
Bloom Filter概念和实现原理
2023-03-31 10:45:21 时间
Bloom Filter概念和实现原理
背景
我们在判断某一个元素是否在某个集合里面时,一般是将集合里面的所有元素都保存下来,然后直接读取磁盘上的数据再进行判断,但是如果数据量很大,此时读取速度就会降低,这时我们可以将数据提前存储到内存中,内存读取速度会快很多,但是数据量在逐渐增大时,内存的开销也在逐渐增大,检索的时间也会变长。此时,在数据量特别大的情况下,需要一个时间和空间上都具有优势的数据结构。
介绍
Bloom Filter是由Howard Bloom在1970年提出的二进制向量数据结构,它具有较好的时间和空间效率,用来检测一个元素是否在某个集合中,但是缺点是,有一定的错误率和删除困难。
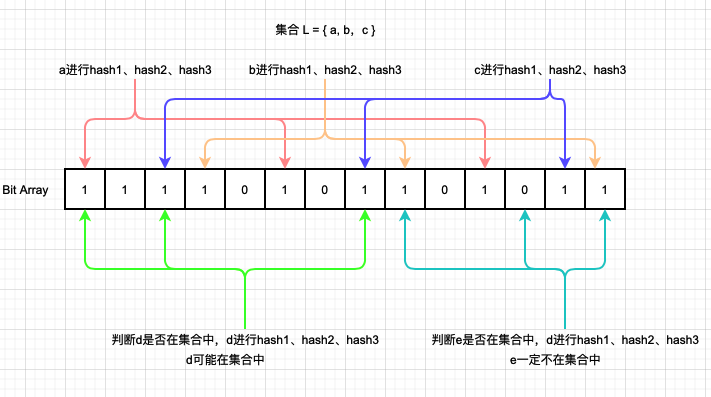
原理
Bloom Filter判断某一个元素是否在集合中时,会将集合中的每一个元素都通过K个不同的Hash函数映射到一个bit数组里面的K个点,每个点设置为1。此时检索一个元素时,只需要将该元素同样进行K个不同的Hash函数,求得K个点位,如果这K个点位全部是1,则代表元素可能在集合里面,如果有一个为0,则代表元素不在集合里面。
公式
-
Bit数组大小的计算
需要根据预估的数据量n以及错误率p来计算Bit数组的大小m:
[m=- frac {n ln {p}} {(ln {2})^2} ] -
Hash函数个数k计算
根据预估的数据量n和已经求得的Bit数组长度m,可以计算出Hash函数的个数k:
[k=frac {m} {n} ln {2} ]
代码实现
/**
* All rights Reserved, Designed By monkey.blog.xpyvip.top
*
* @version V1.0
* @Package PACKAGE_NAME
* @Description:
* @Author: xpy
* @Date: Created in 2022年10月09日 4:42 下午
*/
public class Test {
public static void main(String[] args) {
System.out.println(calNumOfBits(3,0.1));
System.out.println(calNumOfHashFuns(3, 14));
}
/**
* 计算bit数组大小m
* @param n 预估的数据量
* @param p 错误率 在0-1之间 0<p<1
* @return
*/
private static long calNumOfBits(long n, double p){
if(p == 0){
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算最佳需要多少个hash函数,即k值
* @param n 预估的数据量
* @param m bit数组大小m
* @return
*/
private static int calNumOfHashFuns(long n, long m){
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
实际Bloom Filter使用
-
使用hutool里面的Bloom Filter
/** * All rights Reserved, Designed By monkey.blog.xpyvip.top * * @version V1.0 * @Package PACKAGE_NAME * @Description: * @Author: xpy * @Date: Created in 2022年10月09日 4:42 下午 */ public class Test { public static void main(String[] args) { BitMapBloomFilter bitMapBloomFilter = new BitMapBloomFilter(8); bitMapBloomFilter.add("test123"); bitMapBloomFilter.add("tset123456"); System.out.println(bitMapBloomFilter.contains("test123")); System.out.println(bitMapBloomFilter.contains("test12")); } } -
使用Google的guava包
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import java.nio.charset.Charset; /** * All rights Reserved, Designed By monkey.blog.xpyvip.top * * @version V1.0 * @Package PACKAGE_NAME * @Description: * @Author: xpy * @Date: Created in 2022年10月09日 4:42 下午 */ public class Test { public static void main(String[] args) { // 设置预估的数据量在1000000,错误率在0.01 BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000000, 0.01); bloomFilter.put("test123"); bloomFilter.put("test123456"); bloomFilter.put("tset123456"); System.out.println(bloomFilter.mightContain("test123456")); System.out.println(bloomFilter.mightContain("tset12")); } }
扩展
-
错误率
Bloom Filter存在判断错误的情况,适用于允许存在判断错误的场景。
-
不允许删除
删除其中某一个元素,需要将该元素对应的bit位设置为0,但是很可能有其他元素对应,所以不能删除,设置为0。
原文链接:https://monkey.blog.xpyvip.top/archives/bloomfilter-gai-nian-he-shi-xian-yuan-li
相关文章
- 从本体论开始说起——运营商关系图谱的构建及应用
- 如何成为一名数据科学家?
- 从未见过的堂兄杀了人,你的DNA是关键证据
- 20个安全可靠的免费数据源,各领域数据任你挑
- 20个安全可靠的免费数据源,各领域数据任你挑
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假