
用HTTP服务的方式集成 learned cardinality estimation 方法进 Postgresql
2023-03-31 11:01:18 时间
代码地址:postgresql-13.1-ml: Integration of CardEst Methods into PostgreSQL by HTTP Server (github.com)
当前进度:可以支持单表查询、多表inner join的基数估计模块的替换。
注意:本文的重点在于PG的修改。记录一下我的修改思路。
整体流程
PG作为http客户端,向基数估计服务端发送http请求。内容为需要基数估计的SQL语句。
基数估计服务端返回该语句的selectivity。
PG收到该查询的selectivity后乘以当前表的大小,即得到rows
项目的难点主要在于获取需要基数估计的SQL查询语句。
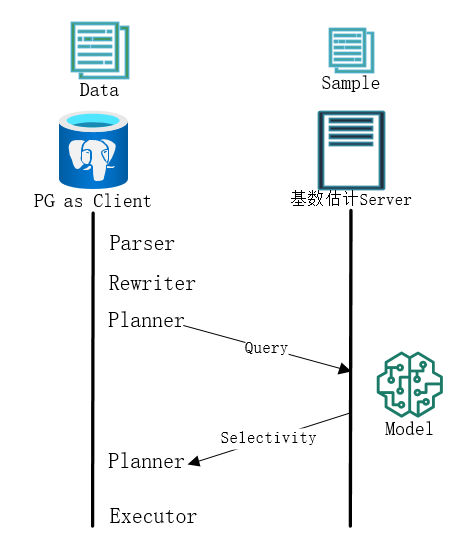
PG原版基数估计调用逻辑

修改源码
主要修改代码costsize.c
单表修改set_baserel_size_estimates函数
修改逻辑

其中get_expr函数的逻辑可参考print.c文件中print_expr函数
多表修改set_joinrel_size_estimates函数
获取需要基数估计的当前SQL查询语句

添加第三方库
该项目需要其它两个第三方库
- C语言的HTTP服务的client端的库,参考项目:linux下socket(C)构造HTTP客户端
- C语言解析json格式的库,参考项目:cJSON
将第三方库的头文件和实现文件加入到PG中:
- 把http.h 添加到 /src/include/utils/下
- costsize.c 添加 #include "utils/http.h”
- 把cJSON.h 添加到 /src/include/utils/下
- 把cJSON.c 添加到 /src/backend/utils/adt/下
- cJSON.c 把#include "cJSON.h”修改成#include "utils/cJSON.h”
- 在/src/backend/utils/adt/Makefile添加 cJSON.o
- costsize.c 添加 #include "utils/cJSON.h”
效果
单表查询的效果
测试数据集:imdb.title
PG原版计划 VS learned方法的计划
通过 set enable_ml_cardest=True;就可以实现单表基数估计方法的切换。
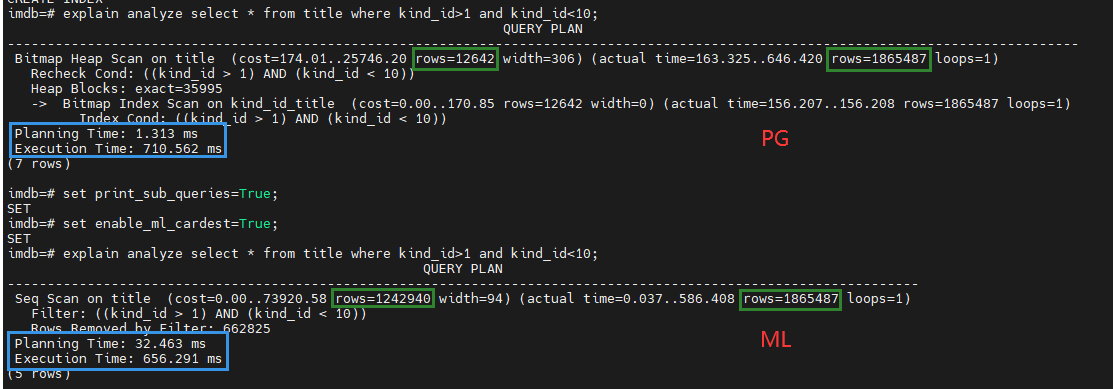
最优计划(基数估计较准时产生的计划)

可以看到learned方法基数估计更准确,产生的执行计划与基数估计几乎正常产生的计划一致。而PG原版的基数估计由于准确度太低,导致产生了次优的执行计划。
虽然learned方法的速度没有PG原版快,但产生的计划更优,导致节省了执行时间,所以整体时间更优。
多表查询的效果
测试数据集:imdb
PG原版基数估计产生的计划 VS 多表基数估计为真值情况下产生的计划
通过 set enable_ml_joinest=True;就可以实现多表基数估计方法的切换。
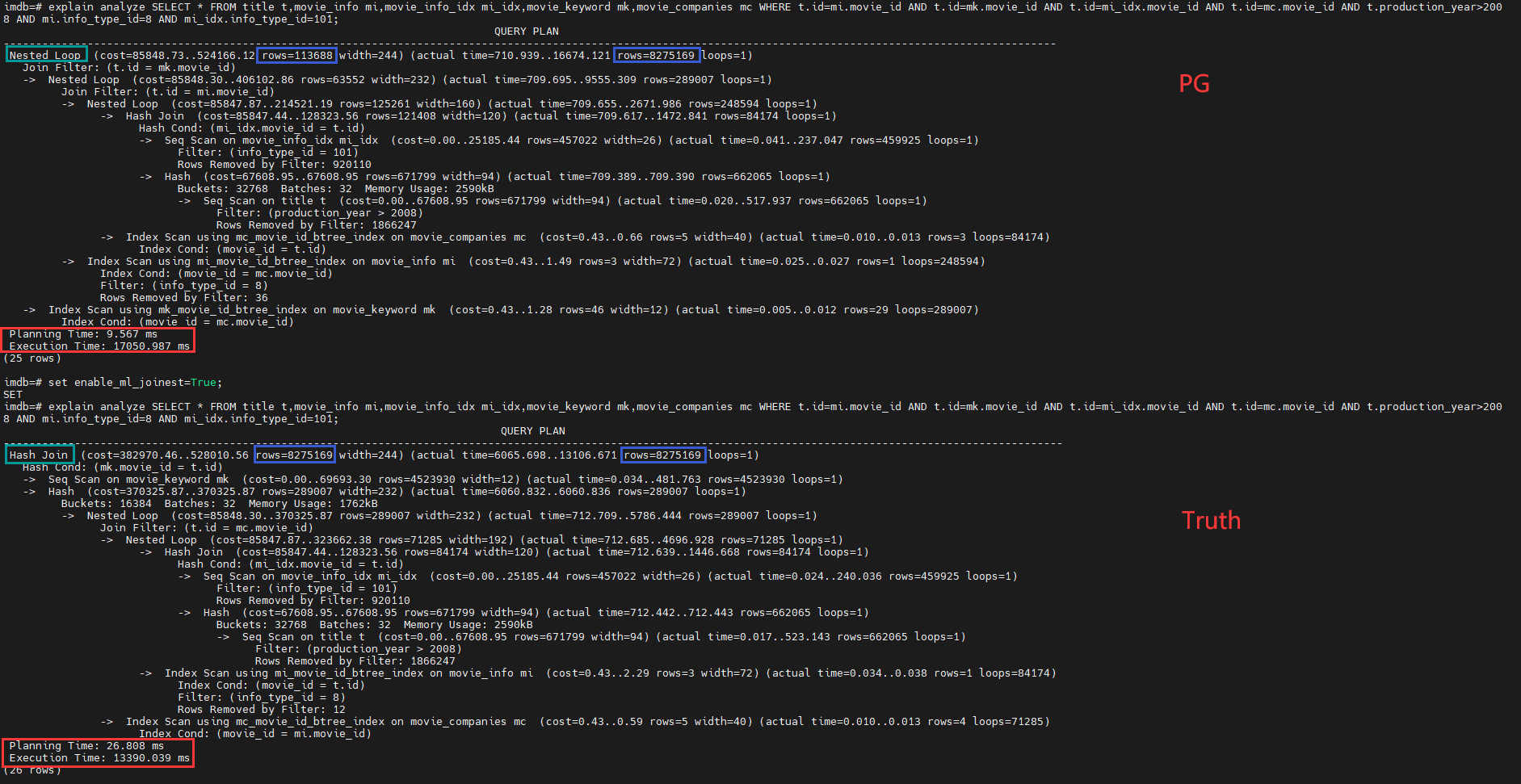
待完善
- 当前版本只适用于实验环境。尚未对不支持的查询进行过滤。
参考资料
- End-to-End-CardEst-Benchmark
- VLDBSS2022实验
- PostgreSQL 在内核增加一个配置参数
- linux下socket(C)构造HTTP客户端
- cJSON使用详细教程 | 一个轻量级C语言JSON解析器
- cJSON
相关文章
- 深入解析Apache Pulsar系列(一):客户端消息确认
- 关于程序员成长的一点思考
- 如何在一幅图像中寻找到目标物?
- 做个网页玩玩
- .NET6新东西--隐式命名空间引用
- JFreeChart简单介绍及入门实例
- 安全 | 腾讯云主机是如何实现Web页面防篡改?
- 如何对接IVS获取车载监控GPS位置告警订阅接口?
- Android Handler机制:Looper、Handler、MessageQueue、Message的关系
- C++设计模式 - 原型模式
- 修改源码去除zblog博客分类目录的RSS图标
- SkinSharp用法
- PHP高级特性-反射Reflection以及Factory工厂设计模式的结合使用[代码实例]
- 如何制作固定资产标识卡
- Matlab画图-非常具体,非常全面
- 开发效率与系统稳定性杂谈
- systemx3650 m5 raid 1 两块硬盘掉线故障回顾
- linux和windows文件名称长度限制
- 家居行业渠道商销售系统线上线下一体化运作,促进产品更新迭代
- 单片机和5v电压的那些事