
SE注意力机制
简介
SENet是2017年ImageNet比赛的冠军,2018年CVPR引用量第一。论文链接:SENet
意义
较早的将attention引入到CNN中,模块化化设计。
目的:
SE模块的目的是想通过一个权重矩阵,从通道域的角度赋予图像不同位置不同的权重,得到更重要的特征信息。
主要操作
SE模块的主要操作:挤压(Squeeze)、激励(Excitation)
算法流程图
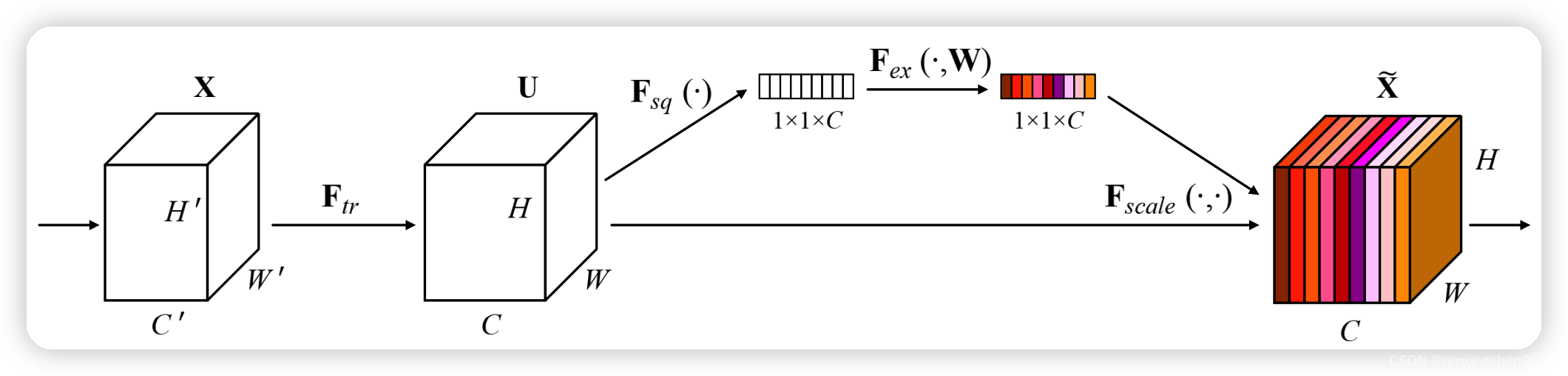
通过一系列操作得到一个
1
∗
1
∗
C
1*1*C
1∗1∗C的权重矩阵,对原特征进行重构(不同颜色表示不同的数值,用来衡量通道的重要性)
过程
第一步、
Transformation
(
F
t
r
)
(F{_t}{_r})
(Ftr):给定一个input特征图
X
X
X,让其经过
F
t
r
F{_t}{_r}
Ftr操作生成特征图
U
U
U。
注意:在常用的卷积神经网络中Transformation操作一般为一个卷积操作。我们通常在聊SE注意力时通常不包含这一步。
第二步、
Squeeze
(
F
s
q
(
⋅
)
)
(F{_s}{_q}(·))
(Fsq(⋅))::这一步将特征图进行全局平均池化,生成一个
1
∗
1
∗
C
1*1*C
1∗1∗C的向量,这样每个通道让一个数值表示。
注释:对
U
U
U实现全局低维嵌入,相当于一个数值拥有该通道的全局感受野。
公式: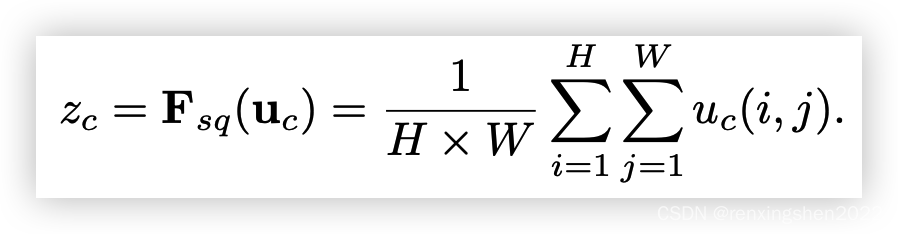
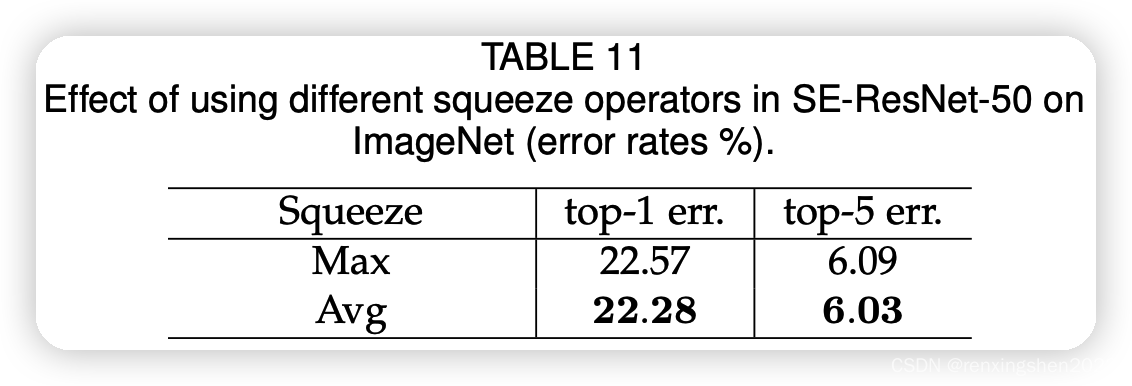
此外:论文中给出了使用平均池化与最大池化的实验对比。
第三步、
Excitation
(
F
e
x
)
(F{_e}{_x})
(Fex):这一步通过两层全连接层完成,通过权重W生成我们我所要的权重信息,其中W是通过学习得到的,用来显示的建模我们我需要的特征相关性。
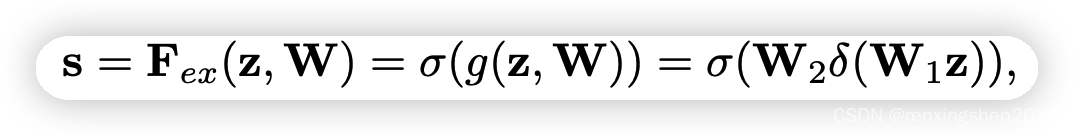
通过两个全连接层
W
1
W{_1}
W1 ,
W
2
W{_2}
W2对上一步得到的向量
z
z
z进行处理,得到我们想要的通道权重值
s
s
s,经过两层全连接层后,s中不同的数值表示不同通道的权重信息,赋予通道不同的权重。
注意:两层全连接层之间存在一个超参数
R
R
R, 向量
z
z
z
(
1
∗
1
∗
C
)
(1*1*C)
(1∗1∗C)经过第一层全连接层后维度由
(
1
∗
1
∗
C
)
(1*1*C)
(1∗1∗C)变为
(
1
∗
1
∗
C
/
R
)
(1*1*C/R)
(1∗1∗C/R),再经过第二层全连接层为度由
(
1
∗
1
∗
C
/
R
)
(1*1*C/R)
(1∗1∗C/R)变为
(
1
∗
1
∗
C
)
(1*1*C)
(1∗1∗C)。第一层全连接层的激活函数为ReLU,第二层全连接层的激活函数为Sigmoid。
第四步、
Scale
(
F
s
c
a
l
e
)
(F{_{scale}})
(Fscale):由算法流程图可以看出,第四步的操作是将第三步生成权重向量
s
s
s对特征图
U
U
U进行权重赋值,得到我们想要的特征图
X
~
ilde X
X~,其尺寸大小与特征图
U
U
U完全一样,SE模块不改变特征图的小大。
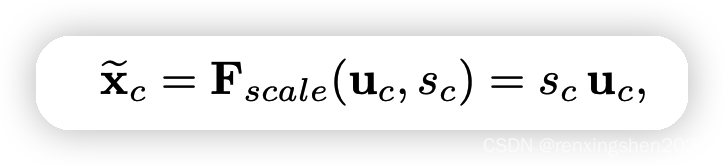
通过生成的特征向量
s
s
s(
1
∗
1
∗
C
1*1*C
1∗1∗C)与特征图
U
U
U(
H
∗
W
∗
C
H*W*C
H∗W∗C),对应通道相乘,即特征图
U
U
U中每个通道的
H
∗
W
H*W
H∗W个数值都乘
s
s
s中对应通道的权值。
SE模块的结构图
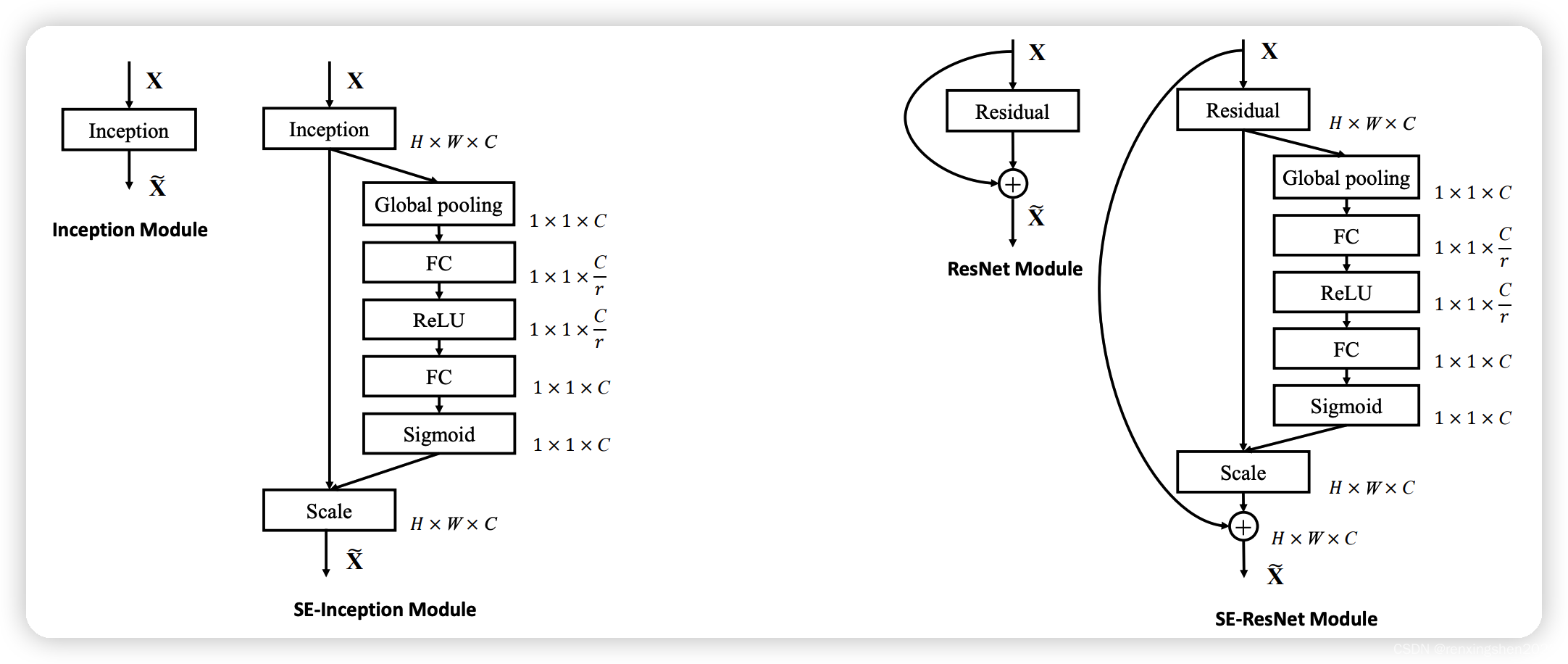
SE模块是一个即插即用的模块,在上图中左边是在一个卷积模块之后直接插入SE模块,右边是在ResNet结构中添加了SE模块。
实现代码
import torch.nn as nn
class SEModel(nn.Module):
def __init__(self, channel, reduction=16):
super(SEModel, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
网上有较多的公开代码,都可以进行参考。
最后
SE模块在使用时如何选择添加的位置是值得考虑的问题,如何实现最大化的提升。
MobileNetV3中使用了SE模块,通过神经网络架构搜索进行了最优位置选择,值得思考与学习。
如有错误,望大家指正。B站上有很多大佬的讲解视频,喜欢视频讲解的可以看一下。
相关文章
- 用MiniPC搭建个人服务器
- 京东支付研发负责人唐志雄:多角度谈京东白条
- 七个改变我生活的 Git 小技巧
- 数据湖前途未卜?
- 数据分析思想指南
- Fedora 35 或将支持自适应最优加密扇区大小
- Linux编程说明书 - Man
- Linux开发者讨论建立跟踪块/磁盘运作的全局计数器
- Github团队协作之Pull请求
- “网络爬虫+相似矩阵”技术运作流程
- Windows 11不支持移动任务栏位置 用户集体请愿微软收回成命
- 哈佛商评:数据是内容营销的下一大热门话题
- 微软:Windows 11 将支持后台无缝累积更新,比 Windows 10 更优雅
- 说一说 Linux 进程控制
- 外媒:微软 Windows11 配置要求太高,利好 Linux 发行版
- 数据安全:从网易邮箱被爆看互联网企业的网络安全
- 微软 Windows 11,20 多年来首个没有 IE 浏览器的 Windows 版本
- MIT做了一个全自动的大数据分析系统
- 在Linux下写一个自己的命令
- Windows 11,一个新功能,一场新屠杀!