


论文地址:https://arxiv.org/abs/2106.02898
该论文指出识别每张图片所需要的最小分辨率是不同的,而现有方法并没有充分挖掘输入分辨率的冗余性,也就是说输入图片的分辨率不应该是固定的。论文进一步提出了一种动态分辨率网络 DRNet,其分辨率根据输入样本的内容动态决定。一个计算量可以忽略的分辨率预测器和我们所需要的图片分类网络一起优化训练。在推理过程中,每个输入分类网络的图像将被调整到分辨率预测器所预测的分辨率,以最大限度地减少整体计算负担。
实验结果表明,在 ImageNet 图像识别任务中,DRNet 与标准 ResNet-50 相比,在相似准确率情况下,计算量减少了约 34%;在计算量减少 10% 的情况下,精度提高了 1.4%。
引言
随着算法、计算能力和大规模数据集的快速发展,深度卷积网络在各种计算机视觉任务中取得了显著的成功。然而,出色的性能往往伴随着巨大的计算成本,这使得 CNN 难以在移动设备上部署。随着现实场景对于 CNN 的需求不断增加,降低计算成本的同时维持神经网络的准确率势在必行。
近年来,研究人员在模型压缩和加速方法方面投入了大量精力,包括网络剪枝、低比特量化、知识蒸馏和高效的模型设计。然而,大多数现有的压缩网络中输入图像的分辨率仍然是固定的。一般而言,深度网络使用固定统一的分辨率(例如,ImageNet 上的 224 X 224)进行训练和推理,尽管每张图片中目标的大小和位置完全不同。
不可否认,输入分辨率是影响 CNN 计算成本和性能的一个非常重要的因素。对于同一个网络,更高的分辨率通常会导致更大的 FLOPs 和更高的准确率。相比之下,输入分辨率较小的模型性能较低,而所需的 FLOP 也较小。然而,缩小深度网络的输入分辨率为我们提供了另一种减轻 CNN 计算负担的可能性。
为了更清晰地说明,研究者首先使用一个预训练的 ResNet-50 测试不同分辨率下的图像,如下图 1 所示,并计算和展示每个样本给出正确预测所需要的最小分辨率。对于一些简单的样本,如左侧图前景熊猫,可以准确地在低分辨率和高分辨率下被识别出来。然而对于一些难样本如右侧图的昆虫,目标被遮挡或者跟别的物体混合,只能通过高分辨率识别。
这一观察表明,数据集中很大一部分图片可以降低分辨率来识别。另一方面,这也和人类的感知系统一致,即一些样本在模糊情况下可以被很好地识别,而另外一些在清晰的条件下才能有效识别。

图 1:在不同输入分辨率 (112X112、168X168 和 224X224) 下 ResNet-50 模型的预测结果
在本文中,研究者提出了一种新颖的动态分辨率网络(DRNet),它动态调整每个样本的输入分辨率以进行有效推理。为了准确地找到每张图像所需的最小分辨率,他们引入了一个嵌入在分类网络前面的分辨率预测器。
在实践中,研究者将几个不同的分辨率设置为候选分辨率,并将图像输入分辨率预测器以生成候选分辨率的概率分布。分辨率预测器的网络架构经过精心设计,计算复杂度可以忽略不计,并与分类器联合训练,以端到端的方式进行识别。通过利用所提出的动态分辨率网络推理方法,研究者可以从每个图像的输入分辨率中挖掘其冗余度。这样做不仅可以节省具有较低分辨率的简单样本的计算成本,并且还可以通过保持较高的分辨率来保持难样本的准确性。
在大规模数据集和 CNN 架构上的大量实验证明了研究者提出的方法在降低整体计算成本和提升网络准确率方面的有效性。例如,DR-ResNet-50 仅用 3.7G FLOPs 就达到了 77.5% 的 ImageNet top-1 准确率,这比计算量多 10% 的 ResNet-50 高出了 1.4%。
方法
整体架构
研究者提出了一种实例感知的分辨率选择方法,为大型分类器网络选择输入图像的分辨率。这种方法包含了两个组件,第一个是大型分类器网络,例如 ResNet,它的特点是准确率高和计算成本高。第二个是分辨率预测器,它的目标是找到一个最小的分辨率,这样能为预测每张输入图片来平衡准确率和效率。
对于任意的输入图片,研究者首先用分辨率预测器来预测其合适的分辨率 r。然后,大型分类器网络将 resized 后的图像作为输入。这样,当 r 小于原始分辨率时,FLOPs 就会大幅度减少。两种网络在训练时是端到端一起训练的,如下图 2 所示。
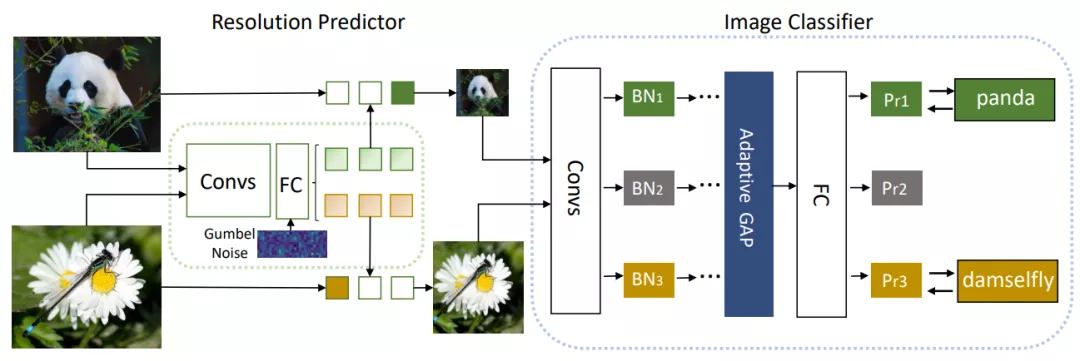
图 2:模型整体结构图
分辨率预测器
分辨率预测器的设计是基于 CNN 的。分辨率预测器的目标是通过得到一个概率分布来找到一个合适的分辨率。这里研究者提供 m 个候选分辨率以供分辨率预测器挑选。考虑到分辨率预测器会带来额外的计算消耗,所以在设计分辨率预测器时只保留了很少的卷积层和全连接层。
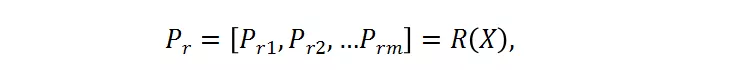
其中,X 是输入的样本,被送入分辨率预测器。P_r 是预测器的输出,其代表了每个候选的概率。候选分辨率中对应的最高概率的那个分辨率将被选为送入大分类器的图片的分辨率。这里采用了 Gumbel-Softmax 来实现这种选择过程,将其转变成是可微分的:
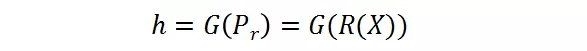
分辨率感知的批正则化(BN)
BN 常用于使得深度模型收敛得更快更稳定。然而不同分辨率下的激活统计值 (activation statistics) 包含了均值和方差,这使得它们不兼容。实验表明,使用不同的分辨率下的共享的 BN 会导致更低的准确率。考虑到 BN 层只包含了可忽略不计的参数,研究者提出分辨率感知的批正则化,即对于不同的分辨率,使用他们对应的 BN 层。
训练优化
分类网络与分辨率预测器同时进行训练优化。损失函数包含了交叉熵损失函数和研究者提出的 FLOPs 损失函数。FLOPs 损失函数用于限制计算量。
给定一个预训练好的分类网络
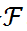
。输入 X 并输出概率
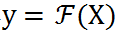
以用于图像分类。对于输入 X,研究者首先将其 resize 成 m 个候选分辨率 X_r1, X_r2,... , X_rm,然后使用分辨率预测器对每张图片产生分辨率概率矢量 P_rR^m。然后软分辨率概率 P_r 被转变成硬的独热选择 h ϵ{0,1}^m,使用 Gumbel-Softmax。h 代表了每个样本的分辨率选择。在实践中,他们首先获得了对于每个分辨率的最终的预测 y_rj=F(X_rj),然后将其通过 h 加起来:
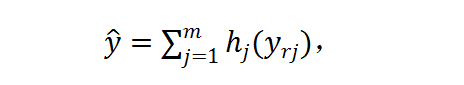
交叉熵损失函数
将在预测 ^y 和标签 y 之间执行:
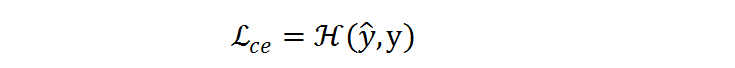
梯度被反向传播到分类网络和分辨率预测器以同时优化。
如果只使用交叉熵损失函数,分辨率预测器将会收敛到一个次优点,并倾向于选择最大的分辨率,因为最大的分辨率往往对应着更低的分类损失。为了减少计算量,研究者提出了一个 FLOPs constraint regularization 去指导分类预测器的学习:
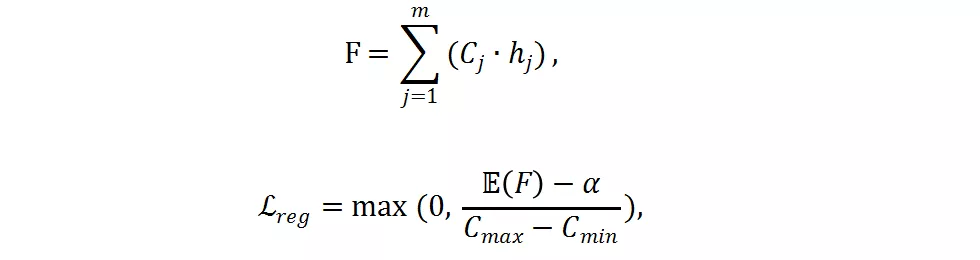
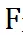
是实际 FLOPs,C_j 是预先计算好的第 j 个分辨率的 FLOPs,
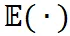
是在样本层面的期望值,
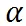
是目标 FLOPs。经过这个正则,如果平均 FLOPs 值过大,将会有一个惩罚,促使提出的分辨率预测器高效且准确。最终,整个损失函数是两者加权和:
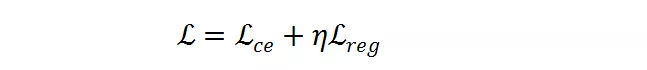
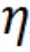
是超参数以用于平衡
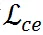
和
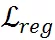
的幅度。
Gumbel Softmax 可以使得离散的 decision 在反向传播中可微。对于前述概率值 P_r = [p_r1, p_r2, , p_rm],离散的候选分辨率选择可以由此得到:
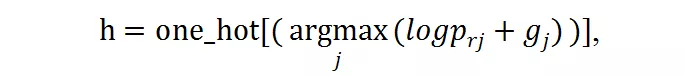
g_j 是 gumbel noise,由下式得到:
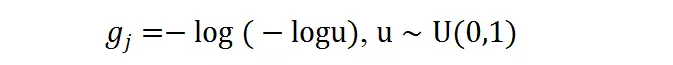
在训练过程中,独热操作的求导可以由 gumbel softmax 近似,其中
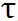
是温度系数:
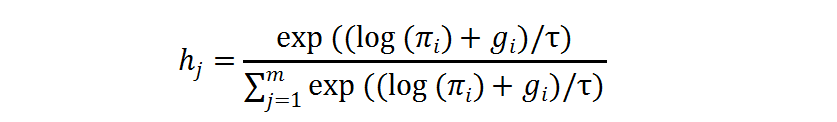
实验
研究者在 ImageNet-1K 和 ImageNet-100 数据集上训练和验证 DRNet 模型,其中 ImageNet-100 是 ImageNet-1K 的子集。
ImageNet-100 实验
从下表 1 可以看出,在 ImageNet-100 数据集上,DRNet 相比于 ResNet-50,减少了 17% 的 FLOPs,同时获得了 4.0% 的准确率提升。当调整超参数和时,可以减少 32% 的 FLOPs 并提升 1.8% 准确率。另外,采用分辨率感知的 BN 获得了性能提升而 FLOPs 相似。
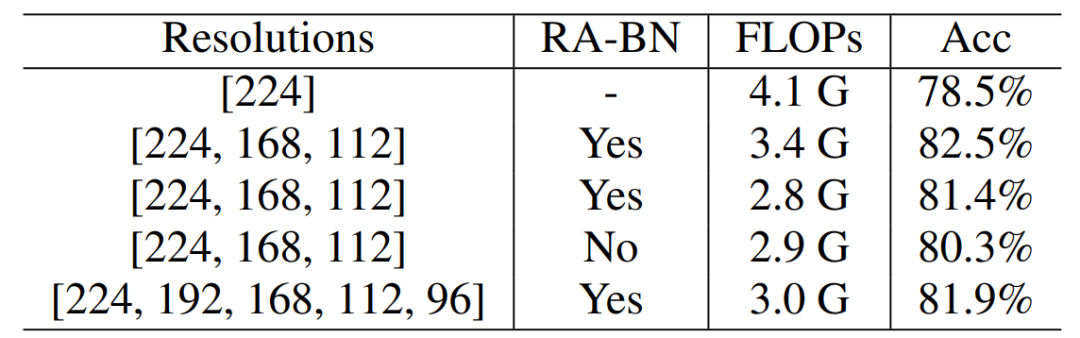
表 1 :ResNet-50 骨干网络在 ImageNet-100 上的结果
下表 2 中,研究者进一步减少,可以获得 44% 的 FLOPs 减少而准确率还是增加。
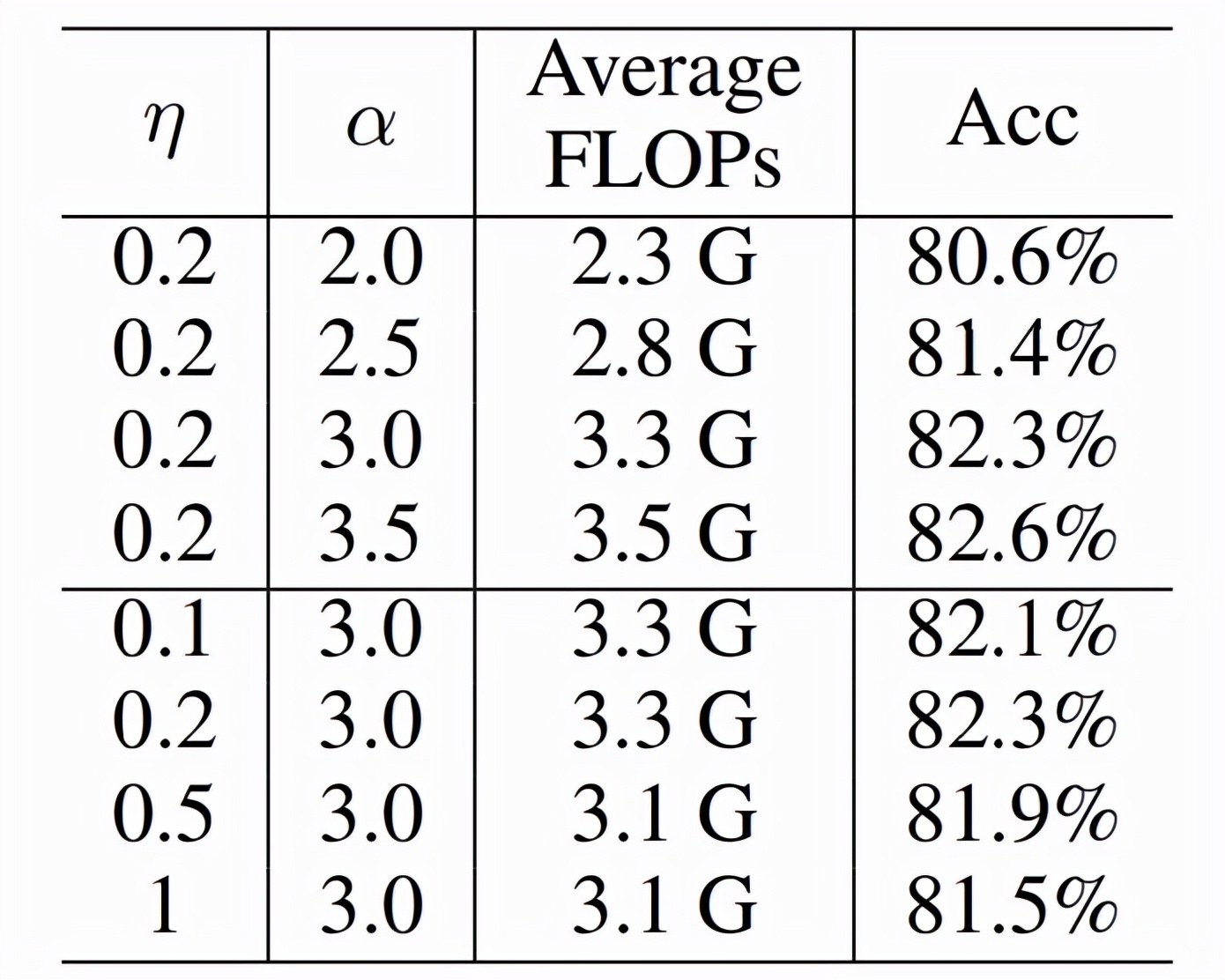
表 2 :FLOPs Loss 的影响
ImageNet-1K 实验
研究者在 ImageNet-1K 上进行大规模实验,发现 DR-ResNet-50 减少了 10% 的 FLOPs,性能提升 1.4%,如下表 3 所示。
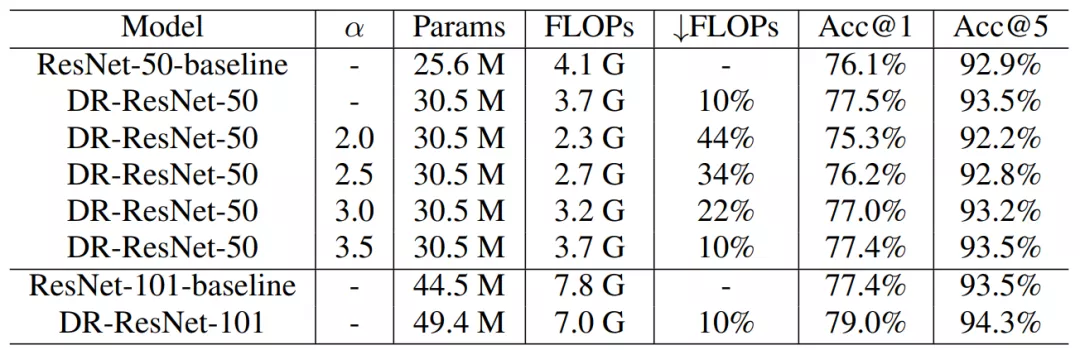
表 3 :ResNet-50 和 ResNet-101 在 ImageNet-1K 上的结果
与其他方法的结果比较见下表 4。
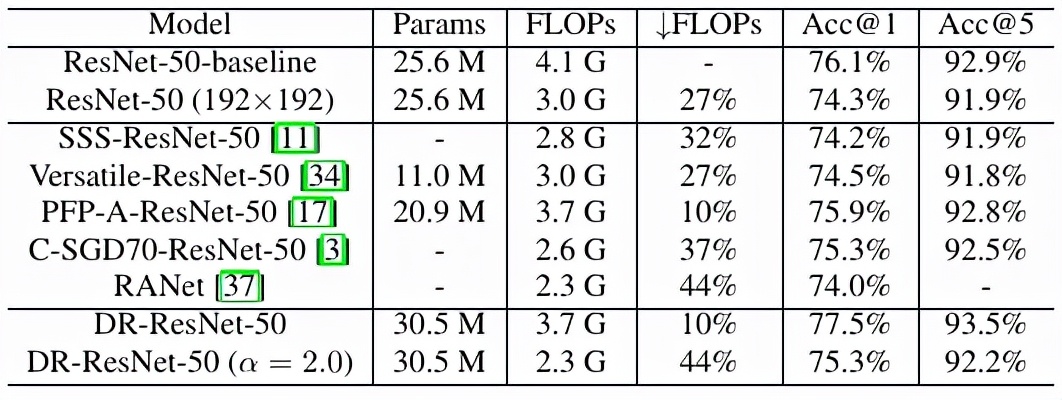
表 4:和其他模型压缩方法的比较
为了验证所提出的动态分辨率机制的作用,研究者对比了 DR-ResNet-50 和随机选择机制的性能,见下表 5。
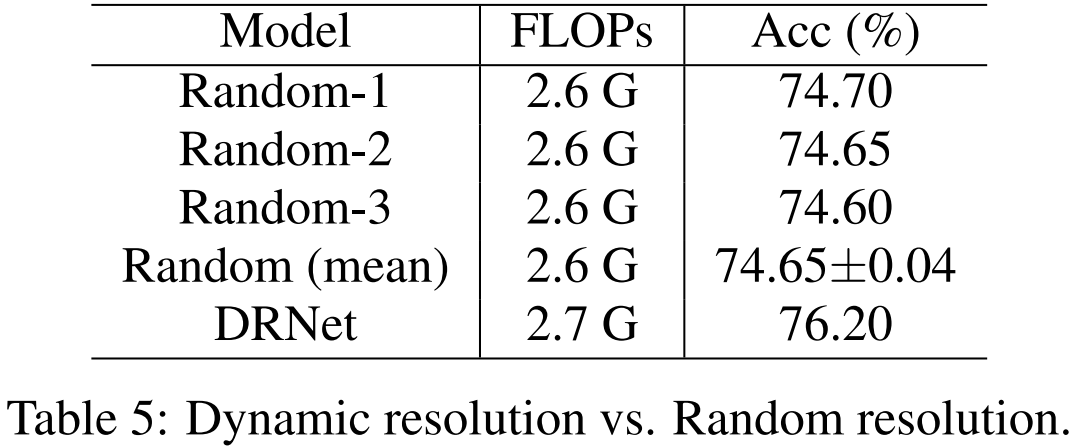
表 5:动态分辨率与随机分辨率对比
下图 3 展示了实际情况下测速,表明该方法比 ResNet-50 优越。
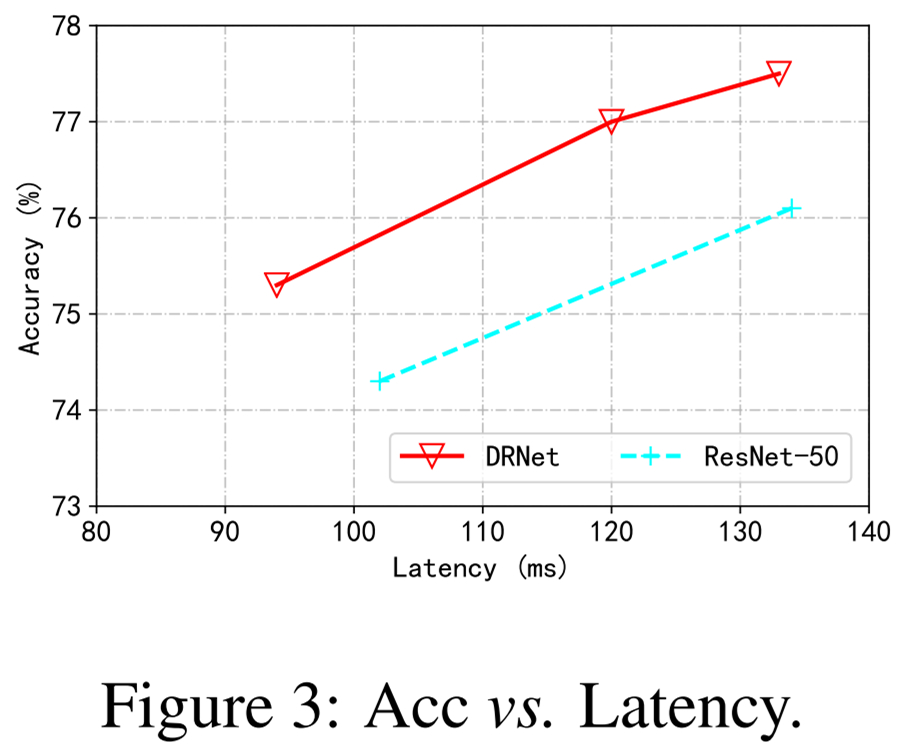
图 3:准确率和 Latency 对比
下表 6 则将骨干模型从 ResNet 扩展到了 MobileNet,并展示了其有效性。
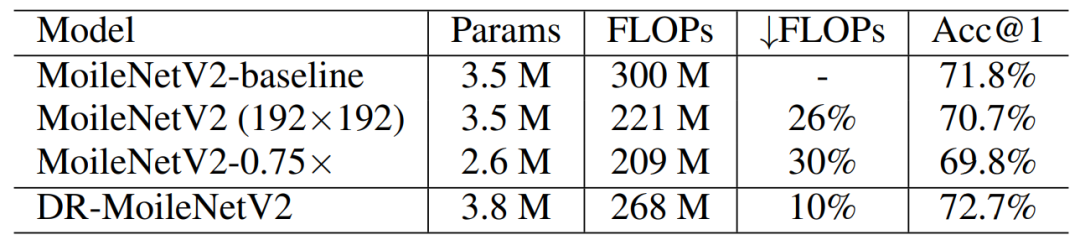
表 6:MoblieNet V2 结果
下图 4 展示了 DRNet 的预测结果可视化,可以看到,视觉上更难识别的图像往往被预测为使用更高的分辨率,反之则是更低的分辨率。

图 4:图片可视化结果