
Kafka简单介绍和安装
2023-04-18 15:18:18 时间
1.什么是Kafka
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
**Kafka最新定义 **: Kafka是 一个开源的分布式事件流平台 (Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
目 前企业中比较常见的消息队列产品 要有Kafka、ActiveMQ 、RabbitMQ 、 RocketMQ 等。 在大数据场景主要采用 Kafka作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
2.KafKa安装
在官网下载Kafka,地址:https://kafka.apache.org/downloads
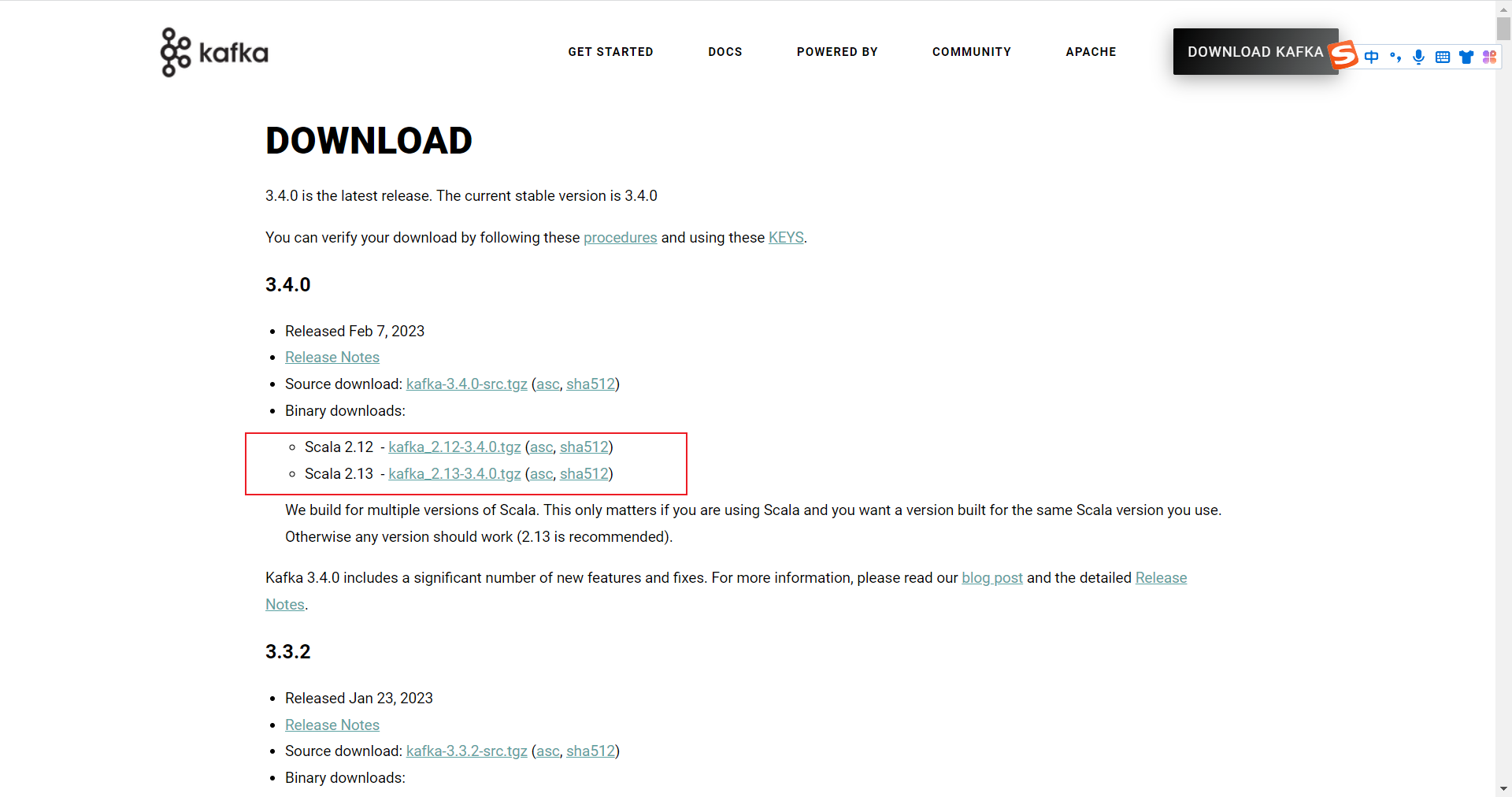
将安装包上传到服务器中,我习惯于将软件安装到/usr/local/目录中,将kafka压缩包上传至目录中,进行解压:
tar -zxvf kafka_2.12-3.0.0.tgz
#重命名
mv kafka_2.12-3.0.0 kafka
进入kafka目录查看

bin:主要是kafka的可执行文件,一些常用脚本,比如启动,关闭
config:主要存放配置文件
datas:我们自己新建的目录,主要用于存放kafka数据
libs:kafka依赖的一些文件
logs:日志
进入配置文件目录
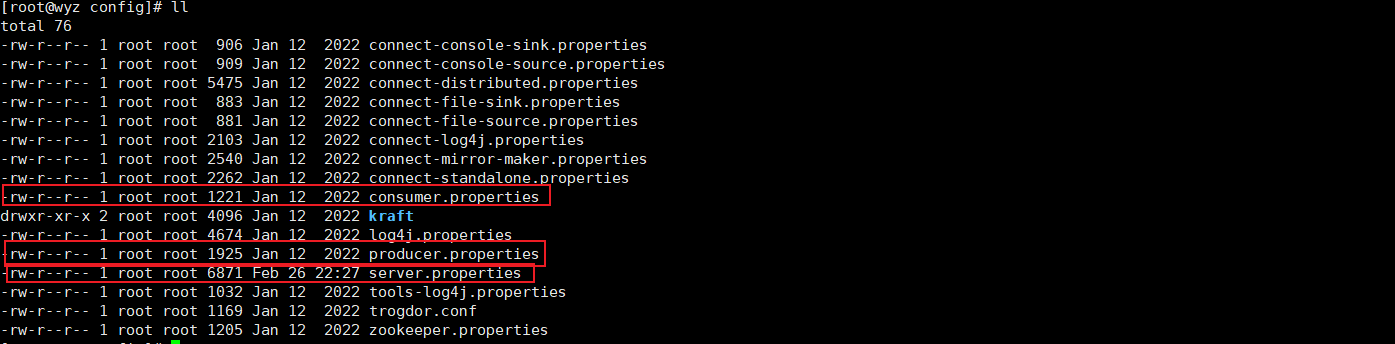
上面三个配置文件是我们关注的重点,我们先进入server.properties查看,进行第一次启动准备
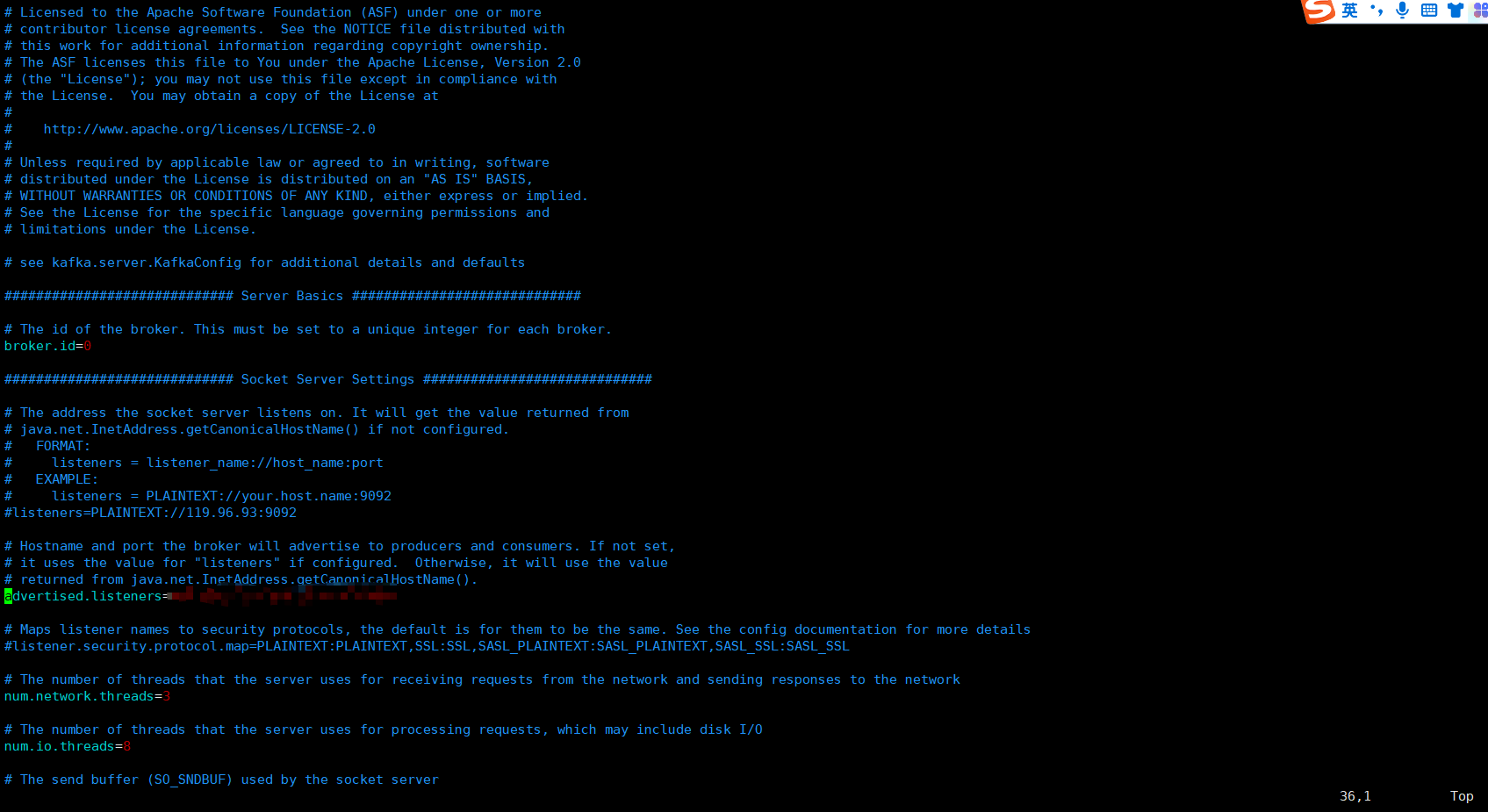
第一次主要进行几个配置的设置:
broker.id #broker 的全局唯一编号,不能重复,只能是数字
log.dirs=/usr/local/kafka/datas 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
zookeeper.connect#配置连接 Zookeeper 集群地址
启动:./bin/kafka-server-start.sh -daemon ./config/server.properties,使用jps查看

注意:启动之前,一定要先启动Zookeeper集群
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!