
谷歌大脑最新操作玩“复古”:不用卷积注意力,图像分类接近SOTA
2023-04-18 14:11:23 时间
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
谷歌大脑的视觉Transformer团队(ViT),搞了个复古操作。
他们不用卷积神经网络(CNN)、也不用Transformer,仅凭最早的AI视觉任务采用的多层感知机(MLP)结构,就实现了接近SOTA的性能,更是在ImageNet图像分类任务上取得了87.94%的准确率。
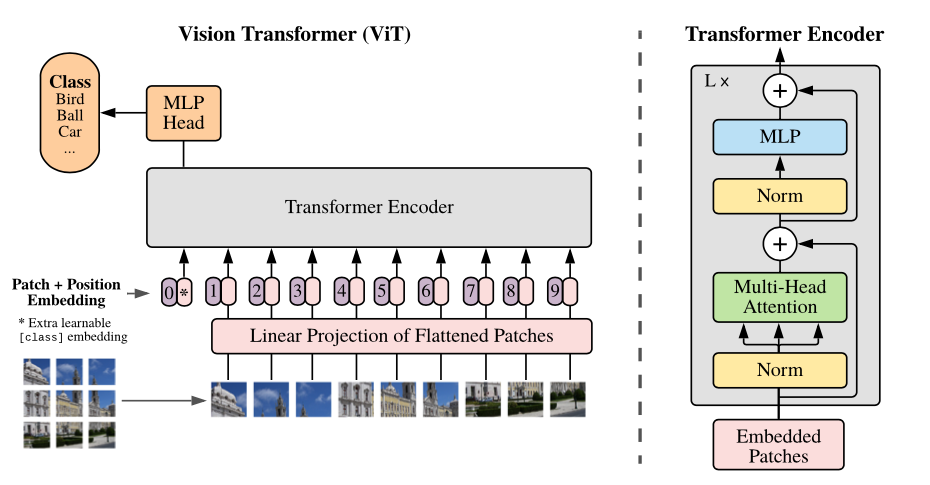
这个架构名为MLP-Mixer,采用两种不同类型的MLP层,可以看做是一个特殊的CNN,使用 1×1卷积进行通道混合(按位操作),同时全感受野和参数共享的的单通道深度卷积进行字符混合(跨位操作)。
在JFT-300M数据集上预训练、微调到224分辨率的Mixer-H/14版本取得了86.32%的准确率,比SOTA模型ViT-H/14仅低0.3%,但运行速度是其2.2倍。
论文地址:
https://arxiv.org/abs/2105.01601
项目地址:
https://github.com/google-research/vision_transformer/tree/linen

相关文章
- 【技术种草】cdn+轻量服务器+hugo=让博客“云原生”一下
- CLB运维&运营最佳实践 ---访问日志大洞察
- vnc方式登陆服务器
- 轻松学排序算法:眼睛直观感受几种常用排序算法
- 十二个经典的大数据项目
- 为什么使用 CDN 内容分发网络?
- 大数据——大数据默认端口号列表
- Weld 1.1.5.Final,JSR-299 的框架
- JavaFX 2012:彻底开源
- 提升as3程序性能的十大要点
- 通过凸面几何学进行独立于边际的在线多类学习
- 利用行动影响的规律性和部分已知的模型进行离线强化学习
- ModelLight:基于模型的交通信号控制的元强化学习
- 浅谈Visual Source Safe项目分支
- 基于先验知识的递归卡尔曼滤波的代理人联合状态和输入估计
- 结合网络结构和非线性恢复来提高声誉评估的性能
- 最佳实践丨云开发CloudBase多环境管理实践
- TimeVAE:用于生成多变量时间序列的变异自动编码器
- 具有线性阈值激活的神经网络:结构和算法
- 内网渗透之横向移动 -- 从域外向域内进行密码喷洒攻击