
[机器学习] 分类算法朴素贝叶斯算法
朴素贝叶斯算法是来利用统计学中的条件概率来进行分类的一种算法。贝叶斯定理和特征条件独立假设就是朴素贝叶斯的两个重要理论基础。
贝叶斯定理
贝叶斯定理如下:

因此上述的公式可以变为


朴素贝叶斯计算
P(B)计算公式如下,由公式可知P(B)为标准化常量,因此P(B)在朴素贝叶斯概率计算中可以省略。因为朴素贝叶斯算法是分类算法,通过比较各个情况发生下的概率的大小,来确定最后的分类,去掉P(B)不影响最后结果。
$$P(B)=sum_{i=1}^{n}P(x|D_{i})P(D_{i})$$又因为朴素贝叶斯算法对条件概率分布作出了独立性的假设。即(x_{1},x_{2},...,x_{n})相互独立则
$$P(x|D_{j})=P(x_{1},x_{2},...,x_{n}|D_{j})=prod_{i=1}^{n}P(x_{i}|D_{j})$$因此朴素贝叶斯算法的分类函数(f(x))可以表示为
$$f(x)=P(D_{j}|x)=argmax P(D_{j})prod_{i=1}^{n}P(x_{i}|D_{j})$$关于朴素贝叶斯分类,根据(P(x_{i}|y_{k}),P(y_{k}))的不同计算方法,sklearn库中主要以下三种计算模型:
- 高斯朴素贝叶斯,主要基于高斯概率密度公式用于分类拟合
- 多项式朴素贝叶斯,主要用于高维度向量分类
- 伯努利朴素贝叶斯,主要针对布尔型类型进行分类
高斯朴素贝叶斯计算
当特征X是连续变量的时候,通常假定所有特征取值符合正态分布。用高斯朴素贝叶斯计算概率,即:
$$P(x_{i}|D_{j})=frac{1}{sqrt{2pisigma_{{j,k}}^{2}}}e^{-frac{(x_{i}-mu_{{j,k}})^{2}}{2 sigma_{{j,k}}^{2}}}$$
例如下表为一组人类身体特征统计表:
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
已知某人身高6英尺,体重130磅,脚掌8英寸,请问该人是男是女。
根据前面的朴素贝叶斯分类公式,有:
f(x)=P(性别)x P(身高,体重,脚掌|性别) = P(性别) x P(身高|性别) x P(体重|性别) x P(脚掌|性别)
由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。
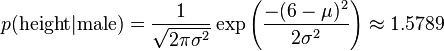
例如:
P(男) x P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男)
= 0.5 x 1.57888 x 5.99 x e-6x 0.001311 = 6.1984 x e-9 P(女) x P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) = 5.3778 x e-4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
sklearn中对应的函数为GaussianNB(),代码如下
import numpy as np
from sklearn.naive_bayes import GaussianNB
X = np.array([[6 , 5.92, 5.58, 5.92, 5, 5.5, 5.42, 5.75],
[180, 190, 170, 165, 100, 150, 130, 150],
[12, 11, 12, 10, 6, 8, 7, 9]])
X = X.T
y = np.array([-1, -1, -1, -1, 1, 1, 1, 1]) #-1表示男,1表示女
clf = GaussianNB().fit(X, y)
#预测
p = [[6, 130, 8]]
print(clf.predict_proba(p)) #输出各个标签的概率值,取最大的概率值为输出标签
print(clf.predict(p)) #结果为1函数其他参数改动可参考官网文档:
多项式模型
$$P(D_{j})=frac{N_{D_{j}}+alpha}{N+kalpha}$$
N是总样本个数,k是类别D中总的类别个数(j=[1, k]),(N_{D_{j}})为(D_{j})的样本个数,(alpha)为平滑值,(alpha=[0, 1])
$$P(x_{i}|D_{j})=frac{N_{D_{j},x_{i}}+alpha}{N_{D_{j}}+(n_{x_{i}})alpha}$$
(n_{x_{i}})是特征x的维数,(N_{D_{j},x_{i}})是类别为(N_{D_{j}})的样本中,第i维特征的值为(x_{i})的样本个数.
sklearn中对应的函数为MultinomialNB,类似于GaussianNB()。代码如下
clf = MultinomialNB().fit(X, y)函数其他参数改动可参考官网文档:
伯努利模型
伯努利模型基于以下公式:
当(x_{i}=1),(P(x_{i}|D_{j})=P(x_{i}=1|D_{j}))
当(x_{i}=0),(P(x_{i}|D_{j})=1-P(x_{i}=1|D_{j}))
其中(x_{i})只能为0或者-1。
sklearn中对应的函数为BernoulliNB,类似于GaussianNB()。代码如下
from sklearn.naive_bayes import BernoulliNB
import numpy as np
X = np.random.randint(2, size=(6, 100))
Y = np.array([1, 2, 3, 4, 4, 5])
clf = BernoulliNB().fit(X, Y)
p = [X[2]]
print(clf.predict(p)) #[3]
函数其他参数改动可参考官网文档:
参考文献
相关文章
- 自动化的未来:2023年加速云的采用
- Aruba ESP推出云原生服务重大更新功能,为边缘到云网络的部署和保护实现自动化并加速运行
- 2022云原生安全发展的24个洞见
- 私有云与公共云:Kubernetes 如何改变平衡?
- 聊聊实时通信中的AI降噪技术
- 在DevOps中优化持续测试的最佳实践
- 关于光通信的进阶科普,你明白了吗?
- 人工智能机器人厨师:烹饪的未来?
- 研究人员表示,5G和6G网络将为应急人员和智慧城市项目提供助力
- 详解“开放云”的真正含义
- 如何正确选择多云架构?三要素缺一不可
- WiFi 6E虽然快 但你可能不需要它
- CloudOps: 一种优化云上运维的框架
- 语音助手好吗?好,但还不够好
- 构建元宇宙基座,为什么 CDN 技术必不可少?
- 微步在线TDP:99.97%准确率,高强度对抗下漏报率可以多低?
- 选择混合云还是多云?企业要考虑这些因素
- 关于IPv9那些事,你知道多少?
- 为什么需要 Kubernetes 准入控制器
- 从ServiceMesh服务网格到去中心化的SOA总线