
CloudCanal实战-Oracle数据迁移同步到PostgreSQL
简述
本篇文章主要介绍如何使用 CloudCanal 构建一条 Oracle 到 PostgreSQL 的数据同步链路
技术要点
缩小的数据库权限要求
CloudCanal 对 Oracle 数据库的高权限要求,主要来自两个面向 DBA 的操作,自动构建字典和 自动切换归档日志,这两个操作主要是让用户使用更加自动化和便利,但是问题也比较明显,对数据库运维标准严苛的客户来说,这些权限对于我们的客户是没有的,所以新版本 CloudCanal ,通过参数配置,支持了关闭自动字典构建能力(默认打开) 和 关闭自动切换归档日志能力(默认关闭)
多版本 schema 以支持位点回拉
对于关系型数据库同步工具而言,增量数据本身往往和元数据分离,也就是消费到的增量数据和即时从数据库里面获取的元数据不一定匹配(两个时间点之间有DDL),所以维持一个多版本的元数据以应对增量数据解析是必要的, CloudCanal 以每天的 schema dump 为基准,辅以到当前位点的 DDL 语句列表,可构建出任何时间点的元数据(实际上是更加精确的 scn 位点),单个 DDL 前后的数据变更事件,能够精确匹配到相对应的元数据进行解析, CloudCanal 才有可能在此版本产品上提供了回拉位点重复消费一段时间增量数据的能力
支持的版本
源端 Oracle 支持的版本:10.X、11.X、12.X、18.X、19.X
对端 PostgreSQL 支持的版本:8.4、9.0、9.1、9.2、9.3、9.4、9.5、9.6、10.X、11.X、12.X、13.X、14.X 、15.X、16.X、17.X
支持的DDL&数据类型映射
- Oracle -> PostgreSQL 链路支持的DDL暂时只有 ALTER TABLE ,后续我们将不断进行完善
- CloudCanal 结构迁移和数据迁移同步时会自动进行数据类型映射
类型映射见下表:
| Oracle 字段类型 | PostgreSQL 字段类型 |
|---|---|
| CHAR、NCHAR、VARCHAR2、NVARCHAR、NVARCHAR2、ROWID、HTTPURITYPE | CHARACTER_VARYING |
| LONG、CLOB、NCLOB | TEXT |
| NUMBER_BIGINT | BIGINT |
| NUMBER_DECIMAL、BINARY_FLOAT、BINARY_DOUBLE | NUMERIC |
| FLOAT | REAL |
| DATE、TIMESTAMP | TIMESTAMP_WITHOUT_TIME_ZONE、TIMESTAMP_WITHOUT_TIME_ZONE |
| TIMESTAMP_WITH_TIME_ZONE、TIMESTAMP_WITH_LOCAL_TIME_ZONE | TIMESTAMP_WITH_TIME_ZONE |
| XMLTYPE | XML |
Tips : 针对于 Oracle -> PostgreSQL 链路,源端 Oracle 不在上表的字段类型暂时不支持
操作示例
准备工作
- 安装最新版的 CloudCanal
- 准备好源端数据源和对端数据源以及源端数据
- CloudCanal 以 Oracle 作为源端进行数据迁移时,需要做一些额外的准备,具体参考ORACLE LogMiner同步准备
添加数据源
- 登录 CloudCanal 平台
- 数据源管理 -> 新增数据源
- 选择自建数据库 -> 选择对应数据库 -> 输入相关信息 -> 测试连接-> 新增数据源
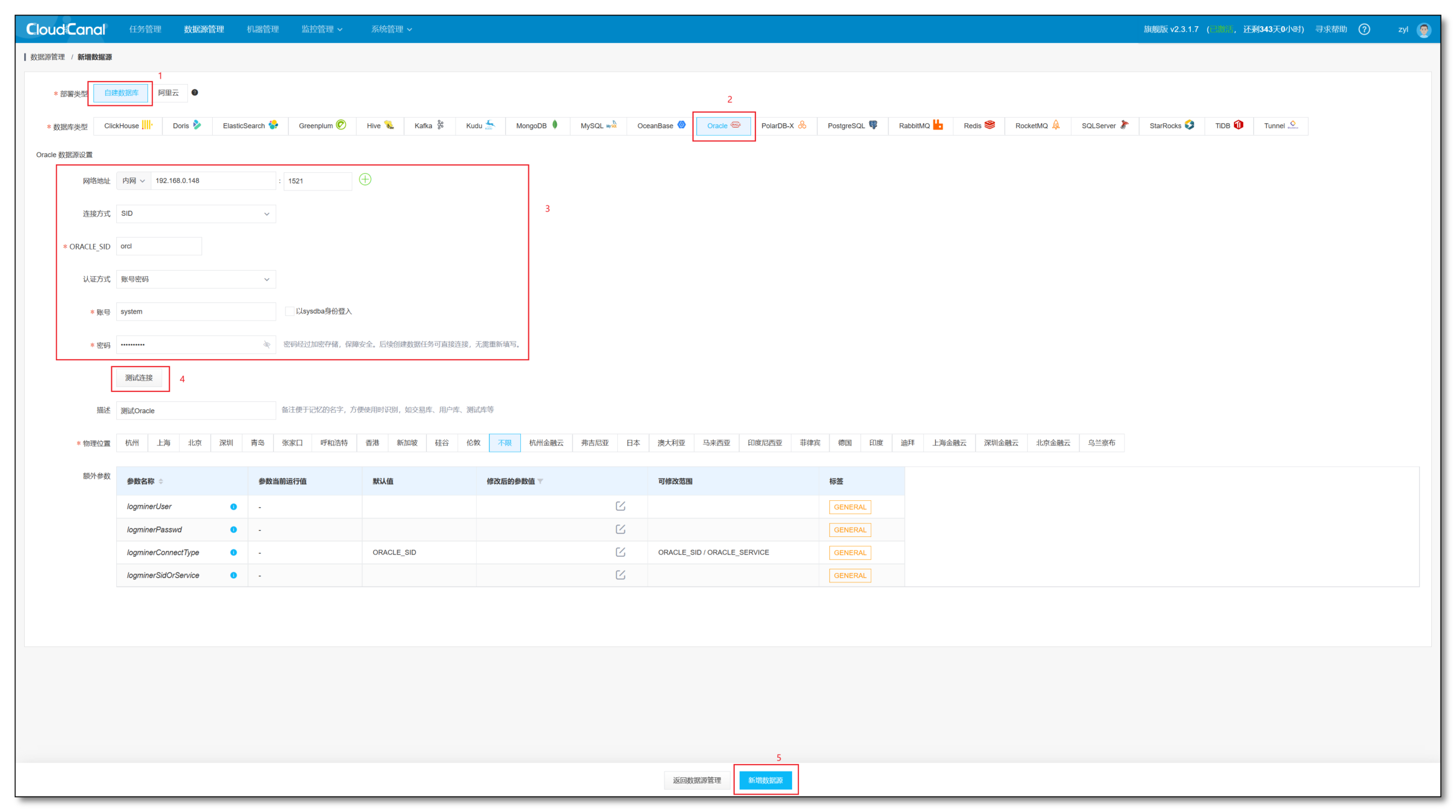
Tips :Oracle 相较于其他数据源有一些额外的参数可以调整
- logminerUser:ORACLE源端增量任务使用redo解析(logminer)方式时使用的账号,需要CDB类型用户
- logminerPasswd:ORACLE源端增量任务使用redo解析(logminer)方式时使用的账号密码
- logminerConnectType:ORACLE源端增量任务使用redo解析(logminer)方式时使用的连接方式,目前支持ORACLE_SID或ORACLE_SERVICE模式
- logminerSidOrService:ORACLE源端增量任务使用redo解析(logminer)方式时使用的连接标识符,和logminerConnectType参数配合使用,ORACLE_SID连接方式,则填写sid,ORACLE_SERVICE连接方式,则填写service name
- 添加 Oracle 和 PostgreSQL 之后可以在数据源列表中看到新增的数据源
创建同步任务
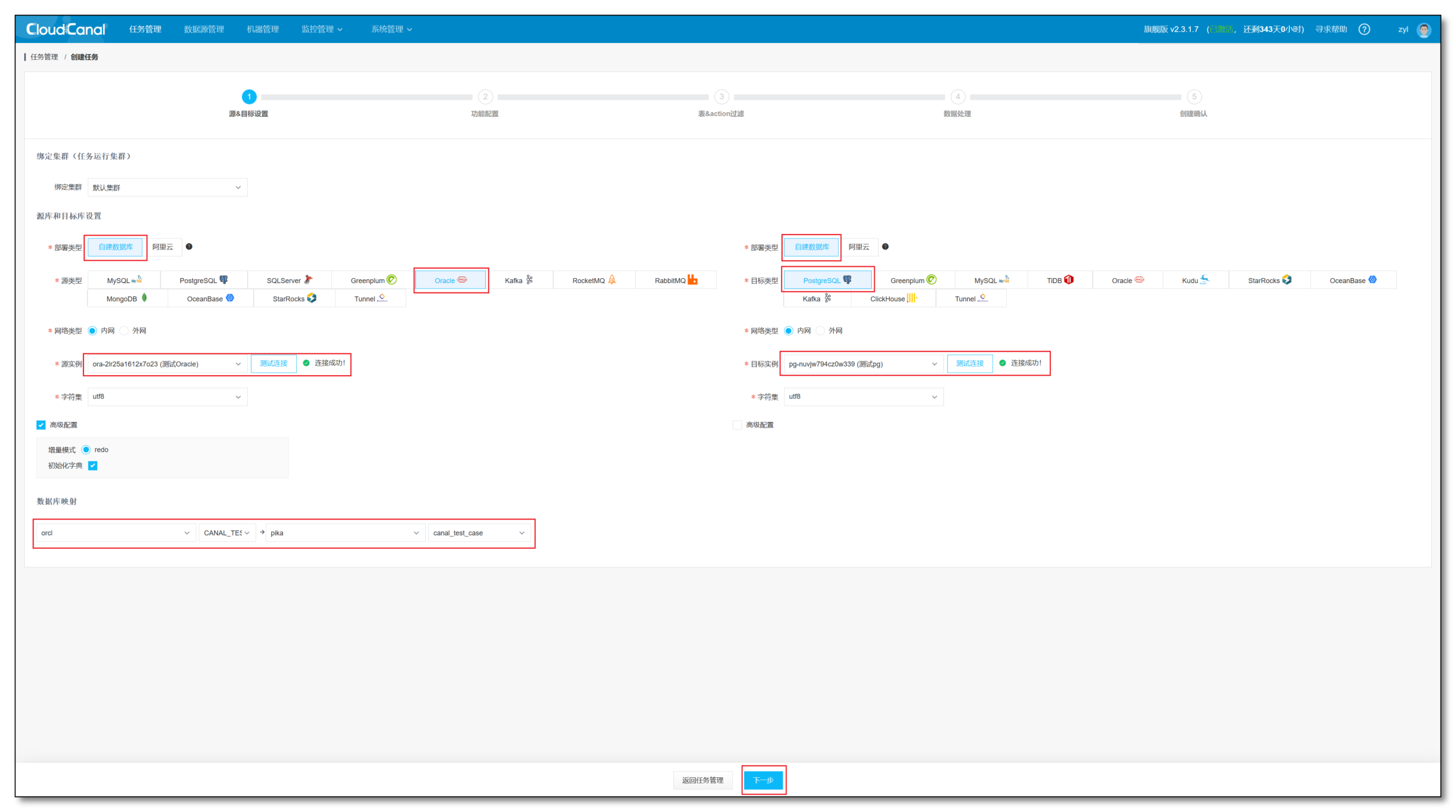
- 任务管理 -> 创建任务
- 源端选择 Oracle 数据源,对端选择 PostgreSQL数据源
- 分别点击测试连接,选择源端和对端需要订阅的数据库,选择下一步
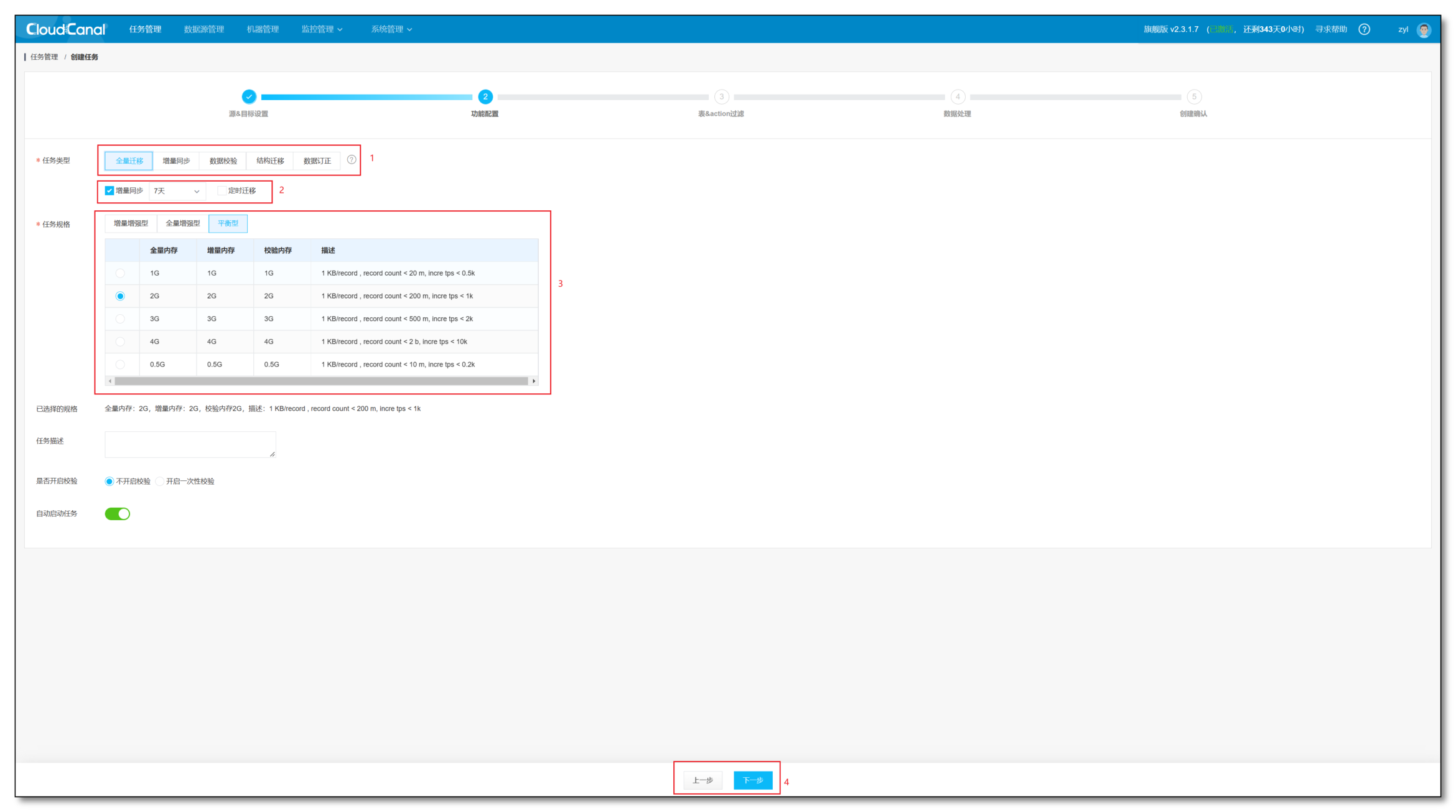
- 选择 全量迁移 -> 勾选 增量同步 -> 根据自身机器配置选择 任务规格
- 选择 下一步
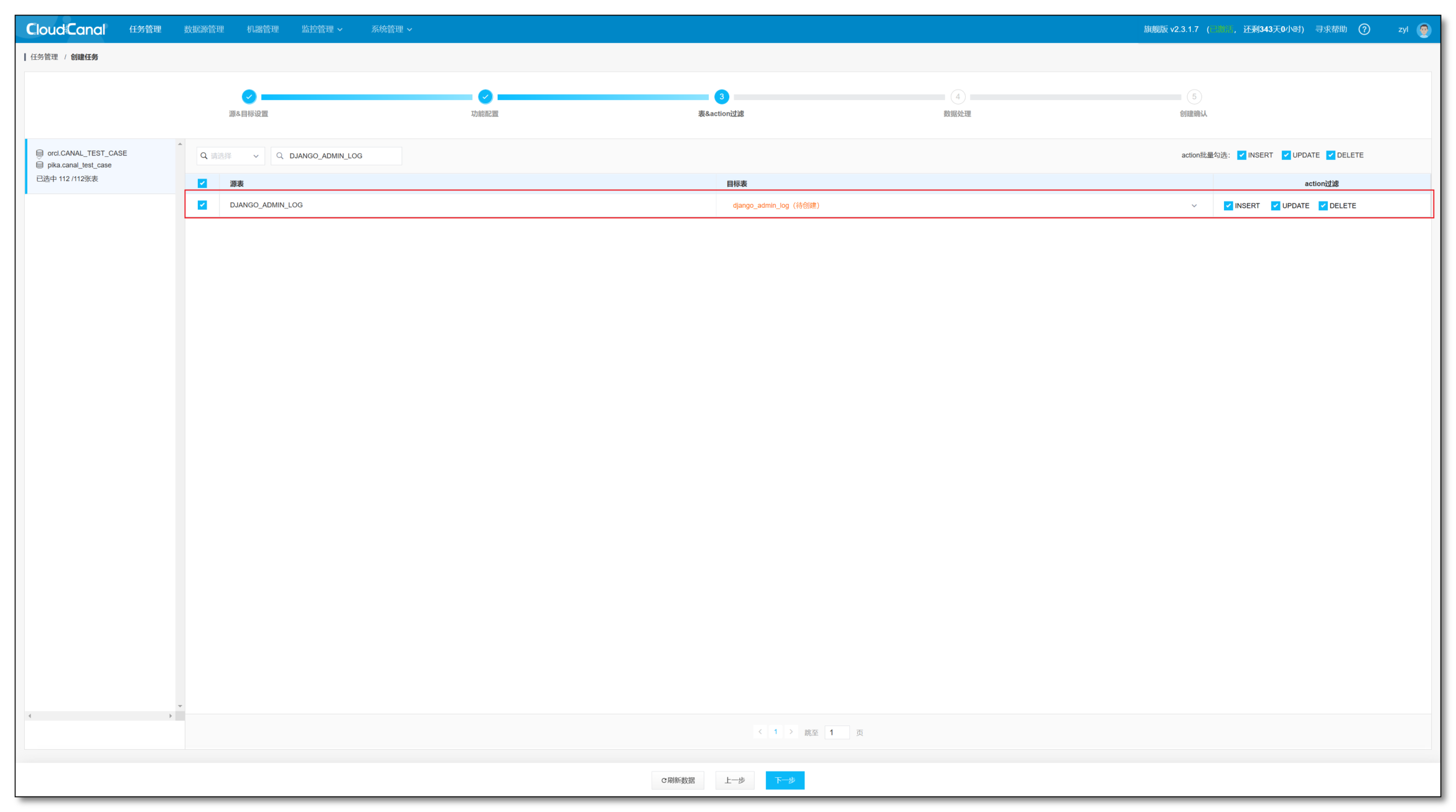
- 选择源端需要同步的表,如果目标表显示橙色表示对端不存在该表,任务创建之后,会自动生成该表
- 点击 下一步
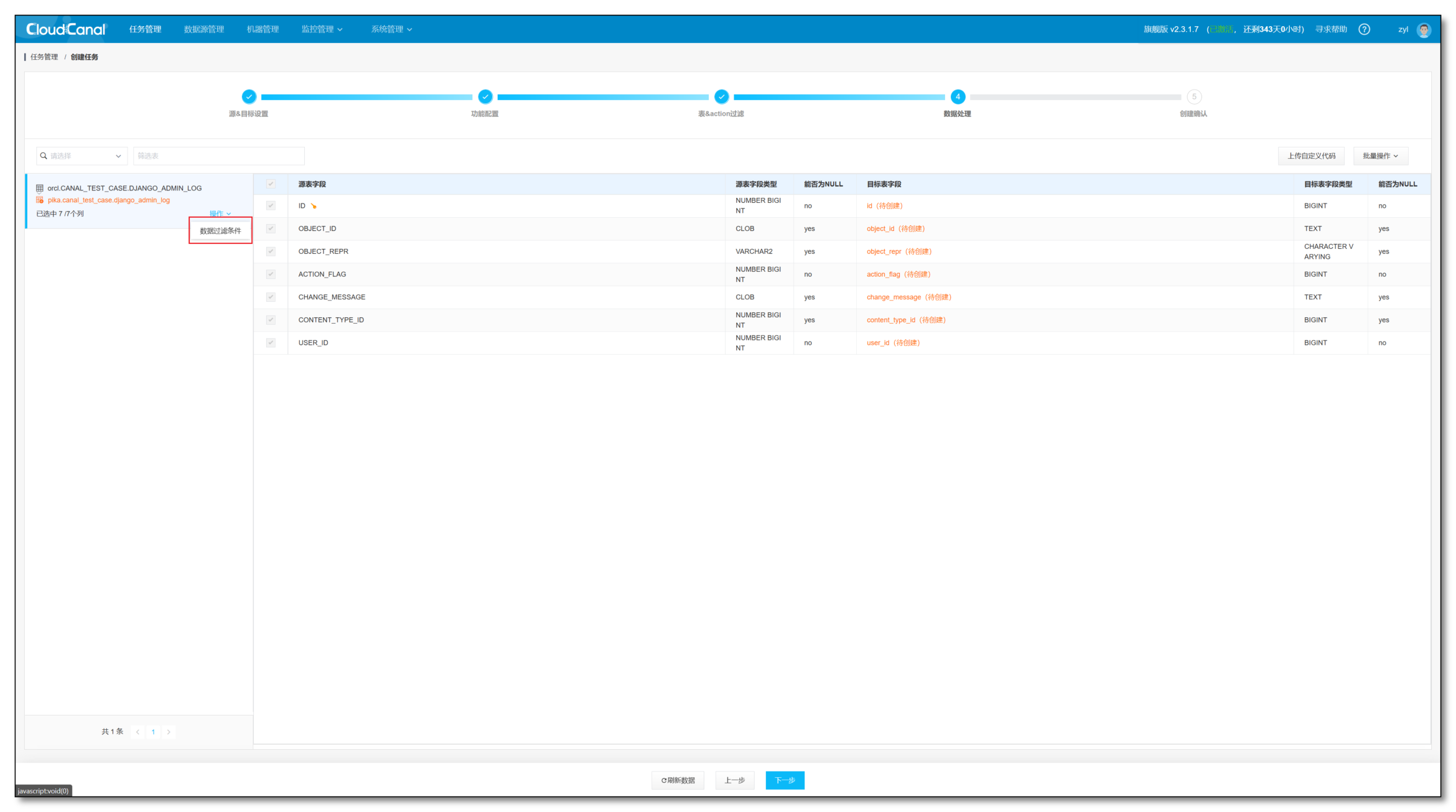
- 可以在左侧选择添加 数据过滤条件
- 点击 下一步
- 点击 创建任务
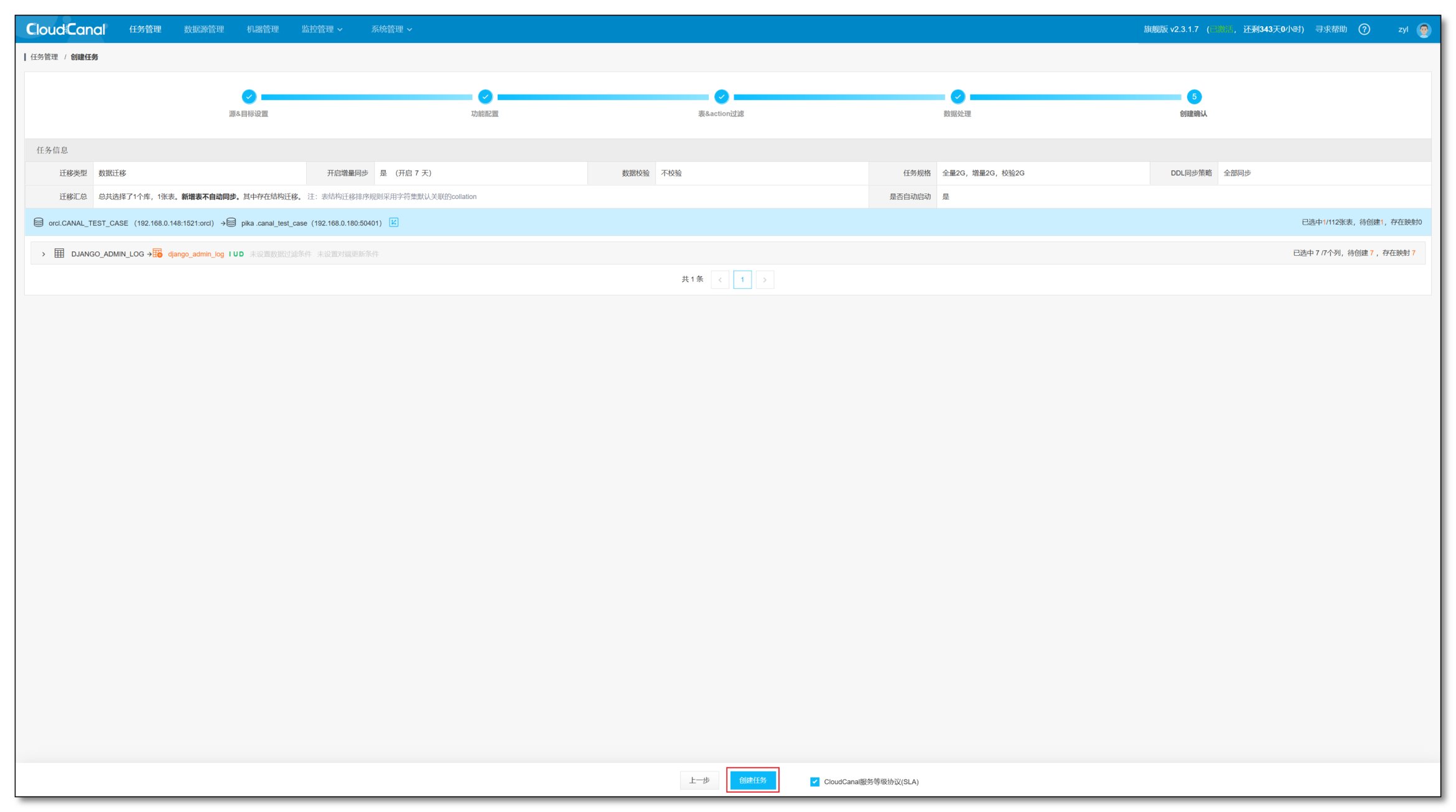
任务执行
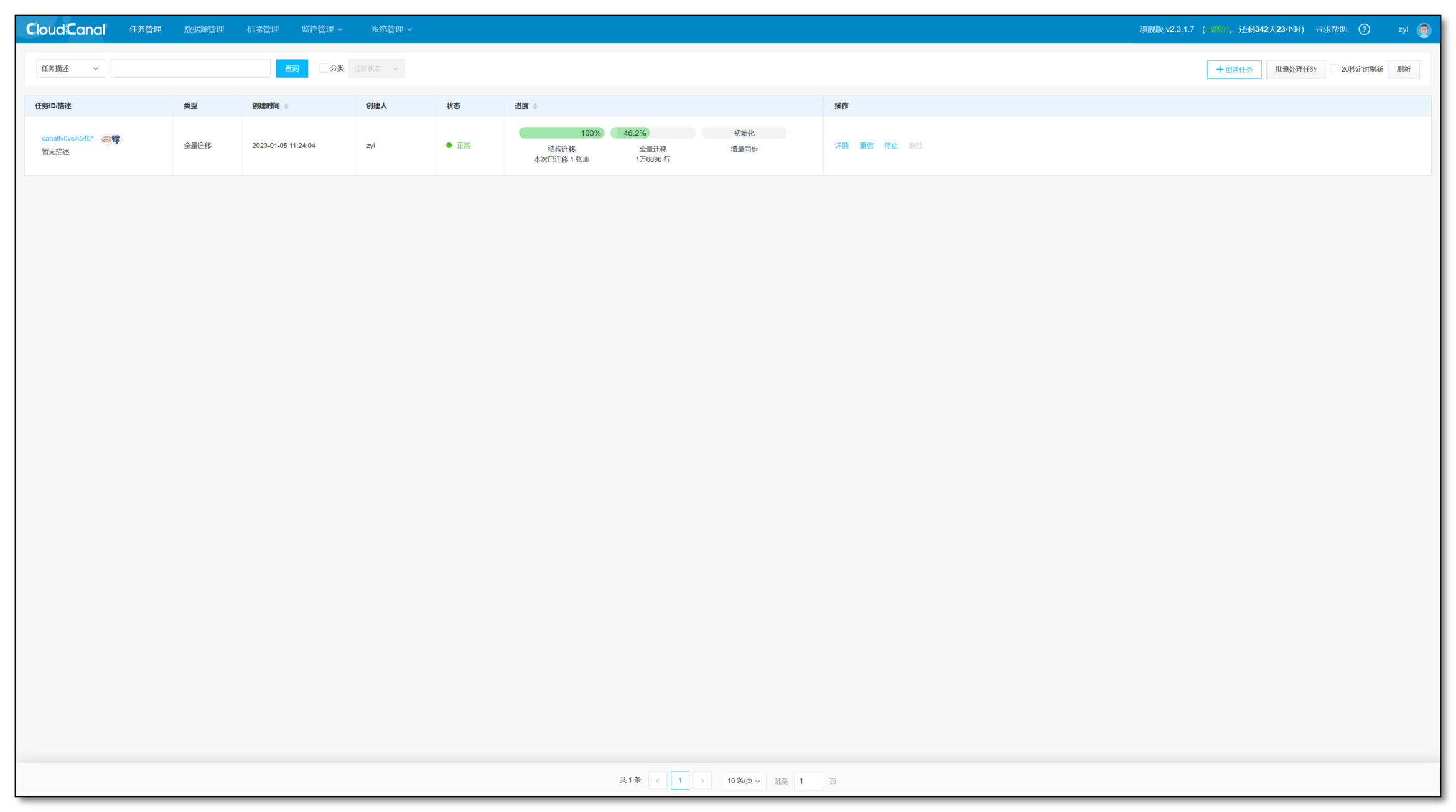
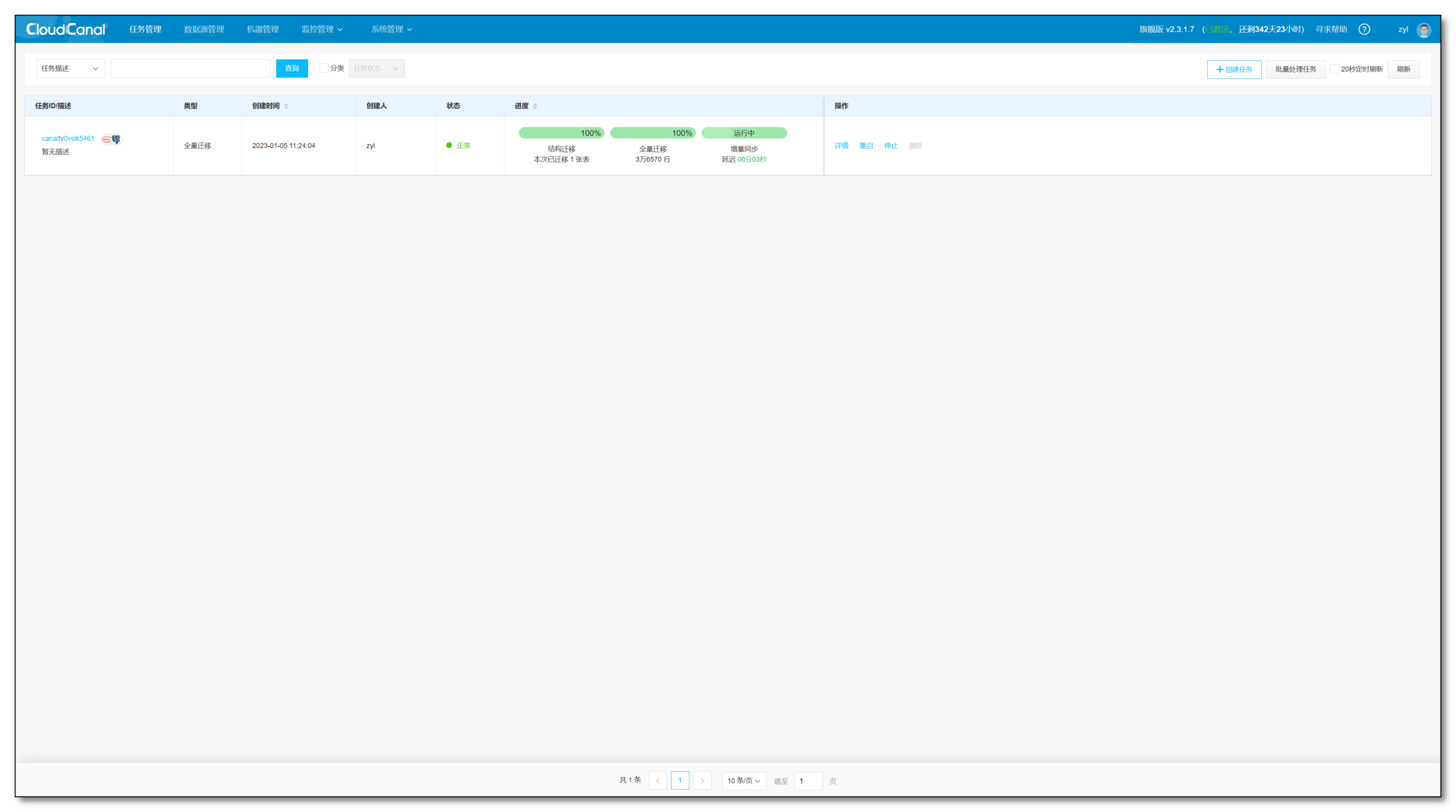
任务创建并且启动后,会自动进行如下的三个阶段:
- 结构迁移:任务创建之后,如果对端没有表结构,那么 CloudCanal 会去自动在对端创建表结构
- 全量迁移:将源端存量数据整体迁移到对端
- 增量同步:全量迁移期间以及全量完成以后的源端增量数据变更会实时同步到对端
总结
本文简单介绍了如何使用 CloudCanal 进行 Oracle -> PostgreSQL 数据迁移同步。各位读者朋友,如果你觉得还不错,请点赞、评论加转发吧
相关文章
- 从本体论开始说起——运营商关系图谱的构建及应用
- 如何成为一名数据科学家?
- 从未见过的堂兄杀了人,你的DNA是关键证据
- 20个安全可靠的免费数据源,各领域数据任你挑
- 20个安全可靠的免费数据源,各领域数据任你挑
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假