
Rta 广告投放技术实现及 SaaS 化思考

RTA背景
RTA这种投放模式这两年逐渐兴起, 目前国内主流的流量媒体方都推出该项能力。如腾讯/头条在2020年正式对外推出该项服务,以此来帮助客户进一步提升广告的精准投放效果。
RTA(全称Real-Time API),实时API接口,是媒体和广告主之间通信的一套接口服务。主要流程如下:
- 在开通后在每次媒体将广告给用户曝光前,媒体将通过RTA接口来询问广告主是否参与本次曝光(参竞);
- 广告主接受请求后结合自身的数据和策略信息返回是否进行曝光(参竞)以及进一步的决策结果;
- 媒体结合广告主的结果信息进行优选,最终提升广告主的广告投放效果。
RTA有很多业务上的价值,比如可以针对场景做个性化的优选,也让广告主有了参与广告曝光决策的机会。
对于大部分客户来说自身的私有数据是非常珍贵的,RTA能很好的保护私有数据。通常情况下广告主想进行流量的筛选比如想圈定或者排除某一部分人群,常规做法是打包一些定向数据上传给媒体的DMP平台作为定向投放数据包。该方式下数据无法实时更新、而且操作繁琐,最重要的是还会将广告主的数据直接暴露给媒体方。很多时候,数据是一个公司非常重要的资产尤其对数据比较敏感的金融行业,某些数据不方便提供出去,RTA能很好地解决该类问题。
RTA接入要求
虽然RTA业务价值很明显,但媒体对可以接入RTA的广告主设有不小的门槛,这里我们主要讨论的是技术上的门槛。
因为要进行实时的参竞,媒体要求广告主方有一定的技术和数据能力,亦即面对高并发的流量时能快速作出决策进行实时答复。下面列举了头条要求广告主方必须达到的硬性技术指标:
- 接口响应时间在60ms内(包括网络和处理时间)
- 超时率要低于2%
- 预计高点流量可达10w/s~12w/s
其他媒体比如腾讯、快手、百度等的要求类似,接口的响应时间都要在60ms内,需要能支持高QPS。根据业务场景投放的不同,实际的流量上限会有所不同。但通常媒体方一侧都设有超时率门槛,针对不达标的情况媒体方会有降级和最终的清退机制(即关闭广告主的RTA接入通道)
ToB RTA 的业务场景
通过上面对RTA背景的了解,知道了RTA在精准营销及私有数据不外泄方面有不错的表现。但是RTA的接入门槛比较高,对于一些体量较小的公司,大部分不具备技术接入的能力。而且对于和营销SaaS平台的合作,一般采用和SaaS服务提供商联合建模的方式合作,对于私有数据并不是特别敏感。通常的实现方式是:
- 广告主在营销SaaS供应商侧上传人群包,由SaaS供应商提供人群分析及RTA接口实现。
- 广告主在媒体侧开通账号,设置竞价相关的信息。把SaaS供应RTA接口作为一个策略进行配置。
RTA实现
API接口数据交换格式是基于http-protobuf,腾讯/头条 均采用该方式,protobuf序列化可以获得不错的压缩性价比,契约由媒体方提供,按照契约进行开发提供接口服务。这个还是比较简单的。
数据存储的选型
对于数据存储的选型上,这种场景下其实纯内存的数据库是最合适的,但是应用实现也需要权衡。考虑到公司基建的完善程度,在Hbase,aerospike 中进行选择,首先Hbase是不行的,因为Hbase 最坏的情况下可能会有秒级延迟。但是对于kv这种存储类型,在v 比较小情况下,aerospike的磁盘利用率很低。考虑到使用云厂商提供的kv 数据库,但是被安全进行否决,数据安全高于一切啊!!!
最终,采用了自建redis cluster 作为数据存储层。
应用架构实现原则
基于RTA高并发且实时的业务要求,我们在前期和安全/运维/DBA/基础组件的同学沟通,确保该并发的条件下我们的基础设施可以有效地承载,同时在一些设施上面进行有效的资源隔离,以防止RTA影响到其他业务。
综合考量后,我们作出如下的选择和主要设计原则:
- 机房隔离:由于公司大部分业务在杭州机房,为了保证有效隔离,RTA应用部署在上海机房。
- 避免阻塞/耗时操作:可采用异步化手段;对于那些需要降低下游QPS的地方,可采用队列、缓存、批量操作等手段来进行优化
- 超时降级:对于部分请求可能产生毛刺,从而导致超时带来的雪崩以及带宽的阻塞,必须对超时请求进行降级处理。
- 资源保护/细节优化:比如跨系统边界的调用、有风险的本地代码块等,都可当成资源进行保护并提供有效的降级机制.通过优化代码,通过方法内联降低调用成本。
系统视图
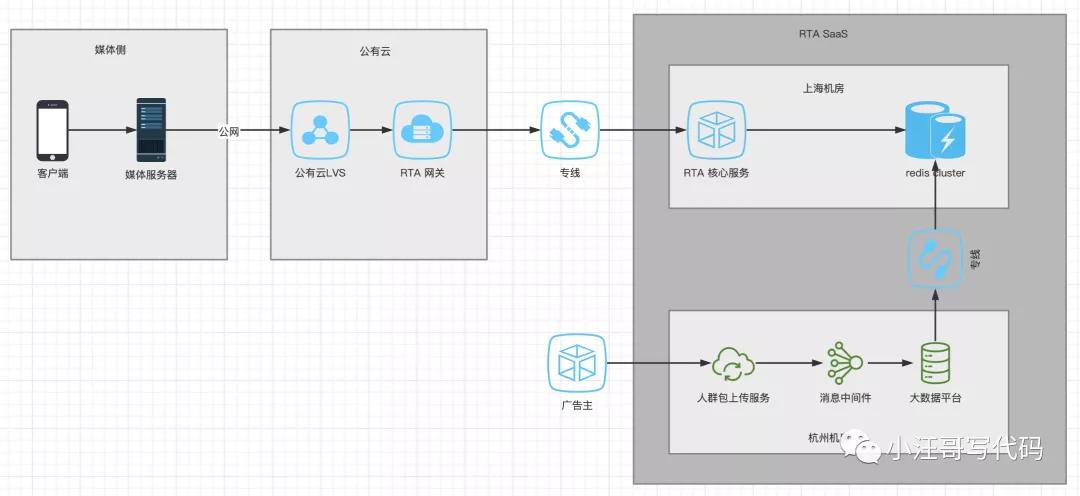
主要有一下几个服务:
- rta-uig:前置接收请求,并对后端应用做负载均衡。
- config:分布式配置中心,业务人员对每个RTA请求是否曝光(参竞)制订策略,数据变更通知。
- rtaapp:rta 核心服务,缓存客户配置信息,处理请求,返回参竞数据。
- data-trans:广告主数据处理和定时将数据同步到redis cluster。
下面是API接口的主要处理流程:

为保证HTTP的线程不阻塞,尽可能优先采用异步处理方式。而且API直接依赖的2个数据源是Redis和JVM内存,这样可以满足实时性的要求。
网络问题
我们上面提到接口的响应时间要在60ms以内,因此网络的问题影响很大。
事实上我们的时间大部分花费在网络上,距离的远近直接影响着网络时延。以目前对接的一些媒体来看,在接口消耗时间上,北京到上海大概30ms左右,上海公有云到公司机房的专线大概要2ms。在上线后,当媒体方请求量增大时,由于网络抖动导致tcp重传,从而导致带宽被瞬间打满,所有的请求都被拒绝,在更换更大带宽的设备后,问题得到缓解,但是带宽成本是非常昂贵的。后期希望和安全部门协商,看看能不能把数据的安全等级进行分类,部分数据可以上公有云,这样可以将数据部署里媒体侧机房更近的地方。
资源保护
对资源进行保护和有效降级非常重要。保护点主要基于业务上考虑来确定,可以是任意的代码片段,并尽可能提供降级手段,以保证我们的主业务不受影响。如果依赖的下游服务宕机或者GC的导致进程暂停,必须对请求进行超时降级。对应海量请求的超时处理,可以借鉴时间轮的原理,把时间复杂度控制在O(1),大幅提升性能,具体可以参考我前面的文章。
RTA SaaS化的思考
随着业务的发展,接入客户的增多,产品SaaS化是一个趋势,SaaS化必然面临着多租户数据之间的隔离,数据量的快速增长,怎么来处理这些事情,降本增效,利用少量的资源做更多的事情,各种性能指标也能达标,是一个值得思考的问题。
Redis 内存方面
对于使用Redis存储的业务数据,结合业务上的数据特点,可以使用hash/zset存储结构,限制key 的数量长度,使用ziplist,省下了大部分内存,节约了成本。采用二级编码的方式。整体上采用hash存储后,查询100万条耗时,也仅仅增加了500毫秒不到。具体可以看我之前的文章。
在后面的需求中,要对曝光的设备做一些策略,限制媒体每个设备每日到达多少量后不再进行曝光,这依赖于对设备进行计数。后面会对接多个媒体,总设备曝光请求数据每日可能高达上百亿次,预计每日会有数十亿的去重设备量。结合业务上的的特点,设计如下:
- 设备有并发,所以一定要原子操作,只能选择INCR命令(string、hash、zset)。
- 媒体设备分别计数,每日每个媒体计数业务规则上有上限(每日10次以内)。这意味着每个计数器可能达到的最大计数值是确定的,亦即计数器所需的位数是有限的、固定的。
例如Redis中对于整数类型采用的内部编码是int编码,对应Java里的long类型,占8个字节。可以将一个8字节拆开,取合适的bit数量作为某个媒体计数,结合hash存储后还可以获得数倍的空间节省。
热点数据的优化
由于业务上的特点,我们会面临大量的数据存储需求,业务上一个很小的规则可能会使用很大的存储资源。这要求我们谨慎设计数据存储,寻找有效的存取结构。
业务上用的数据,可以归结为如下2类存储:
- JVM本地存储:系统业务配置、业务规则策略、业务的控制信息、热KEY和黑名单等
- Redis存储:策略计算需要很多不同的数据,数据量比较大,每份数据以亿计
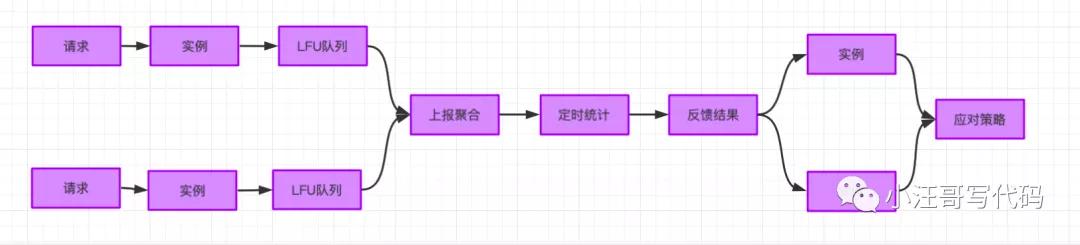
对于JVM本地存储,以对热key的处理为例进行说明。热key是指同一个设备号的曝光请求被媒体反复下发。在业务上线的初期,我们发现很多设备请求被下发很多次,有的每日可达上千万次,浪费了处理资源,需要某种策略进行应对。为此,我们设计了收集反馈的方式,具体流程:API实例本地LFU队列【LFU(Least Frequently Used) 算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。】收集 -> 上报 -> 统计 -> 反馈到API实例,如下图所示:
总结
RAT已经正常运行了一段时间,在运行中也发现了一些问题,目前来看系统运行比较稳定,等到模型效果验证后可以开始SaaS化演进,从这次项目推动的过程中,可以发现,应用机房的选择非常重要,数据部署最好和媒体侧机房不要间隔太远;接口的设计方面,尽量简约,对于不必要返回的字段和响应头,尽量去掉,节约带宽(带宽比较贵);数据存储方面,使用内存型数据库,研究存储类型的数据结构,利用合理的数据结构节约存储成本;做好接口超时降级处理,利用高效的超时判断机制,尽量少的减少对应用性能的损耗。
本文转载自微信公众号「小汪哥写代码」,可以通过以下二维码关注。转载本文请联系小汪哥写代码公众号。

相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!