
Spark实战:单节点本地模式搭建Spark运行环境
前言:
Spark本身用scala写的,运行在JVM之上。
JAVA版本:java 6 /higher edition.
1 下载Spark
http://spark.apache.org/downloads.html
你可以自己选择需要的版本,这里我的选择是:
http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0-bin-hadoop1.tgz
如果你是奋发图强的好码农,你可以自己下载源码:http://github.com/apache/spark.
注意:我这里是运行在Linux环境下。没有条件的可以安装下虚拟机之上!
2 解压缩&进入目录
tar -zvxf spark-1.1.0-bin-hadoop1.tgz
cd spark-1.1.0-bin-hadoop1/
3 启动shell
./bin/spark-shell
你会看到打印很多东西,***显示
4 小试牛刀
先后执行下面几个语句
- val lines = sc.textFile("README.md")
- lines.count()
- lines.first()
- val pythonLines = lines.filter(line => line.contains("Python"))
- scala> lines.first()
- res0: String = ## Interactive Python Shel
---解释,什么是sc
sc是默认产生的SparkContext对象。
比如
- scala> sc
- res13: org.apache.spark.SparkContext = org.apache.spark.SparkContext@be3ca72
这里只是本地运行,先提前了解下分布式计算的示意图:
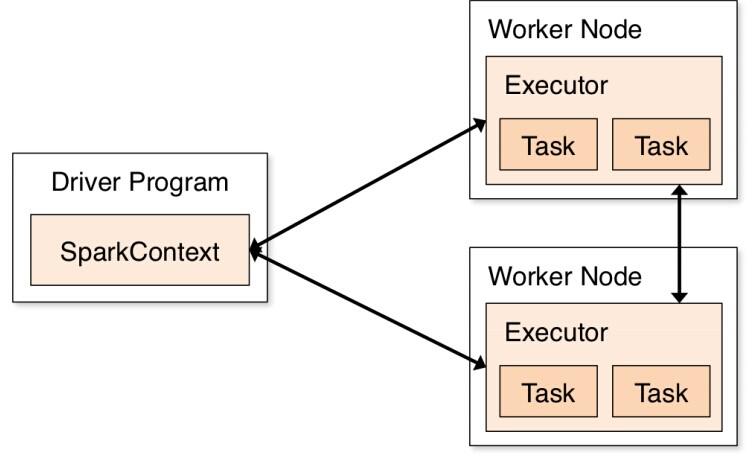
5 独立的程序
***以一个例子结束本节
为了让它顺利运行,按照以下步骤来实施即可:
--------------目录结构如下:
- /usr/local/spark-1.1.0-bin-hadoop1/test$ find .
- .
- ./src
- ./src/main
- ./src/main/scala
- ./src/main/scala/example.scala
- ./simple.sbt
然后simple.sbt的内容如下:
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.10.4"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "1.1.0"
example.scala的内容如下:
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- object example {
- def main(args: Array[String]) {
- val conf = new SparkConf().setMaster("local").setAppName("My App")
- val sc = new SparkContext("local", "My App")
- sc.stop()
- //System.exit(0)
- //sys.exit()
- println("this system exit ok!!!")
- }
- }
红色local:一个集群的URL,这里是local,告诉spark如何连接一个集群,local表示在本机上以单线程运行而不需要连接到某个集群。
橙黄My App:一个项目的名字,
然后执行:sbt package
成功之后执行
./bin/spark-submit --class "example" ./target/scala-2.10/simple-project_2.10-1.0.jar
结果如下:

说明确实成功执行了!
结束!
相关文章
- 直接在代码里面对list集合进行分页
- .NET Framework 4.5新特性详解
- 大数据的简要介绍
- 大数据的由来
- 高斯混合模型的自然梯度变量推理
- timing-wheel 仿Kafka实现的时间轮算法
- 使用Navicat软件连接自建数据库(Linux系统)
- 那一天,我被Redis主从架构支配的恐惧
- Redis 深入了解键的过期时间
- C#使用委托调用实现用户端等待闪屏
- 基于流计算 Oceanus 和 Elasticsearch Service 构建百亿级实时监控系统
- GRAND | 转录调控网络预测数据库
- JFreeChart API中文文档
- 临床相关突变查询数据库
- TIGER | 人类胰岛基因变化查询数据库
- 视频边缘计算网关EasyNVR在视频整体监控解决方案中的应用分析
- Apache Arrow - 大数据在数据湖后的下一个风向标
- 常见的电商数据指标体系
- AKShare-艺人数据-艺人流量价值
- MySQL中多表联合查询与子查询的这些区别,你可能不知道!