
PyTorch分布式并行训练
2023-04-18 15:19:42 时间
目录
Pytorch分布式并行训练原理
PyTorch分布式训练采用数据并行架构。
分布式数据并行原理

- 每个rank都有一份模型的拷贝(一个rank就是进程),不同rank可以相同机器的不同GPU卡上,也可以分布在不同的机器上;
- 将数据的不同Batch的数据传给不同的rank;
- 每个rank执行forward pass;
- 每个rank执行backward pass,因为模型输入的数据不同,所以不同rank上的梯度不同;
- 通过
allreduce算法同步梯度,最终每个rank的梯度保持一致;
PyTorch分布式数据并行Demo
分布式数据并行训练Demo:
def ddp_demo(rank, world_size, accum_grad=4):
assert dist.is_gloo_available(), "Gloo is not available!"
print(f"world_size: {world_size}, rank: {rank}, is_gloo_available: {dist.is_gloo_available()}")
# 1. 初始化进程组
dist.init_process_group("gloo", world_size=world_size, rank=rank)
model = nn.Sequential(nn.Linear(10, 100), nn.ReLU(), nn.Linear(100, 20))
# 2. 分布式数据并行封装模型
ddp_model = DistributedDataParallel(model)
criterion = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=1e-3)
dataset = TensorDataset(torch.randn(1000, 10))
# 3. 数据并行
sampler = DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True)
dataloader = DataLoader(dataset=dataset, batch_size=24, sampler=sampler, collate_fn=transform)
for epoch in range(1):
for step, batch in enumerate(dataloader):
output = ddp_model(batch)
label = torch.rand_like(output)
if step % accum_grad == 0:
# 同步参数
context = contextlib.nullcontext
else:
# 4. 梯度累计,不同步参数
context = ddp_model.no_sync
with context():
time.sleep(random.random())
loss = criterion(output, label)
loss.backward()
if step % accum_grad == 0:
optimizer.step()
optimizer.zero_grad()
print(f"epoch: {epoch}, step: {step}, rank: {rank} update parameters.")
# 5. 销毁进程组上下文数据(一些全局变量)
dist.destroy_process_group()
本地没有Nvidia环境,使用
gloo替代nccl做通信后端。
PyTorch分布式训练Demo链接:https://gist.github.com/hotbaby/15950bbb43d052cd835b0f18c997f67c
模型转换成分布式训练步骤:
- 初始化进程组
dist.init_process_group("gloo", world_size=world_size, rank=rank); - 分布式数据并行封装模型
DistributedDataParallel(model); - 数据分布式并行,将数据分成
world_size份,根据rank采样DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True); - 训练过程中梯度累计,降低训练进程间的参数同步频率,提升通信效率【可选】;
- 销毁进程组
dist.destroy_process_group()。
PyTorch分布式数据并行内部设计
一个典型神经网络训练流程:
- 创建神经网络模型、定义目标函数和优化器;
- 迭代输入数据;
- 前向传播,计算loss;
- 反向传播,计算梯度;
- 根据梯度和学习率,更新参数
weight = weight - learning_rate * weight; - 重复2 ~ 5步骤。
分布式数据并行DDP通过嵌入到上述训练流程的不同阶段,实现训练加速:
- 初始化
- 进程组
ProcessGroup,解决rank间通信问题;
- 进程组
- 构建神经模型
- rank0参数广播给其他rank,保证所有模型副本的参数一致;
- 初始化
Reducer,用于后续反向传播阶段梯度累计和同步;
- 前向传播
require_forward_param_sync为True时,同步参数;
- 反向传播
- DDP通过注册
autograd hook注册梯度同步函数,调用Reducer的allreduce算法在rank间同步梯度;
- DDP通过注册
- 更新参数
PyTorch分布式数据并行源代码分析

图片来源:https://pytorch.org/docs/master/notes/ddp.html
distributed.py是分布式数据并行DDP Python程序入口,DistributedDataParallel封装了神经网络模型,重写了Module的forward()函数,调用底层C++库common.h接口同步模型参数,调用C++库reducer.h的allreduce实现梯度同步;common.h实现了broadcast_coalesced广播等工具函数;reducer.hReducer构造函数被distributed.py调用,注册了autograd_hook()函数实现梯度累计;autograd_hook()被PyTorch的自动微分引擎autograd engine调用;prepare_for_backward()被distributed.py的前向传播阶段调用;
ProcessGroup.hpp抽象了allreducer()、gather()、scatter()、broadcast()等接口,NCCL、Gloo等Backend实现了ProcessGroup.hpp定义的接口。
Ring AllReduce算法
为什么需要Ring AllReducer算法?
假设模型大小为128MB,网络带宽为1000Mb/s,8张GPU卡并行计算。一个训练step,rank0将参数同步到其他rank的时间是8秒,随着GPU数量的增长,参数同步的时间也线性增长,最终网络通信的时间抵消了GPU多卡训练时间,多卡训练加速不明显。
ring allreduce算法原理:
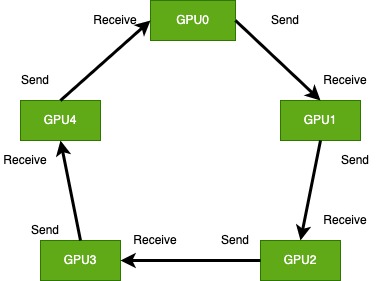
参考https://zhuanlan.zhihu.com/p/69797852
ring allreduce算法网络通信代价分析:
假设模型大小为M,GPU数量为N,在scatter-reducer和all-gather阶段,发送的数据大小为M/N,数据传输总量为2(N - 1)* M / N,数据通信总量是确定,不会随着GPU数量增长而增长。
参考文献
- PyTorch分布式数据并行官方文档【重要】
- PyTorch分布式数据并行概览
- PyTorch分布式数据并行后端
- PyTorch分布式集合通信
- Python实现ring allreduce算法
- 分布式训练allreduce算法
- ring allredue算法
- https://www.cnblogs.com/rossiXYZ/p/15172816.html
- https://www.autodl.com/docs/distributed_training/
- https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html
- https://dev-discuss.pytorch.org/t/torchdynamo-update-9-making-ddp-work-with-torchdynamo/860
相关文章
- 什么是AI边缘计算?边缘计算的好处在哪里?
- 得物客服机器人多轮SOP流程引擎技术实践
- 确保边缘计算成功的五个关键
- 从CDN到边缘计算 算力演进再次提速
- 聊聊LPWAN的发展趋势
- 英特尔发布从云到端的全新技术,让产业创新解决当前及未来挑战丨Intel Vision
- 东数西算,网络为先
- 深入浅出 Zookeeper 中的 ZAB 协议
- 十分钟讲完 QUIC 协议,你懂了吗?
- Soul智能语音技术实践之路
- 关于量子计算和人工智能应该了解的十件事
- 元宇宙如何“喂养”人工智能模型?
- 5G 与 WiFi 6 将如何影响关键传感器应用
- 从 IP 到 IP,聊聊计算机网络中那些“没用的”知识
- 一文读懂人工智能表:从MindsDB说起
- 边缘计算和5G:企业IT的下一步是什么?
- 无服务器计算或已成为云原生的下一个演进
- 5G 与边缘计算将占主导地位,但面临挑战
- 5G 和边缘:2022 年塑造计算的主要趋势
- 分布式云的工作原理及用例分析