
Hadoop 2.0:大数据的新突破在即
不过这并不一定就是坏事。把 Hadoop 当作廉价有效的存储正好是 Hadoop 下一阶段演进的的完美起点。今年夏天就要亮相的 Hadoop 2.0 将会令数据仓库中的信息以及非结构化数据池前所未有地容易访问。
Hadoop大桶
自成为大数据工具以来,Hadoop 就是一个非常棒的数据存储系统,但是需要开发 Java 应用来访问数据的 MapReduce 学习起来却比较困难。
当然,还有别的办法可以从 Hadoop 中获取信息。Hbase数据是 Hadoop 的一部分,它可以让用户按照数据库范式来处理数据。Hive数据仓库则可以让你用类 SQL 的 HiveSQL 查询语言来创建查询并转化为 MapReduce 任务。不过 Hadoop 仍受限于单线程性。MapReduce 任务、Hive 查询、Hbase 操作,等等,这些都要轮流进行。
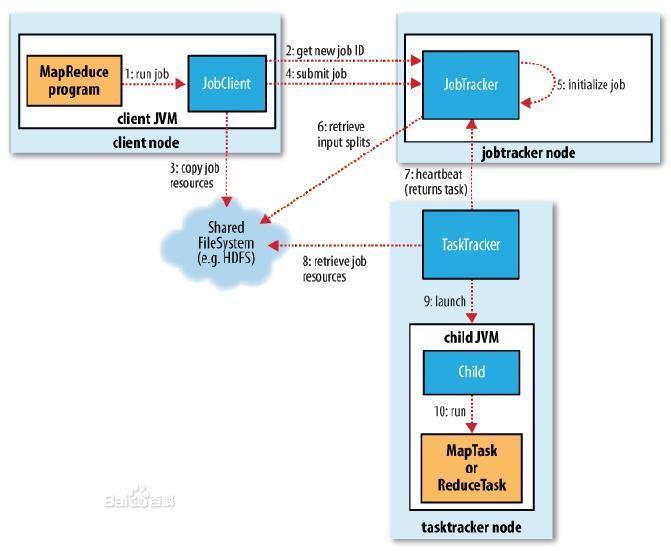
这就是许多大数据供应商倾向于仅将 Hadoop 当作数据容器的原因,为了提高效率,他们在此基础上再开发自己的工具来获取或分析其中的数据。尽管把 Hadoop 形容为一个大桶很形象,但是 Hadoop 用户当中已经有人把它看作是数据大湖甚至数据海洋了。不过光是规模大还是不行的,那些限制影响到了 Hadoop 的卖点。
Hadoop 的开发社区也意识到这个问题,随着 Hadoop 即将迭代到新的版本,上述限制即将在很大程度上被解除。
YARN解决方案
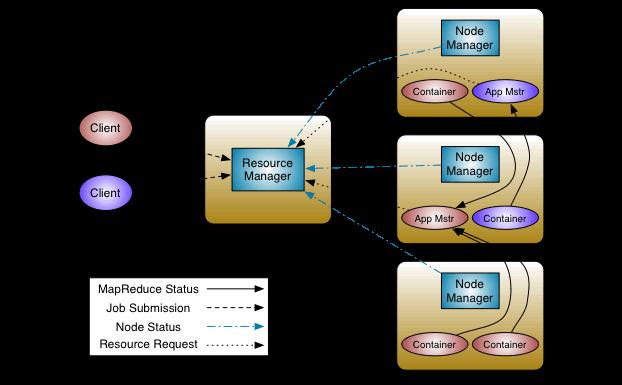
在 Hadoop 2.0 发布经理 Arun Murthy 看来,其最重要的变化是 MapReduce 框架升级为Apache YARN,这将扩展 Hadoop 中可以应用的软件种类和应用程度。Arun Murthy 本人就是 YARN 项目主管,他指出,Hadoop 1.0 和 2.0 的区别在于,前者所有的事情都是面向批处理的,而后者则允许多个应用同时在内部访问数据。
相对于当前 MapReduce 系统能处理的事情,把这些功能分开使得 Hadoop 集群资源的管理更加强大。其主要管理方式类似于操作系统对任务的处理,也就是说不再有一次一项操作的限制了。
有了 YARN,开发者就能够直接在 Hadoop 内部来开发应用,而不是像许多第三方工具所做的那样,在外面把数据筛选出来。
Murthy 称,现在已经有供应商对在 YARN 框架内开发应用表现出兴趣。Murthy 估计,Hadoop 2.0 的强力 beta 版有可能会在今年 6 月或 7 月推出,正式版则可能在 8 月发布。
如果 YARN 的确能履行其承诺的话,开发者将可以在原生的 Hadoop 平台里方便地接触到许多的数据大湖大海,令搜寻有用信息的任务更加流畅和便捷。届时,大数据会变得更加有用、更加大众化。
相关文章
- 一个Java程序员对2011年的回顾
- 大数据发展历程
- Android高级进阶之路【一】Android中View绘制流程浅析
- 可信服务管理(Trusted Service Manager)介绍
- GIS应用|快速开发REST空间分析服务
- 未来十年微软长盛不衰的两项战略
- 领域驱动设计模式的收益与挑战
- cocos 3.0 一键打包android平台应该注意的细节
- 数智化时代,驱动企业转型升级的“三驾马车”是什么?
- 基于MINA构建高性能的NIO应用
- 使用Rainbond实现离线环境软件交付
- 工作流引擎 jBPM 5.2 发布
- 微信小程序Minium自动化测试(三)
- 桌面应用抢先体验,这次有点料!
- 甲骨文Java专利遭拒 起诉Android侵权受挫
- 云计算的应用领域及发展前景
- Java效率真的很低吗?Android为何要采用?
- Android高级进阶之路【二】十分钟彻底弄明白 View 事件分发机制
- 庖丁解牛之-Android平台RTSP|RTMP播放器设计
- 手机直付,超级方便