
MySQL索引底层为什么用B+树?看完这篇文章,轻松应对面试。
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子。
手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:“我爱加班”。

面试开始,直入正题。
面试官: 你知道MySQL索引底层数据结构为啥用B+树?而不用B树、红黑树或者普通二叉树?
我: 这事谁知道作者咋想的?他可能是用B+树习惯了,个人爱好吧。
面试官: 你倒是挺看得开。今天的面试就先到这吧,后面有消息会主动联系你。
后面还可能有消息吗?你们啥时候主动联系过我?
实话实说的被拒,八股文背得溜反而被录取。
好吧,等我看看一灯怎么总结的MySQL的八股文。
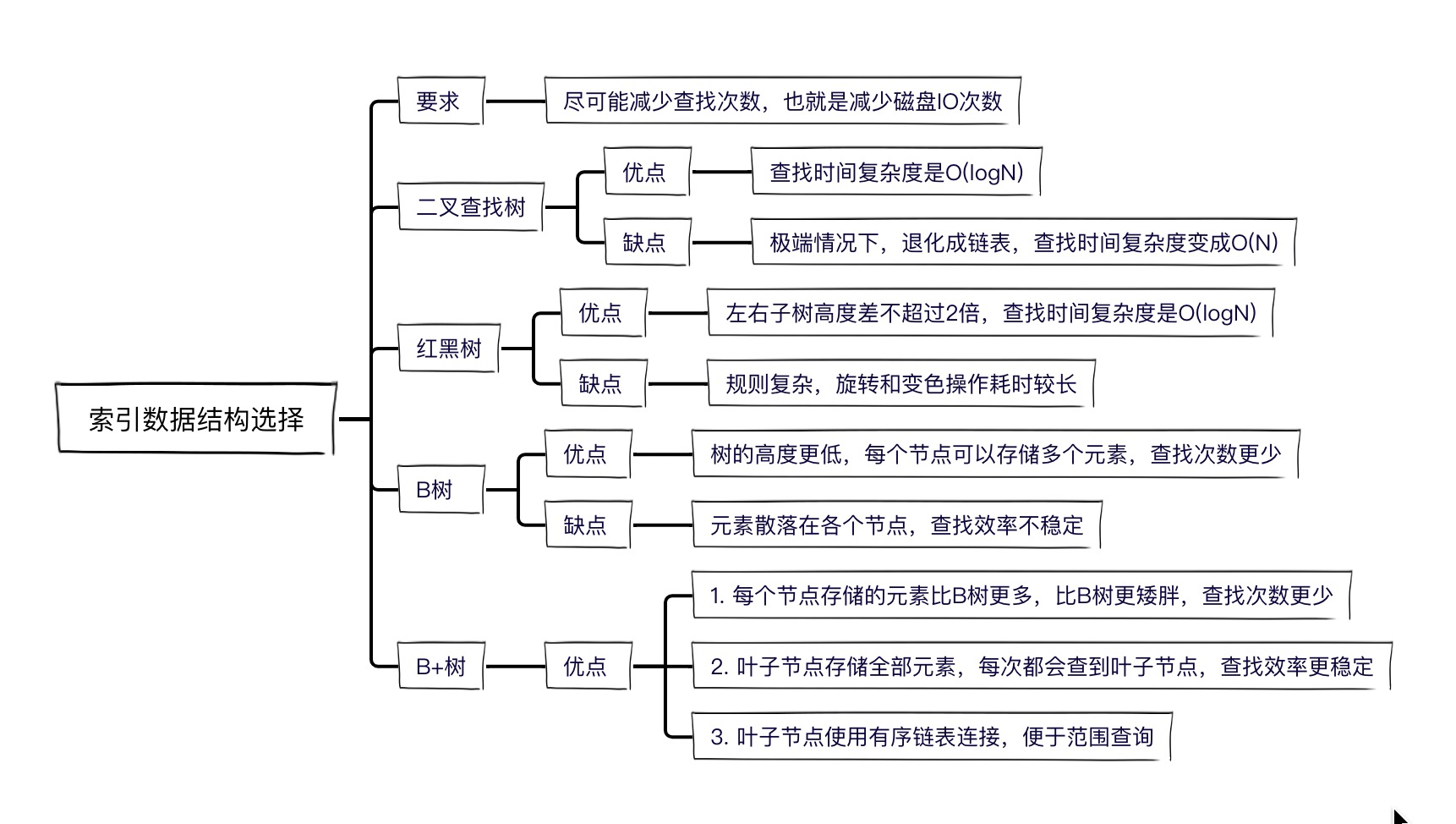
我: 要知道MySQL索引底层数据结构为啥用B+树,先要了解一下什么样的数据结构更适合建索引。
为了保证数据安全性,一般都是把数据存储在磁盘里面。当我们需要查询数据的时候,需要读取磁盘,就产生了磁盘IO,相比较内存操作,磁盘IO读取速度是非常慢的。
由于所需数据可能在磁盘并不是连续的,一次数据查询就需要多次磁盘IO,所以就需要我们设计的索引数据结构尽可能的减少磁盘IO次数。
再了解一下这几种二叉树的特性,以及优缺点,就知道哪种数据结构更适合建索引。
什么是二叉搜索树:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 左、右子树也分别为二叉查找树;
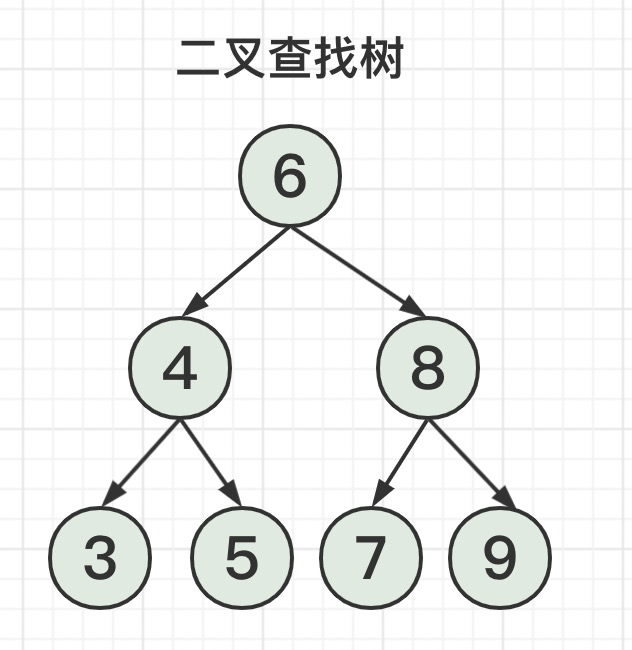
二叉搜索树查找数据的时间复杂度是O(logN),如图所示,最多查找3次就可以查到所需数据。
理想很丰满,现实很骨感。极端情况下,二叉查找树可能退化成线性链表。
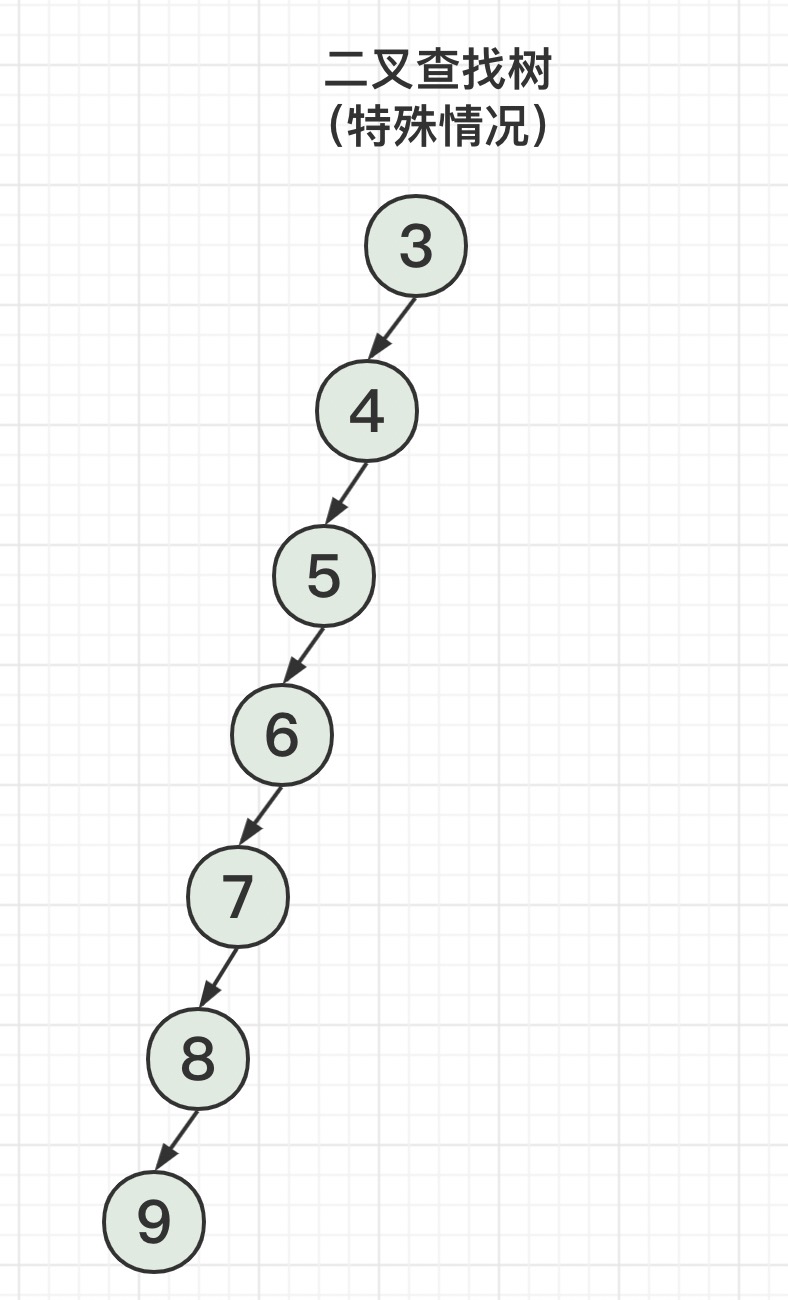
链表的查找时间复杂度是O(N),这时候最多需要7次才能查到所需数据。
该怎么办呢?于是我们就想到了给二叉树加一些限制条件,平衡一下左右子树,然后就引申出了很多平衡树:平衡二叉查找树、红黑树、B树、B+树。咱们分别说一下这几种树的优缺点,看哪种树最适合做索引。
什么是红黑树?
- 结点是红色或黑色
- 根结点是黑色
- 所有叶子都是黑色(叶子是NIL结点)
- 每个红色结点的两个子结点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色结点)
- 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点

看蒙了没有?
这么多复杂的规则,就是为了保证从根节点到叶子节点的最长路径不超过最短路径的2倍。
当插入节点或者删除节点的时候,为了满足红黑树规则,可能需要变色和旋转,这是一个复杂且耗时的过程。
红黑树的优点:
限制了左右子树的树高,不会相差过大。
缺点:
规则复杂,一般人想要弄懂这玩意儿,就已经很费劲了,更别说使用了。
什么是B树?
我们知道,树的高度越高,查找次数越多,也就是磁盘IO次数越多,耗时越长,
我们能不能想办法降低树的高度,把二叉树变成N叉树?于是B树就来了。
对于一个m阶的B树:
- 根节点至少有2个子节点
- 每个中间节点都包含k-1个元素和k个子节点,其中 m/2 <= k <= m
- 每个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
- 中间节点的元素按照升序排列
- 所有的叶子结点都位于同一层
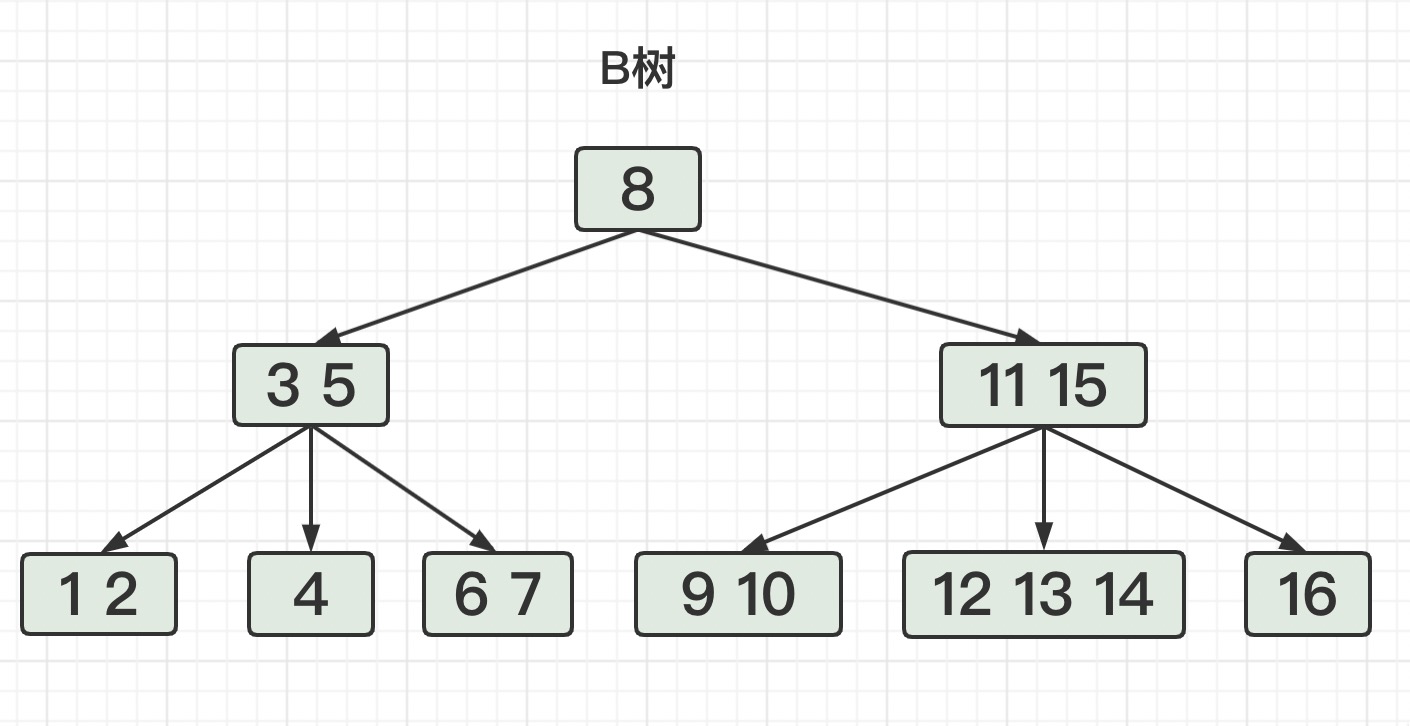
根节点(8)有两个子节点,左子节点(3 5)和右子节点(11 15)。
左子节点(3 5)中有2个元素和3个子节点。
元素是3和5,按照升序排列。
子节点是(1 2)、(4)、(6 7),
而(1 2)中元素小于3,(4)中的元素在3和5中间,(6 7)的元素大于5,符合B树特征。
B树这样的设计有哪些优点呢?
高度更低,每个节点含有多个元素,查找的时候一次可以把一个节点中的所有元素加载到内存中作比较,两种改进都大大减少了磁盘IO次数。
什么是B+树?
相比较B树,B+树又做了如下约定:
-
有k个子节点的中间节点就有k个元素(B树中是k-1个元素),也就是子节点数量 = 元素数量。
每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。 -
所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
-
非叶子节点只保存索引,不保存数据。(B树中两者都保存)
-
叶子结点包含了全部元素的信息,并且叶子结点按照元素大小组成有序列表。
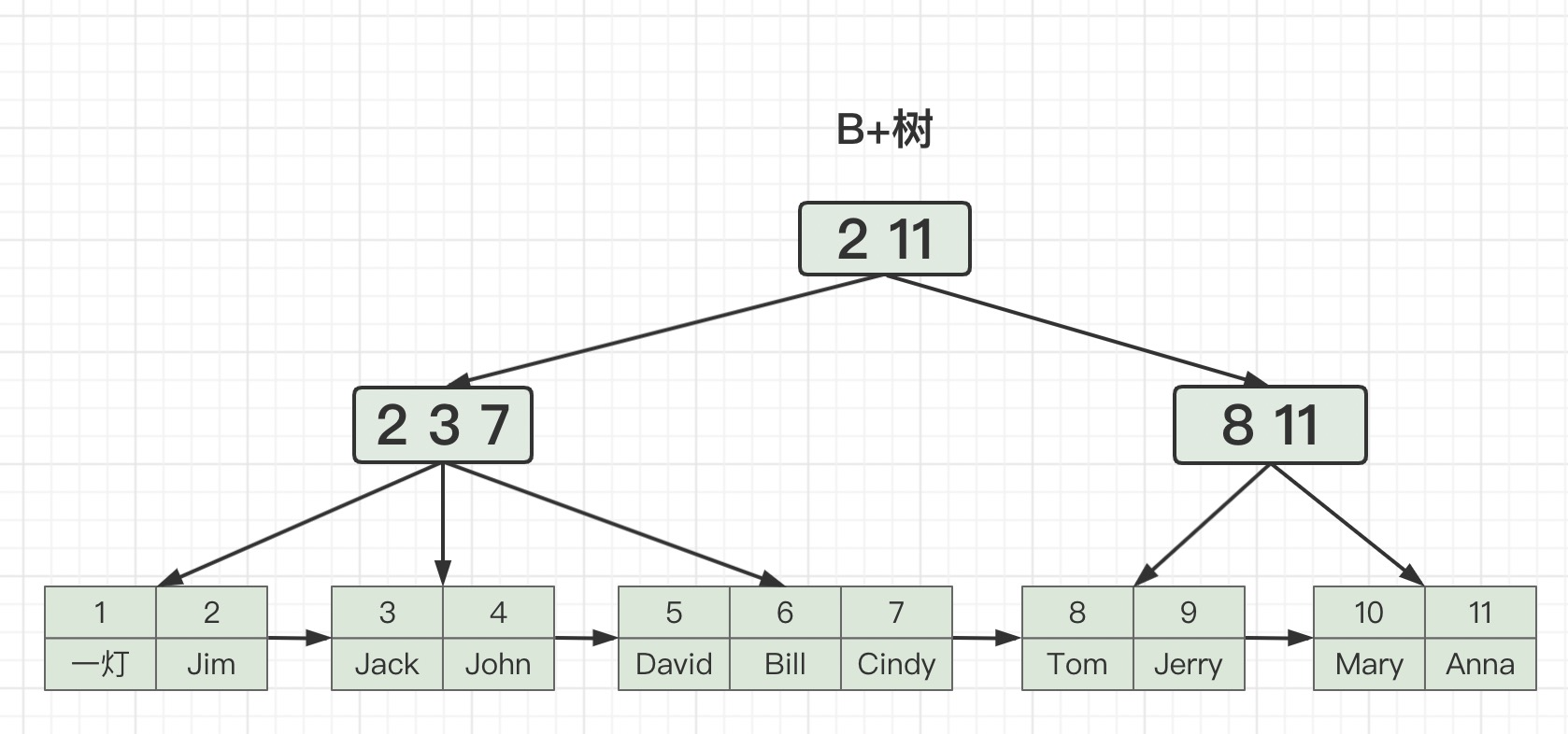
B+树这样设计有什么优点呢?
- 每个节点存储的元素更多,看起来比B树更矮胖,导致磁盘IO次数更少。
- 非叶子节点不存储数据,只存储索引,叶子节点存储全部数据。
这样设计导致每次查找都会查到叶子节点,效率更稳定,便于做性能优化。 - 叶子节点之间使用有序链表连接。
这样设计方便范围查找,只需要遍历链表中相邻元素即可,不再需要二次遍历二叉树。
很明显,B树和B+树就是为了文件检索系统设计的,更适合做索引结构。
面试官: 还得是你,就你总结的全,我都想不那么全,明天来上班吧,薪资double。
本文知识点总结:
文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。
相关文章
- 从本体论开始说起——运营商关系图谱的构建及应用
- 如何成为一名数据科学家?
- 从未见过的堂兄杀了人,你的DNA是关键证据
- 20个安全可靠的免费数据源,各领域数据任你挑
- 20个安全可靠的免费数据源,各领域数据任你挑
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假