
Hadoop安装
记录第一次搭建Hadoop集群。
使用版本:
- Ubuntu:ubuntu-20.04.5-desktop-amd64.iso
- Hadoop:hadoop-2.7.5.tar.gz
对vim 的基本命令:
- 进入编辑状态:insert
- 删除:delete
- 退出编辑状态:ctrl+[
- 进入保存状态:ctrl+]
- 保存并退出:" :wq " 注意先输入英文状态下冒号
- 不保存退出:" :q! " 同上
准备虚拟机
网上教程很多,可以随便参考一个,搭建自己的Ubuntu虚拟机。然后使用克隆,一共准备三台虚拟机
修改主机名

用户名@主机名
克隆的三台服务器用户名主机名都是相同的,我们需要修改其主机名,可以分别设置为master、slave01、slave02.(随意即可,我的是serendipity、slave01、slave02,方便起见,后面都采用我自己的命名方法)
sudo vim /etc/hostname

第一行就是本机主机名信息,将三台主机分别修改为对应的serendipity、slave01、slave02,进行保存。对虚拟机重启后即可生效。
ping 通三台主机
首先记录三台主机的ip地址。(可以自己设置静态ip,也可直接进行操作)
ifconfig
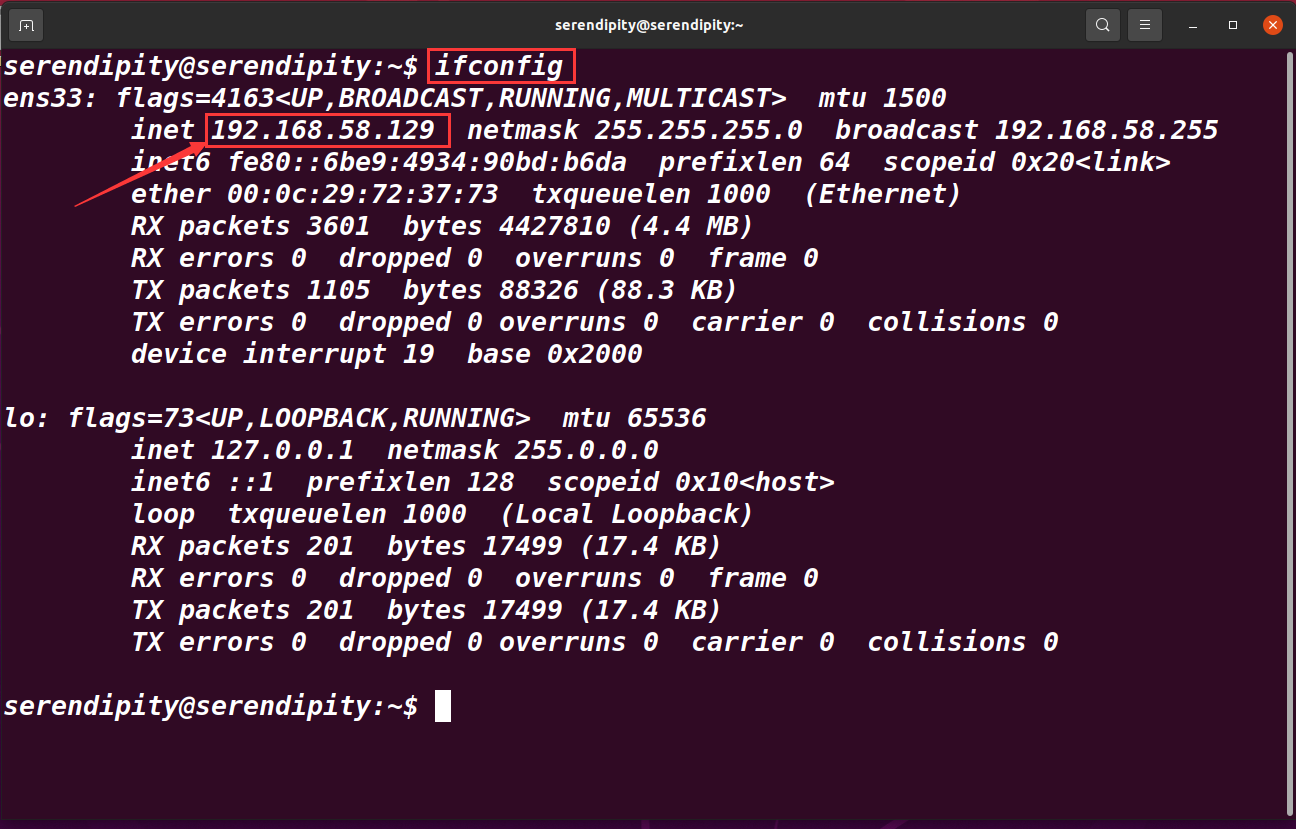
记录三台主机
192.168.58.129 serendipity
192.168.58.134 slave01
192.168.58.135 slave02
分别三台主机,设置节点IP映射
sudo vim /etc/hosts
本来上面一串东西,可以都删掉。

ping 测试
ping IP地址
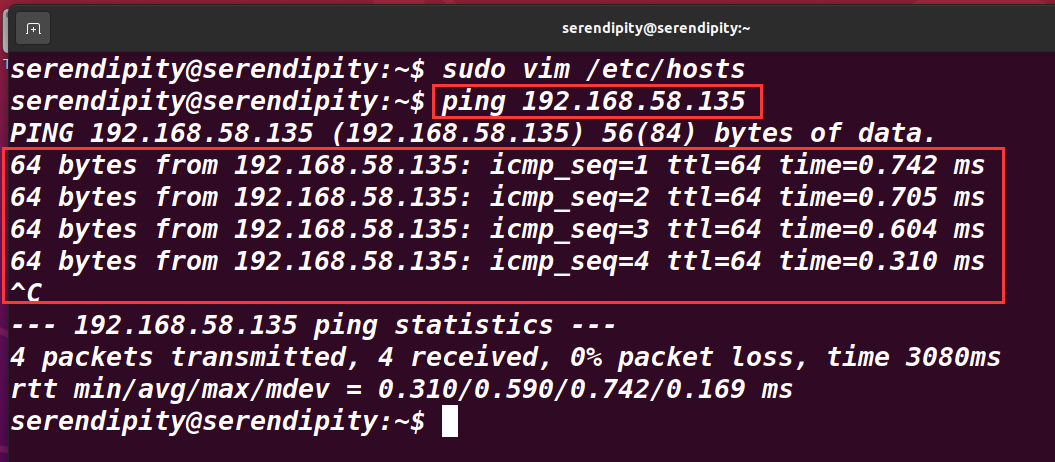
出现下面矩形框,便是成功。分别再三台主机进行测试
ssh免密
基础准备
安装ssh
sudo apt-get install openssh-server #安装服务,一路回车
sudo /etc/init.d/ssh restart #启动服务
sudo ufw disable #关闭防火墙,不然后面会出现很多奇妙的bug
查看是否开通ssh服务
ps -e | grep ssh

如上即可:
设置免密登录
-
再serendipity节点生成SSH公钥
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost rm ./id_rsa* # 删除之前生成的公匙(如果有) ssh-keygen -t rsa # 一直按回车就可以 -
让 serensipity可以免密ssh本机
cat ./id_rsa.pub >> ./authorized_keys -
完成后可以验证一下
ssh serendipity
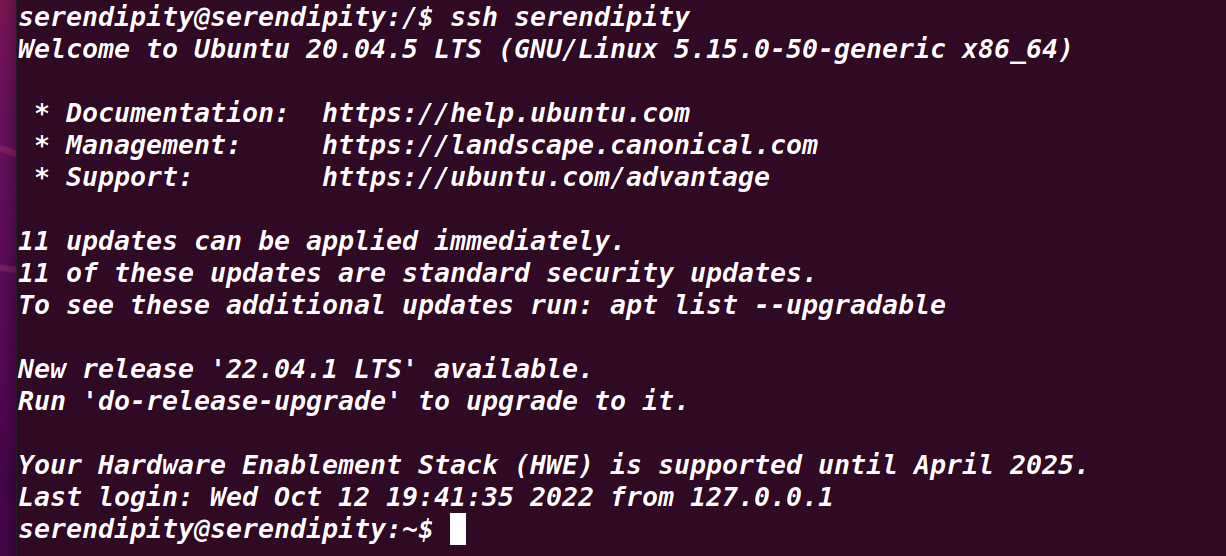
不需输入密码即为成功,输入exit返回原终端
-
将serendipity节点将公钥传输到slave01节点,需要密码就将密码输入即可,@前后就是你的终端显式的东西,用户名@主机名
scp ~/.ssh/id_rsa.pub serendipity@slave01:/home/serendipity -
再slave01节点将公钥加入授权
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就可以删掉了 -
slave02也重复上述节点。主机节点可以免密登录两个节点即可
安装配置Hadoop
建议使用推荐的版本。高版本的可能配置文件与下列描述有所出入。
下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/
jdk8
先去安装一下jdk8.
下载安装
建议再外部主机下载,虚拟机下载网络很慢。下载结束后使用Xftp 或者只用Vmware 安装VMware tools后直接拖拽入虚拟机。
将软件再一个合适的目录解压。(作为linux小白,不太懂 local 、opt的作用啥的,就自己建了一个hadoop文件夹)
进入压缩包所在文件目录内,执行解压命令
tar -zxvf hadoop-2.7.5.tar.gz
或者后等待解压完成,完成后会再同级目录下创建名为hadoop-2.7.5文件夹。
将其修改文件夹名为 hadoop。这就是hadoop安装目录
mv hadoop-2.7.5 hadoop
进入安装目录,查看安装文件,如图所示
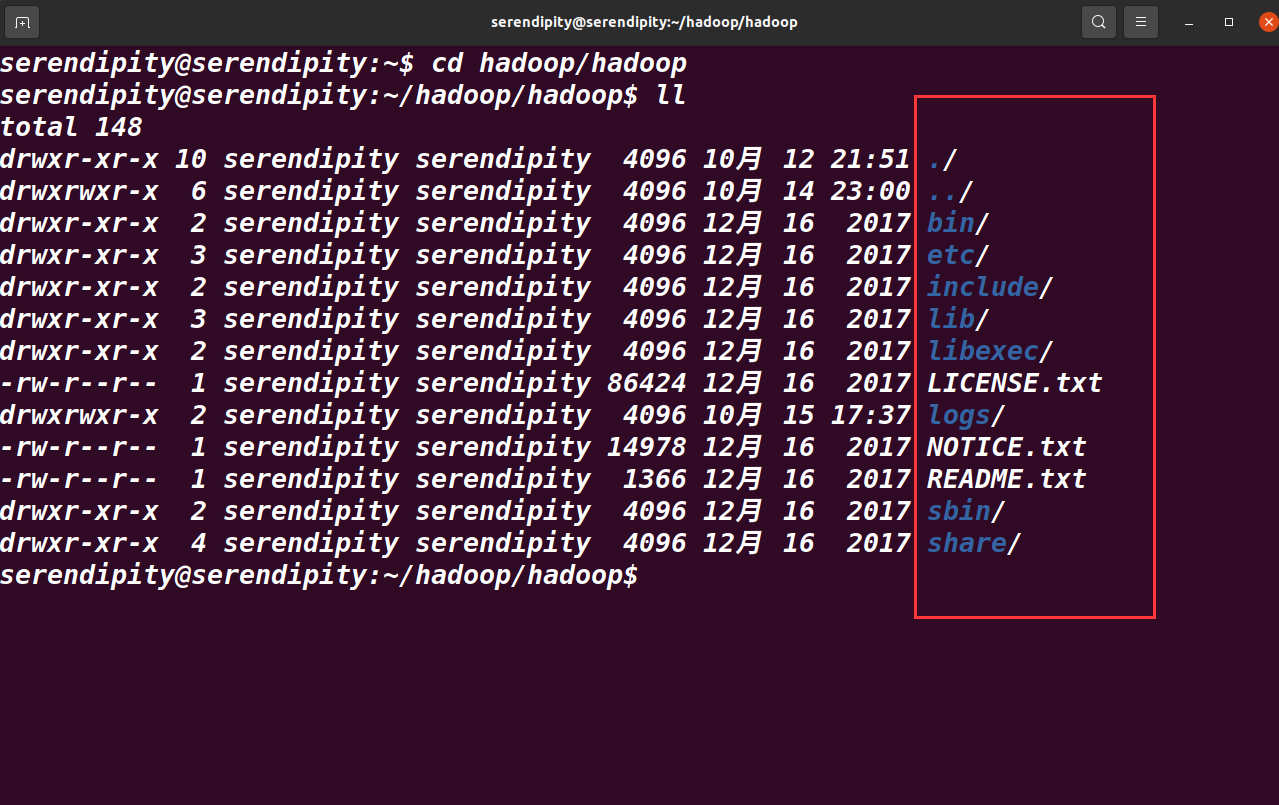
修改配置文件,进入安装目录内的 etc 下的 hadoop 文件夹
cd etc/hadoop/

hadoop-env.sh
sudo vim hadoop-env.sh
再文件较前地方有
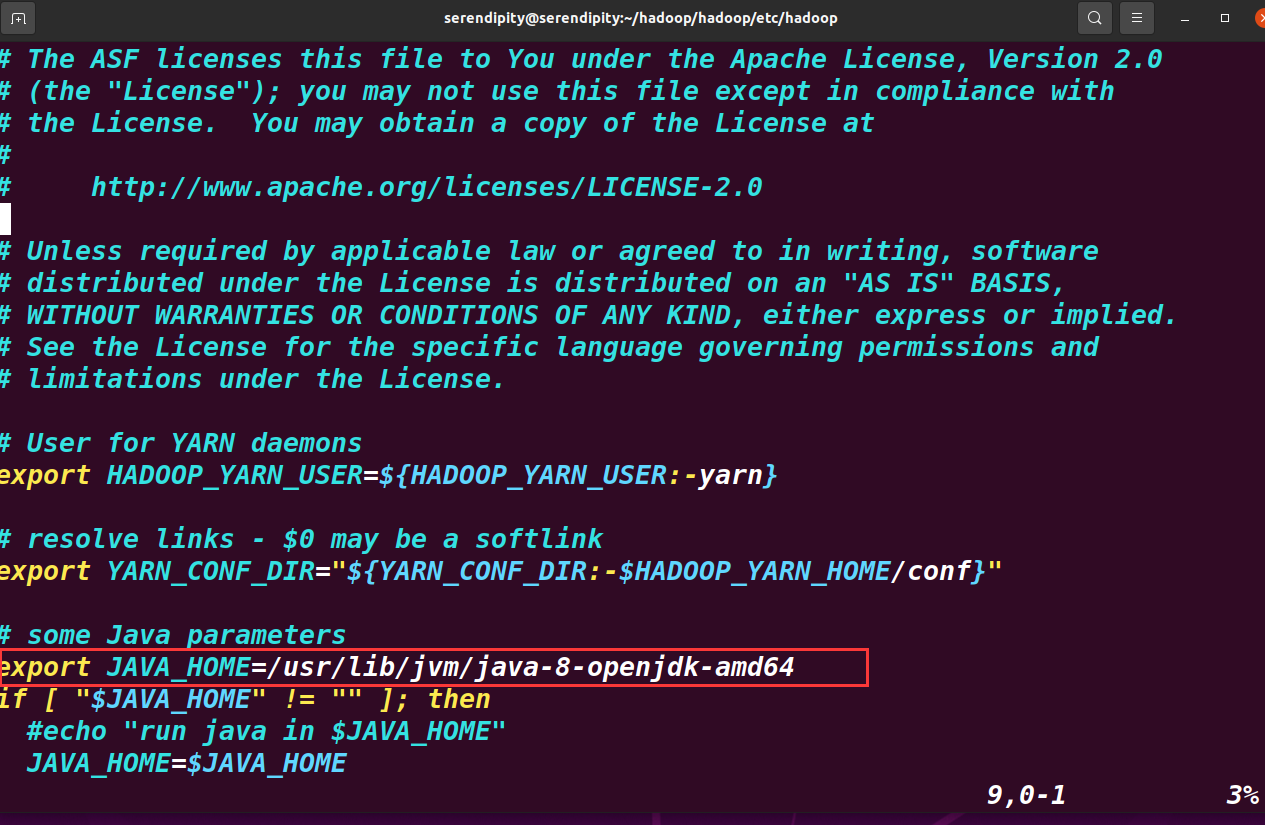
export JAVA_HOME=${JAVA_HOME}
等号后面修改为 你的 JDK 安装目录。

yarn-env.sh
sudo vim yarn-env.sh
再较前面。有个
#export JAVA_HOME=/home/y/libexec/jdk1.6.0
将# 去掉,后面改为你的java安装目录
核心组件 core-site.xml
设置namenode的地址、指定使用Hadoop时临时文件的存放路径等信息
sudo vim core-site.xml
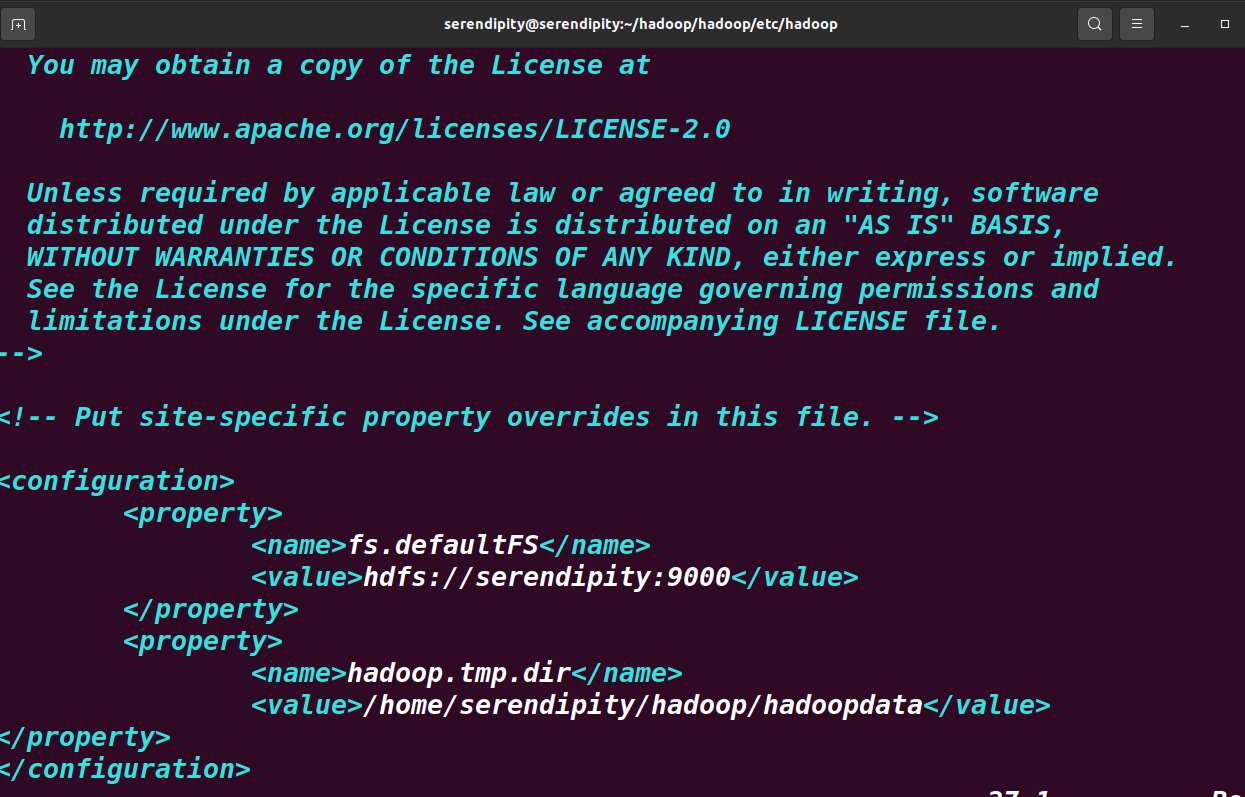
再configuration内部添加如下信息
<property>
<name>fs.defaultFS</name>
<value>hdfs://serendipity:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/serendipity/hadoop/hadoopdata</value>
</property>
其中,hdfs://serendipity:9000 中 serendipity是主机名,可以修改为自己的主机名
/home/serendipity/hadoop/hadoopdata是指定存放数据信息的文件夹,可以自己创建一个文件夹。将其全路径放在这里。
文件系统 hdfs-site.xml
配置分布式文件系统HDFS的属性,包括指定HDFS保存数据的副本数了,指定HDFS中NameNode、DataNode节点的存储位置
sudo vim hdfs-site.xml
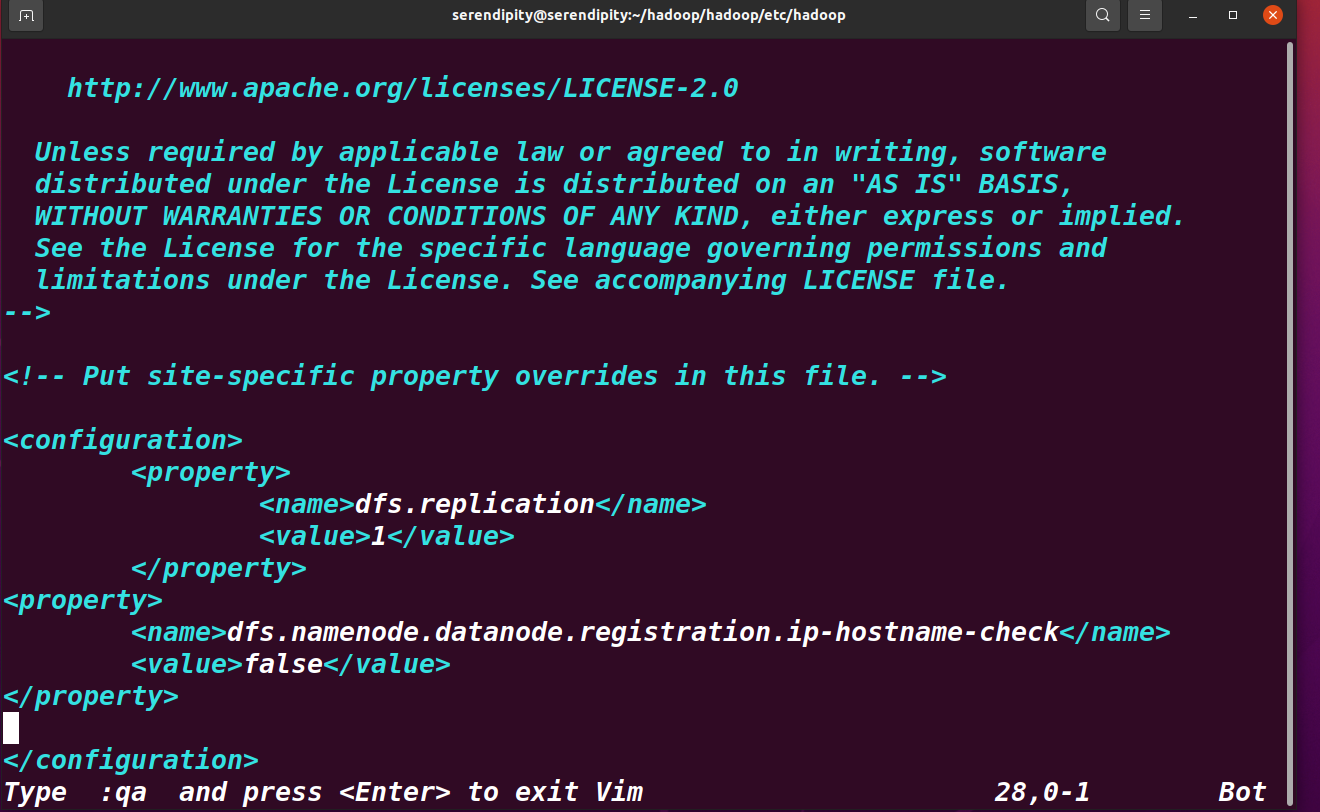
将下面信息加入configuration内部
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
dfs.replication 为执行副本数量
文件系统 yarn-site.xml
yarn是mapreduce的调度框架。
sudo vim yarn-site.xml
将下列信息加入configuration内部,信息不用改,直接抄
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>serendipity:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>serendipity:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>serendipity:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>serendipity:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>serendipity:18088</value>
</property>
计算框架 mapred-site.xml
使用cp命令将 mapred-site.xml.template 复制一份为 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件
sudo vim mapred-site.xml
将下列信息加入configuration内部
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
slaves
配置启动的从机
sudo vim slaves
再内部键入你需要启动的从机的主机名,我只有两个从机,slave01,slave02.所以就写了这两个
将配置的所有hadoop信息复制到从机
scp -r hadoop/hadoop serendipity@slave01:/home/serendipity/hadoop/hadoop
不确定的话,可以将上述安装配置Hadoop的流程,再从机上全部重复一遍,都是一样的操作。
配置环境变量
打开 etc/profile文件
sudo vim /etc/profile
将下面代码追加到文件末尾
export HADOOP_HOME=/home/serendipity/hadoop/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP/sbin
执行命令,激活配置
source /etc/profile
至此。Hadoop安装与配置完毕。
启动Hadoop集群
格式化文件系统
hdfs namenode -format
启动Hadoop集群
将路径切到hadoop安装目录
cd hadoop/hadoop
启动集群
sbin/start-all.sh
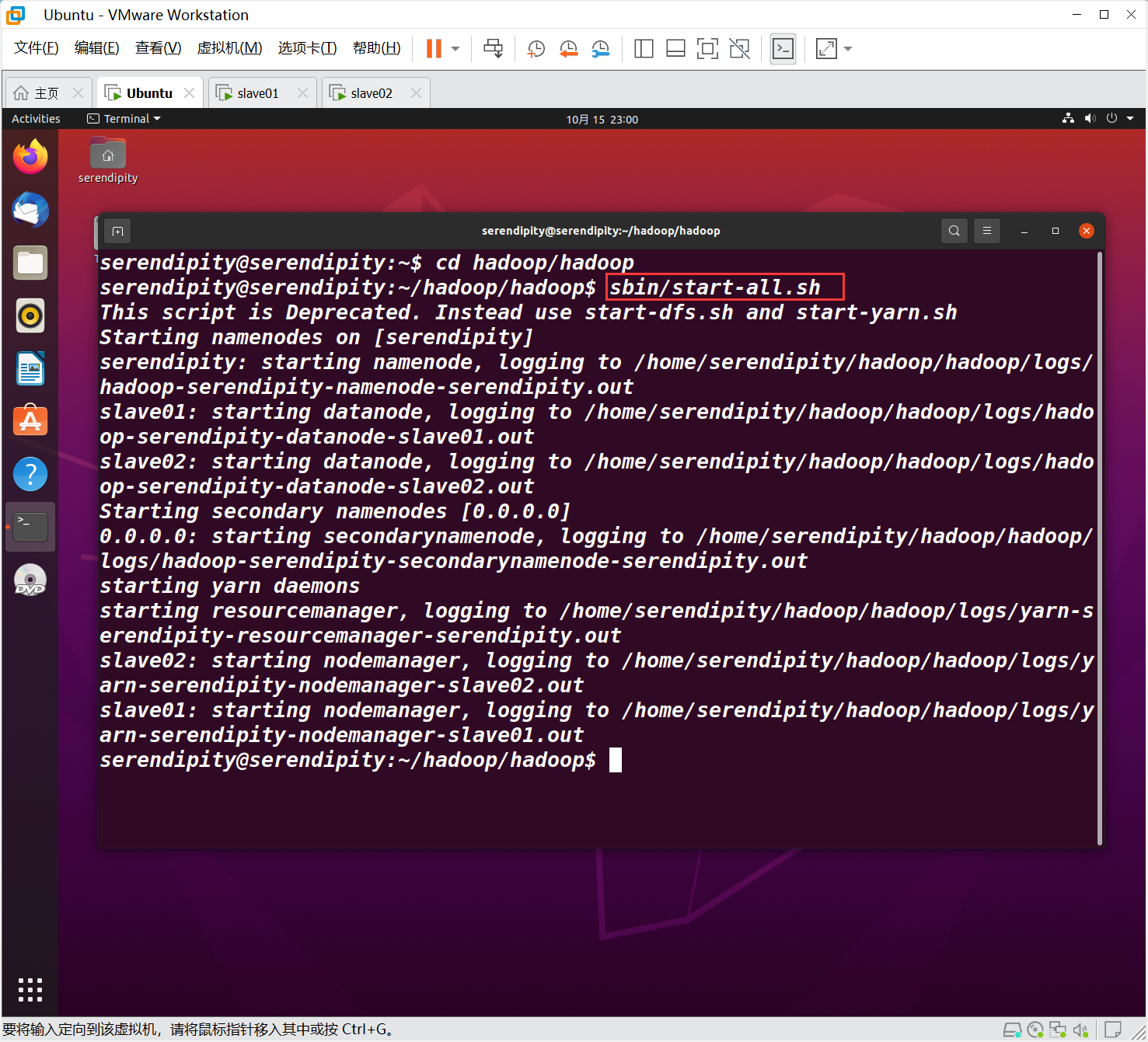
查看Hadoop是否正常启动
在serendipity 执行 jps命令
jps # 查看java进程:java process status??? 可能吧 不知道。

在slave01、slave02执行jps命令

分别如图所示,即Hadoop集群节点已正式启动
在serendipity 查看集群信息
bin/hadoop dfsadmin -report
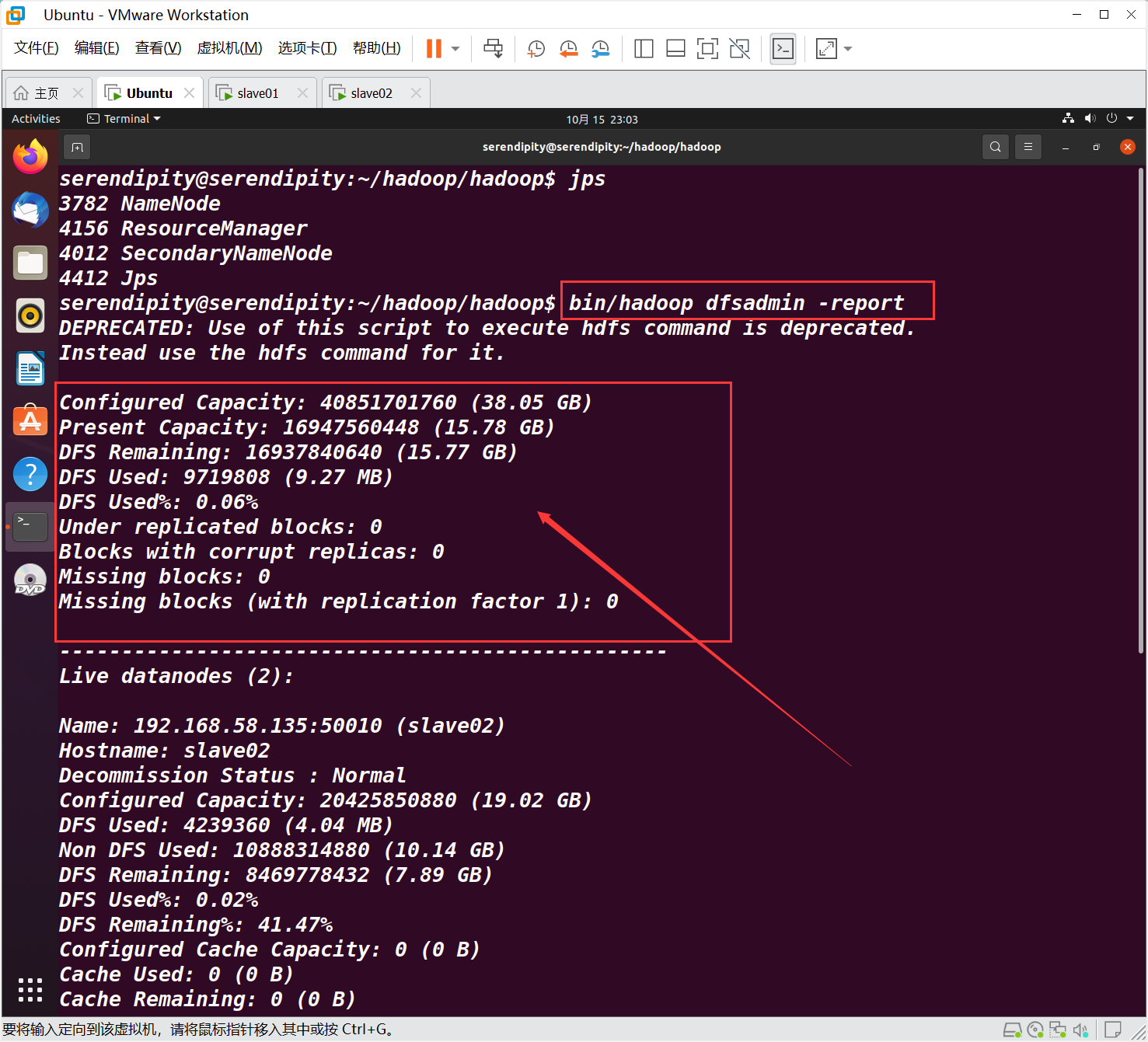
箭头所指区域不全为0 即为正常。
使用web查看集群是否正常,在浏览器地址栏输入:http://serendipity:50070,检查namenode和datanode是否正常
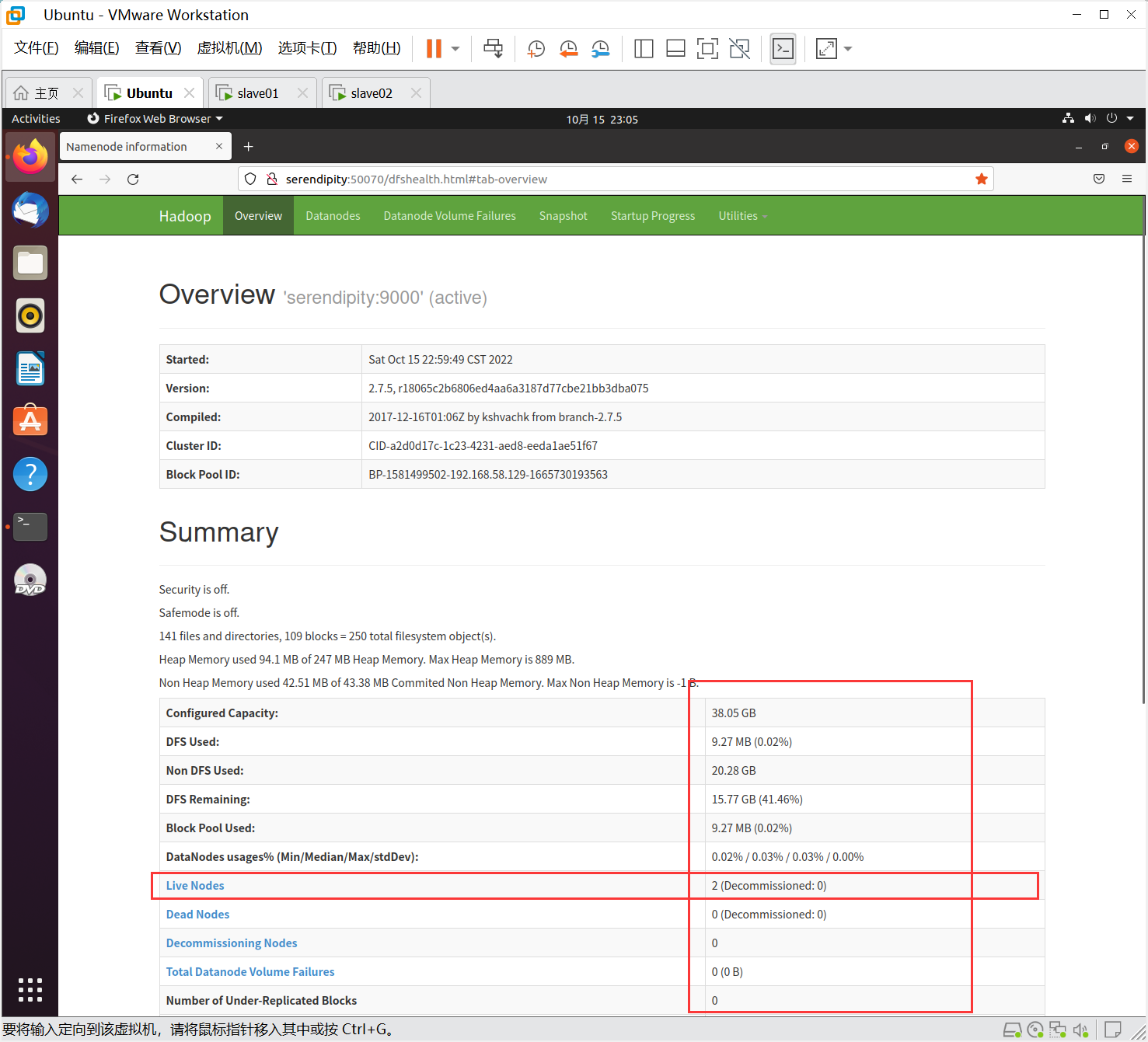
全为0,即集群不是正常状态,尤其是live Nodes节点,一般有几个机器有datanode节点,这里就应该是几。
相关文章
- Clojure的并发(三)Atom、缓存和性能
- Clojure的并发(四)Agent深入分析和Actor
- Clojure的并发(五)binding和let
- Clojure的并发(六)Agent可以改进的地方
- Clojure的并发(七)pmap、pvalues和pcalls
- Tomcat AJP协议包伪造
- Clojure的并发(八)future、promise和线程
- 微软 Visual Studio Code Java 2 月更新发布:支持单元测试、GUI 项目开发、Gradle 项目创建等
- 在 Fedora Linux 上进行 Java 开发
- 并发场景下的底层细节 - 伪共享问题
- HarmonyOS 项目实战之通讯录(Java)
- Java代码审计项目-某在线教育开源系统
- Java开发人员编写SQL时常犯的十个错误
- 简单聊聊Redis中的几种Java客户端,以及它们的优缺点!
- 并发编程的原子性 != 事务ACID的原子性
- Java实战:hutool-db实现多数据源配置
- 频繁插入,用什么存储引擎更合适?
- JVM & MySQL时区配置问题-两行代码让我们一帮子人熬了一个通宵
- 测试开发工程师必备技术栈(附详细技术点)
- 2021 年 Java 开发者生产力报告