
Storm、Spark和MapReduce 开源分布式计算系统框架比较

比较项 Storm Spark Streaming 分布式计算在许多领域都有广泛需求,目前流行的分布式计算框架主要有 Hadoop MapReduce, Spark Streaming, Storm; 这三个框架各有优势,现在都属于 Apache 基金会下的***项目,下文将对三个框架的特点与适用场景进行分析,以便开发者能快速选择适合自己的框架进行开发。
Hadoop MapReduce 是三者中出现最早,知名度***的分布式计算框架,最早由 Google Lab 开发,使用者遍布全球(Hadoop PoweredBy);主要适用于大批量的集群任务,由于是批量执行,故时效性偏低,原生支持 Java 语言开发 MapReduce ,其它语言需要使用到 Hadoop Streaming 来开发。Spark Streaming 保留了 Hadoop MapReduce 的优点,而且在时效性上有了很大提高,中间结果可以保存在内存中,从而对需要迭代计算和有较高时效性要求的系统提供了很好的支持,多用于能容忍小延时的推荐与计算系统。Storm 一开始就是为实时处理设计,因此在实时分析/性能监测等需要高时效性的领域广泛采用,而且它理论上支持所有语言,只需要少量代码即可完成适配器。
下面的表格是对三者部分特性的比较,描述时间为 2015-5-3,三个项目均处于快速迭代中,文中描述特性会随时产生变化,如果与官方文档产生出入以官方文档为准。
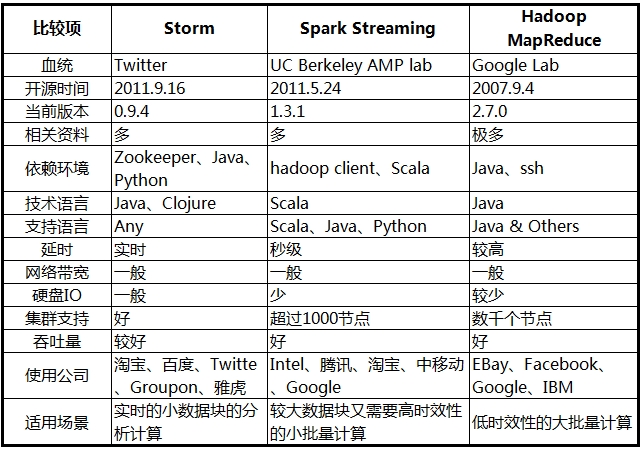
表格说明:
开源时间以 github 上最早的 commit 或者官网上最早发布版本的时间为准。
当前版本与特性描述截止 2015-5-3。
相关资料量通过比较官方文档、搜索引擎、论坛等途径得出。
部分比较数据来源于实践或相关文章(未找到出处)。
本文会保持更新,如果数据发现有出入,欢迎指正。
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!