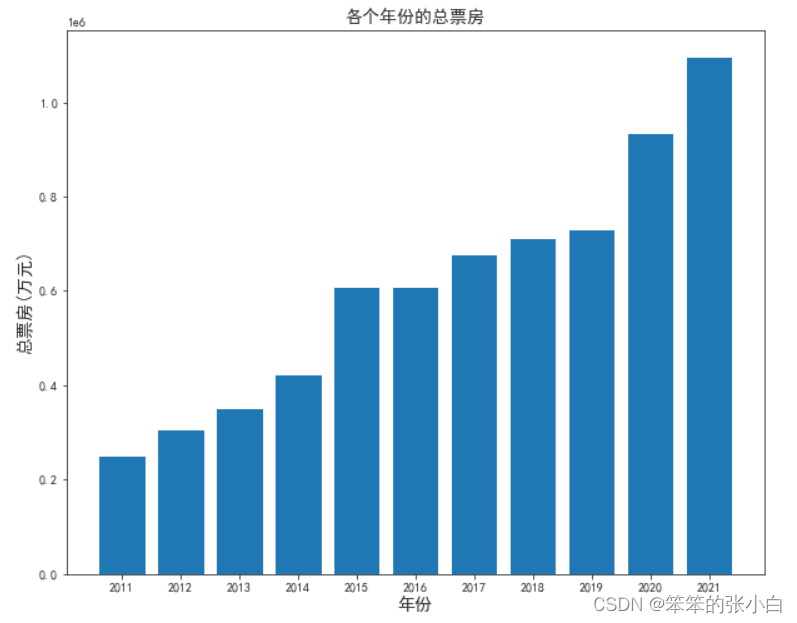
# 分析各个年份的电影比例
result_list = [(i,j) for i,j in zip(df1.index.to_list(),df1.values.tolist())]
a = Pie(init_opts=opts.InitOpts(theme = ThemeType.DARK))
a.add(series_name='年份',
data_pair=result_list,
rosetype='radius',
radius='70%',
)
a.set_global_opts(title_opts=opts.TitleOpts(title="各个年份的电影比例",
pos_top=50))
a.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a.render_notebook() 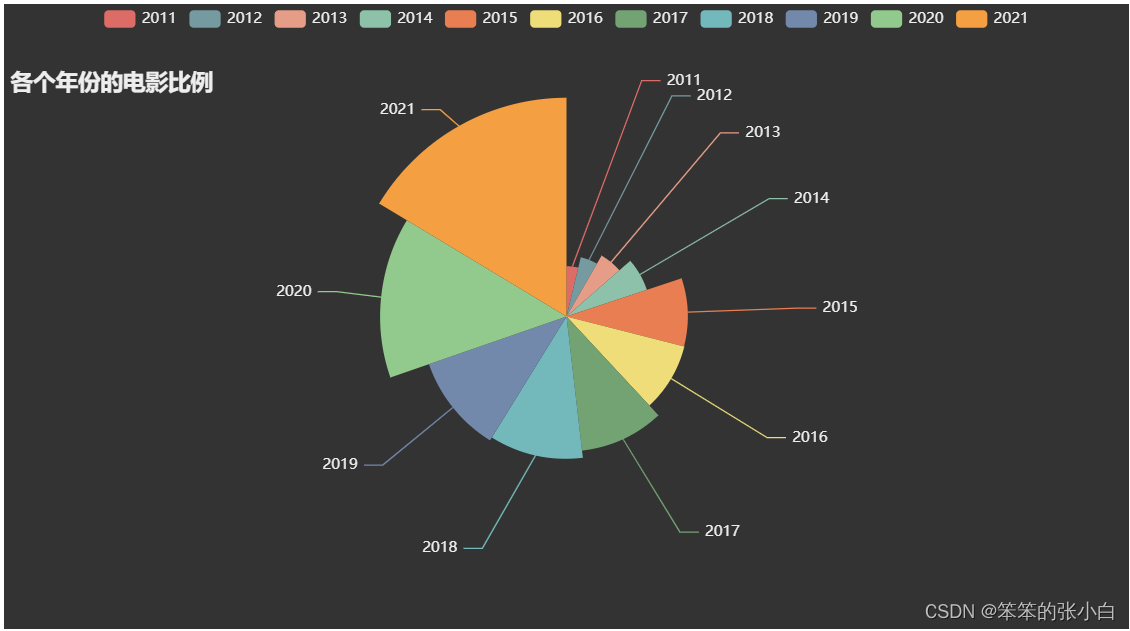
# 分析各个年份的平均票价
df2 = data.groupby('年份').mean()['平均票价']
plt.figure(figsize=(10,8))
plt.title('各个年份的平均票价',fontsize=14)
plt.xlabel('年份',fontsize=14)
plt.ylabel('平均票价(元)',fontsize=14)
plt.plot(df2.index,df2.values)
plt.show() 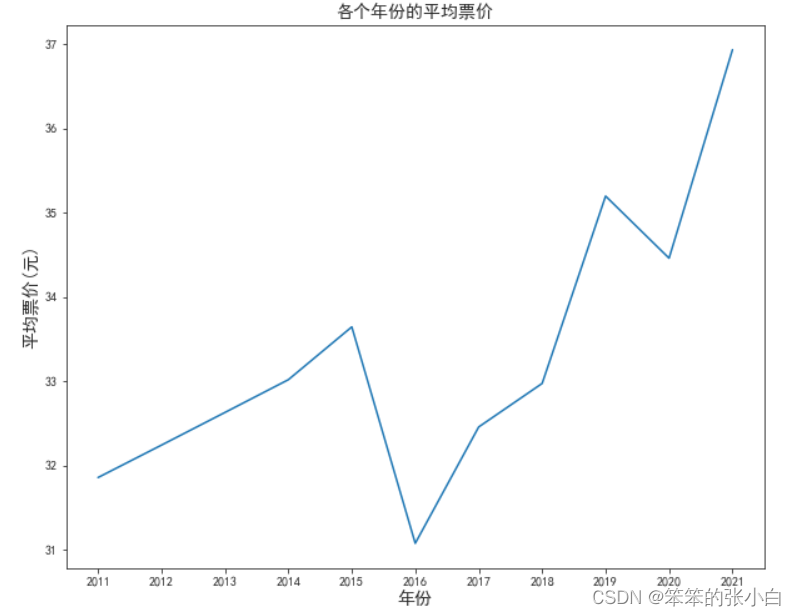
# 分析电影片长的分布
sns.displot(data['片长'],bins=30,kde=True)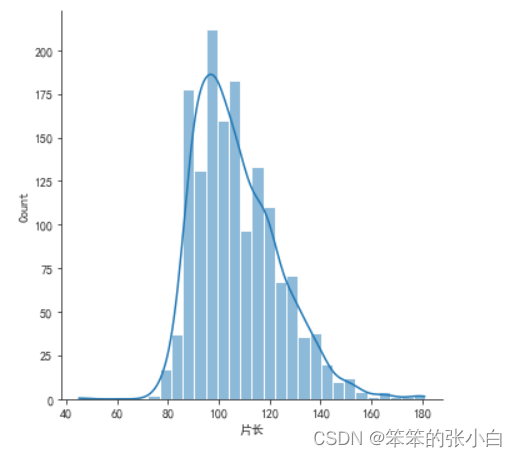
# 分析电影平均票价的分布
sns.displot(data['平均票价'],kde=True) 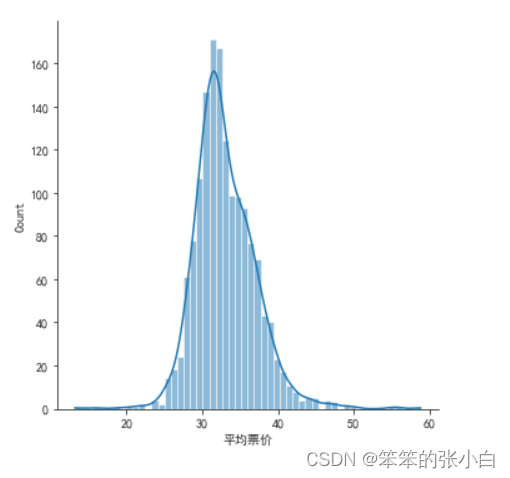
# 分析导演喜爱度的分布
sns.displot(data['导演喜爱度'],kde=True) 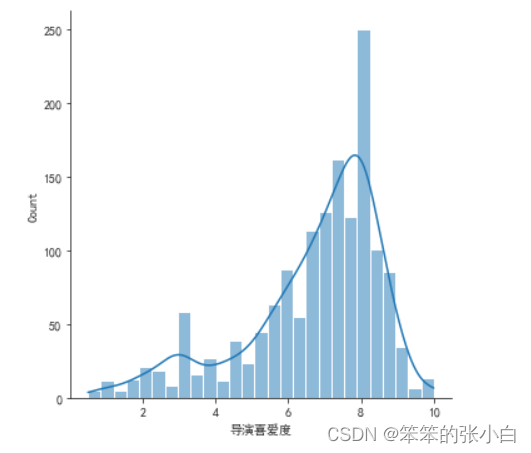
df3 = data['来源'].apply(lambda x:x.split(',')[0]).value_counts().head()
# 各个地区的电影比例
a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.CHALK))
a1.add(series_name='地区',
data_pair=[list(z) for z in zip(df3.index.to_list(),df3.values.tolist())],
rosetype='radius',
radius='60%',
)
a1.set_global_opts(title_opts=opts.TitleOpts(title="各个地区的电影比例",
pos_left='center',
pos_top=30))
a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a1.render_notebook()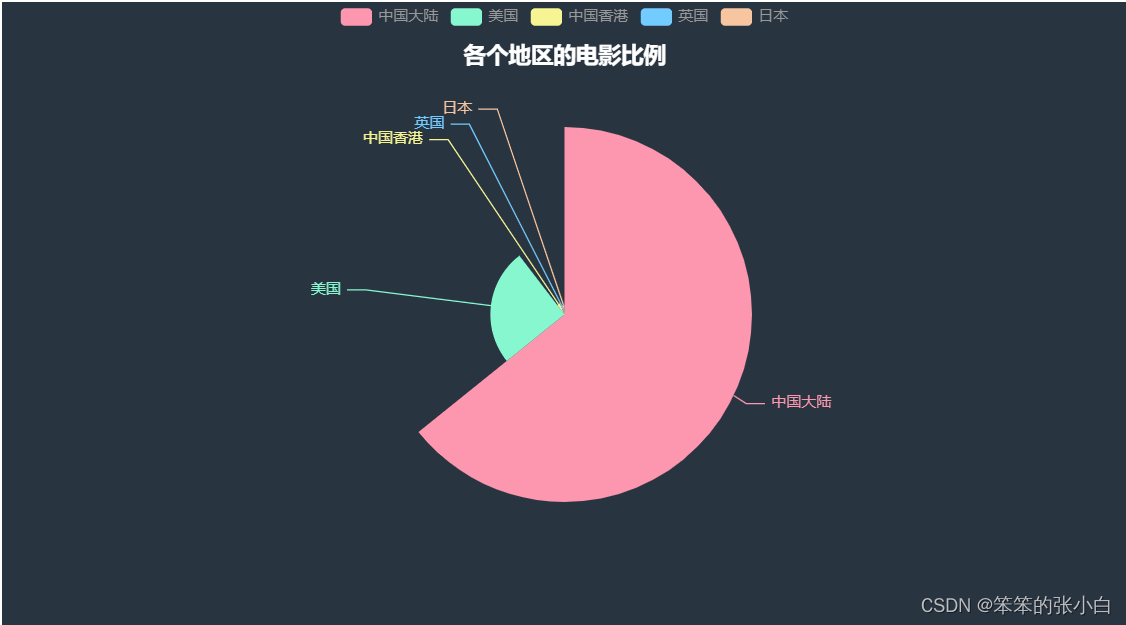
# 分析拍电影数前五的发行公司
df4 = data['发行公司'].value_counts().head().plot(kind='barh') 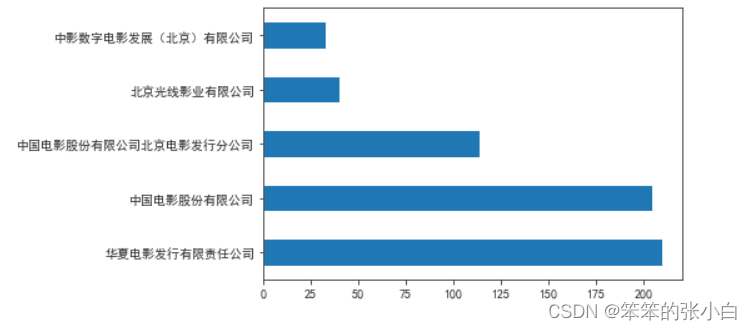
# 分析片长和评分的关系
plt.figure(figsize=(10,8))
plt.scatter(data['片长'],data['评分'])
plt.title('片长和评分的关系',fontsize=15)
plt.xlabel('片长',fontsize=15)
plt.ylabel('评分',fontsize=15)
plt.show() 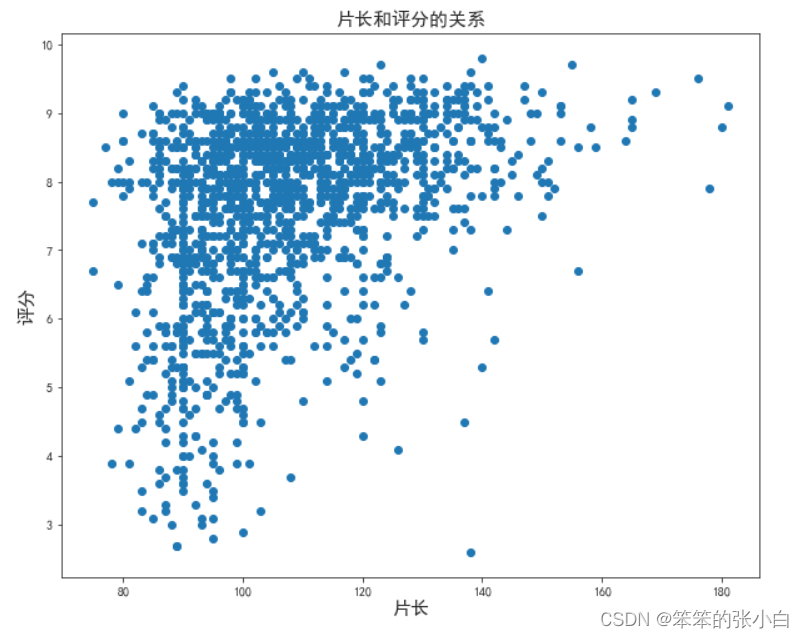
# 分析各个特征之间的相关系数
fig = plt.figure(figsize=(18,18))
sns.heatmap(data.corr(),vmax=1,annot=True,linewidths=0.5,cbar=False,cmap='YlGnBu',annot_kws={'fontsize':25})
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.title('各个特征之间的相关系数',fontsize=20)
plt.show()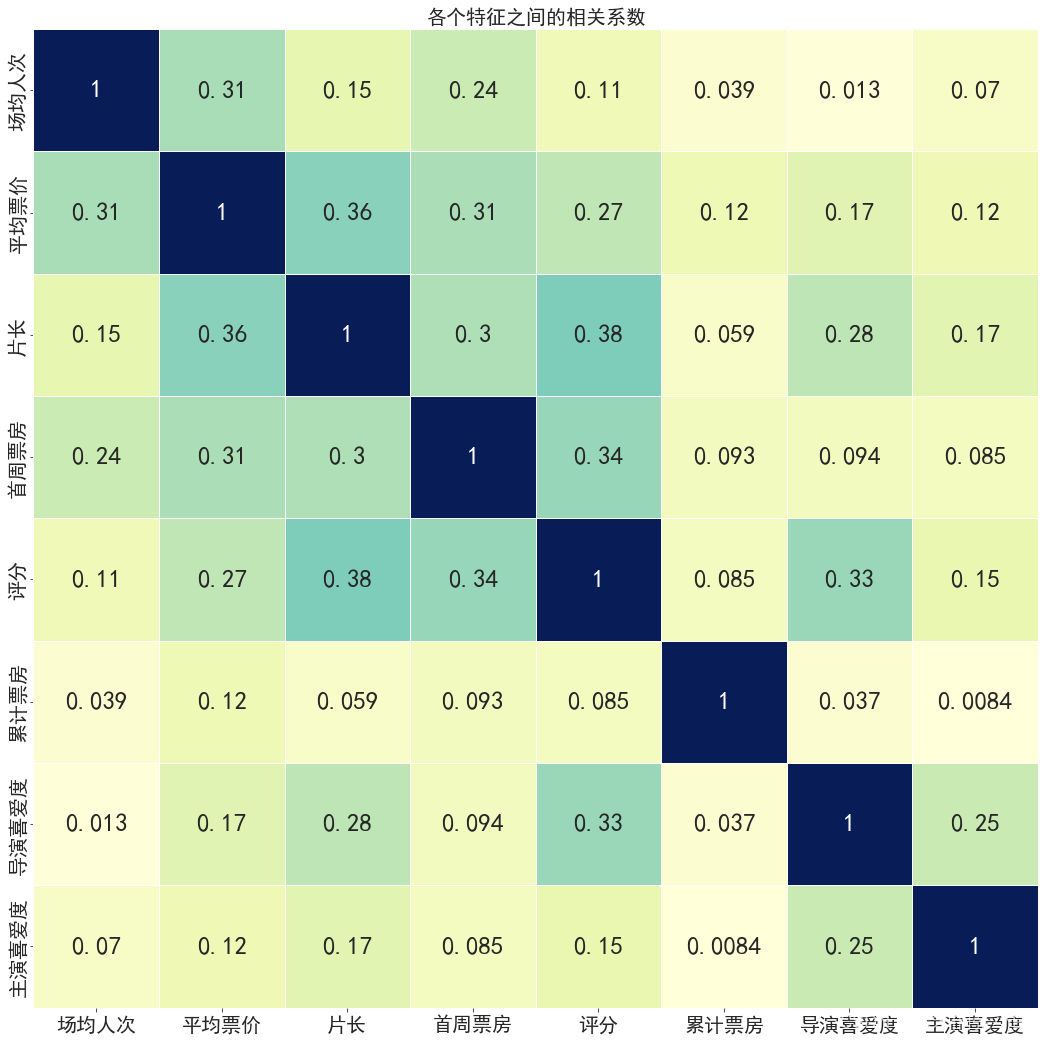
# 分析年度总票房走势
df1 = data.groupby('年份').sum()['累计票房']
plt.figure(figsize=(10,8))
plt.title('年度总票房走势',fontsize=14)
plt.xlabel('年份',fontsize=14)
plt.ylabel('总票房(万元)',fontsize=14)
plt.plot(df1.index,df1.values)
plt.show()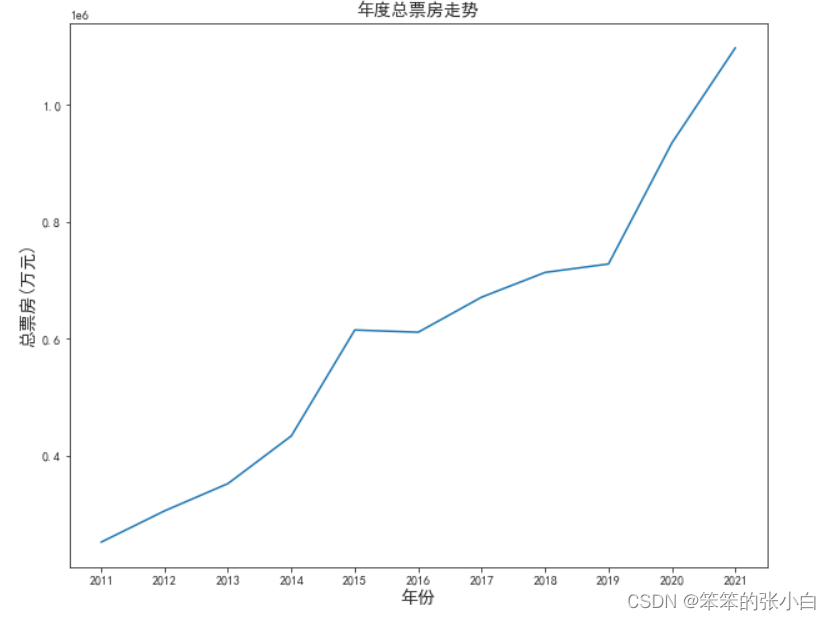
# 分析哪种制片制式最受欢迎
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['制片制式'].values:
word_list = str(i).split('/')
for j in word_list:
result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
word_counts_top = word_counts.most_common(50)
print(word_counts_top)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook() 
# 分析各种制式制片的比例
a2 = Pie(init_opts=opts.InitOpts(theme = ThemeType.CHALK))
a2.add(series_name='类型',
data_pair=word_counts_top,
radius='60%',
)
a2.set_global_opts(title_opts=opts.TitleOpts(title="各种制式制片的比例",
pos_top=50))
a2.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a2.render_notebook() 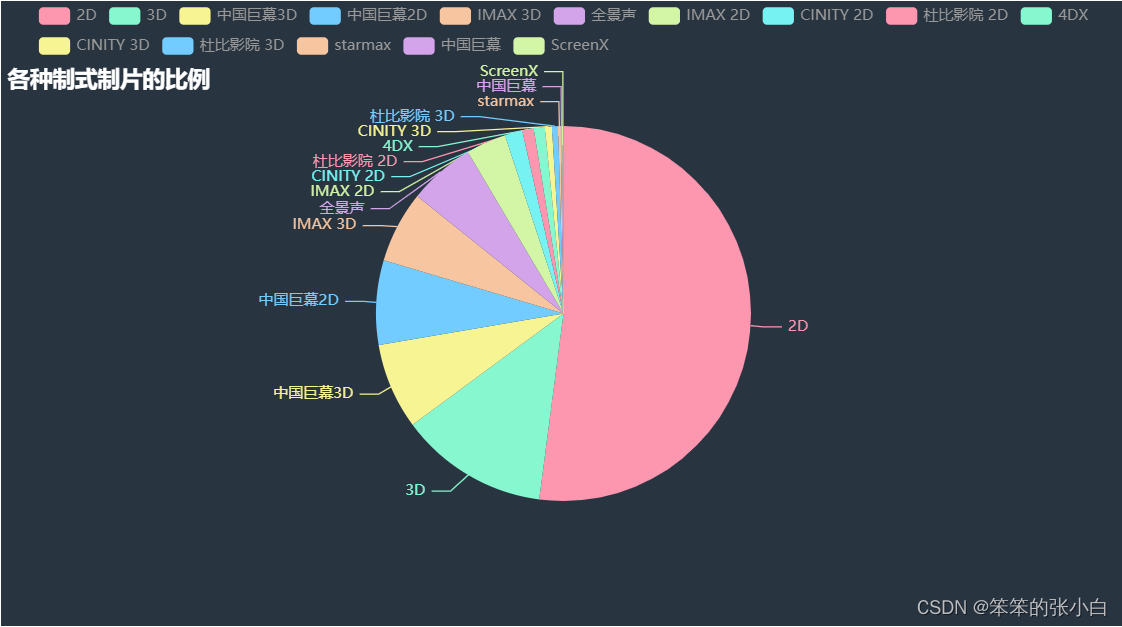
# 分析各种类型的电影出现的次数
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['电影类型'].values:
word_list = str(i).split(' / ')
for j in word_list:
result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
print(word_counts_top)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook() 
# 分析各种类型电影的比例
word_counts_top = word_counts.most_common(10)
a3 = Pie(init_opts=opts.InitOpts(theme = ThemeType.MACARONS))
a3.add(series_name='类型',
data_pair=word_counts_top,
rosetype='radius',
radius='60%',
)
a3.set_global_opts(title_opts=opts.TitleOpts(title="各种类型电影的比例",
pos_left='center',
pos_top=50))
a3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a3.render_notebook()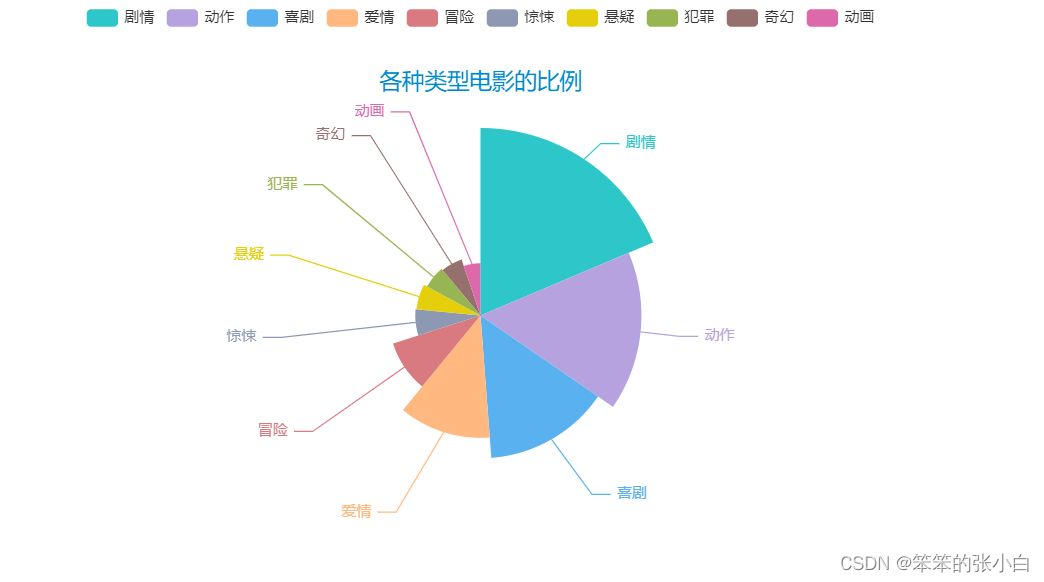
以下是心得体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
相关文章
- CPU:别再拿我当搬砖工!一个故事看懂零拷贝技术
- 比尔.盖茨:TikTok的美国数据将获得微软的安全保证
- 收购TikTok,对微软有什么意义?
- React 中请求远程数据的四种方法
- 《麻省理工科技评论》2020年“全球十大突破性技术”,18位顶级专家联手深度解读
- 别再用数据库生成的ID了
- 集合啦,NLP数据增强技术!超全资源汇总
- 4个常用的查询函数都不掌握,那就真的Out了
- 首次曝光的计算模型!对标阿里?有没有想过你的中台只是废纸?
- HTTP/3 来了 !未来可期
- 数据科学家小贴士:10个优秀的可视化工具
- 聊天机器人是如何通过知识图谱回答问题的?
- 一言难尽,Jpa这个功能差点让我丢了工作
- 无代码的未来?
- 探索自然本源!谷歌2022年终总结第七弹:「生化环材」如何吃上机器学习红利?
- 一文通览自动驾驶三大主流芯片架构
- 国内外顶尖高校联合发布首个「新冠NLP数据集」METS-CoV|NeurIPS 2022
- 抖音超900万人在用的「卡通脸」特效技术揭秘
- 为什么所有GPT-3复现都失败了?使用ChatGPT你应该知道这些
- 开挖扩散模型小动作,生成图像几乎原版复制训练数据,隐私要暴露了