
引入多感官数据学习,华人学者摘得2021 UT-Austin最佳博士论文奖

在本年度的评选中,华人学者 Ruohan Gao 的博士学位论文《Look and Listen: From Semantic to Spatial Audio-Visual Perception》获得了 Michael H. Granof 奖。

杰出博士论文奖设立于 1979 年,旨在表彰出色的研究以及鼓励最高的研究、写作、学术水平。每年颁发三个奖项,其中一篇会被选中获得该校的最佳论文奖「Michael H. Granof 奖」。杰出论文奖获得者将获得 5000 美元奖金,Granof 奖获得者获得 6000 美元奖金。
Ruohan Gao

Ruohan Gao2015 年于香港中文大学(CUHK)信息工程系获得一等荣誉学位,导师为刘永昌(Wing Cheong Lau)教授。
博士期间,Ruohan Gao 师从 Kristen Grauman 教授。他的研究兴趣是计算机视觉、机器学习、数据挖掘等,特别是视频中的多模态学习和多模态下的 embodied learning。2021 年初,Ruohan Gao 从德克萨斯大学奥斯汀分校获得博士学位。
目前,Ruohan Gao 是斯坦福大学视觉与学习实验室(SVL)的博士后研究员。
此外,Ruohan Gao 还获得过谷歌博士生奖研金(Google Ph.D Fellowship)、Adobe 研究奖研金(Adobe Research Fellowship)等荣誉。
这篇论文研究了什么?

论文链接:https://ai.stanford.edu/~rhgao/Ruohan_Gao_dissertation.pdf
理解场景和事件本质上是一种多模态经验。人们通过观察、倾听 (以及触摸、嗅和品尝) 来感知世界,特别是物体发出的声音,无论是主动产生的还是偶然发出的,都提供了关于自身物理属性和空间位置的有价值的信号,正如钹在舞台上撞击,鸟在树上鸣叫,卡车沿着街区疾驰,银器在抽屉里叮当作响……
尽管通过「看」,也就是根据物体、行为或人的外表检测的识别取得了重大进展,但它往往不能够「听」。在这篇论文中,作者证明了与视觉场景和事件同步的音频可以作为丰富的训练信号来源,用于学习 (视听) 视觉模型。此外,作者开发了计算模型,利用音频中的语义和空间信号,从连续的多模态观测中理解人、地点和事物。
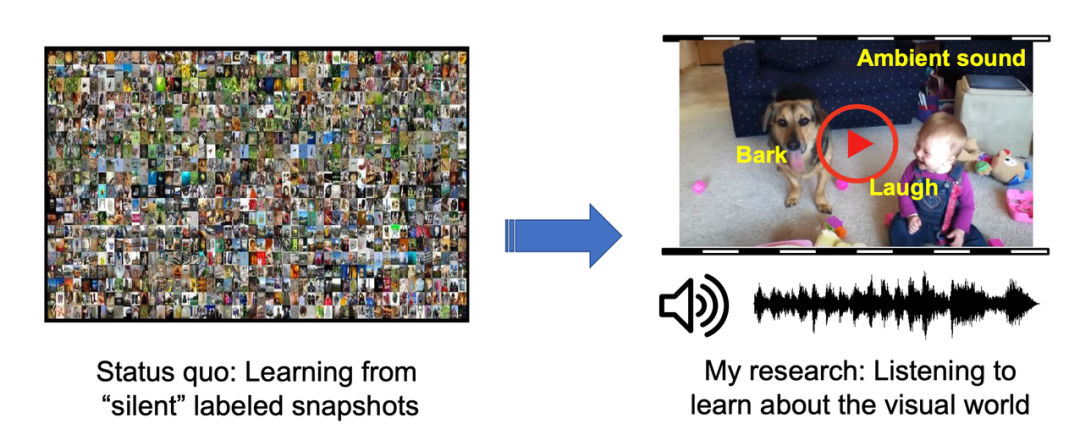
当前大多数计算机视觉系统的现状是从大量「无声」数据集的标记图像中学习,而该论文研究目标是既要会倾听,又要了解视觉世界。
作者表示,受到人类利用所有感官对世界进行感知的启发,自己的长期研究目标是建立一个系统,通过结合所有的多感官输入,能够像人类一样感知世界。在论文的最后一章,作者概述了在此博士论文之外希望追求的未来研究方向。
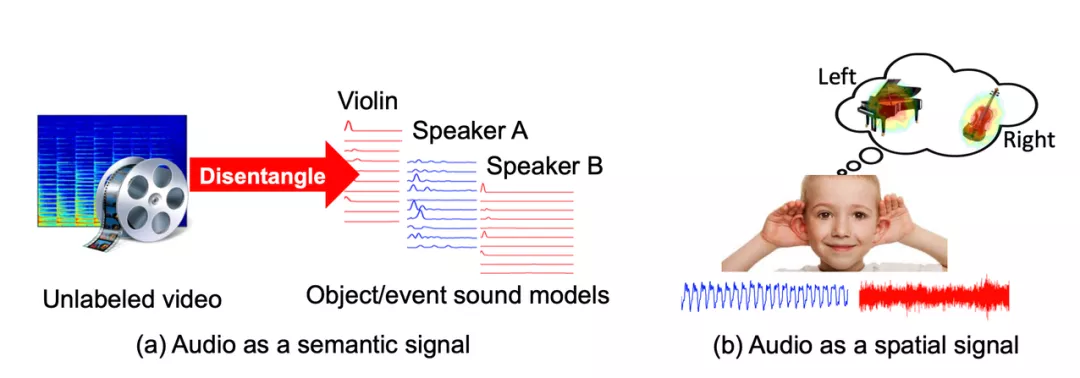
图 1.2: 音频本身是一个监督信号,用于语义和空间理解。
研究的首要目标是从视频和嵌入智能体中复现视听模型: 当多个声源存在时,算法如何知道发声对象是什么以及在哪里?这些视听模型如何在传统的视听任务有所提升?为了解决这些问题,该研究利用了音频中的语义和空间信号,从连续的多模态观测中理解人、地点和事物(图 1.2)。
这篇论文研究了以下四个重要问题,以逐步接近视听场景综合理解的最终目标:
- 同时观看和聆听包含多个声源的未标记视频,以学习音视频源分离模型(第 3 章、第 4 章和第 5 章);
- 利用音频作为预览机制,在未修剪的视频中实现高效的动作识别(第 6 章);
- 利用未标记视频中的视觉信息推断双耳音频,将平面单声道音频「提升」为空间化的声音(第 7 章);
- 通过回声定位学习空间图像表征,监测来自与物理世界的声学互动(第 8 章)。
作者表示,本论文对视听学习的研究,体现了无监督或自监督的多感官数据学习对人工智能的未来发展具有积极而重要的意义。
更多细节请参见论文原文。
相关文章
- 一篇运维老司机的大数据平台监控宝典(2)-联通大数据集群平台监控体系详解
- 一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解
- 空中换引擎 博时基金数字化转型经验谈
- 如何高效地学习编程语言
- 作为一名阿里巴巴数据分析大牛,送给学弟学妹的经验积分
- 为什么要学习R语言
- Hadoop大数据分析平台的介绍性讨论
- 最全面的Spring学习笔记
- 16个用于数据科学和机器学习的顶级平台
- 给有抱负的数据科学家的六条建议
- 如何做一枚合格的数据产品经理
- 除Kaggle外,还有哪些顶级数据科学竞赛平台
- 一个鲜为人知却可以保护隐私的训练方法:联合学习
- 干货 :送你12个关于数据科学学习的关键提示(附链接)
- 大数据行业有多少种工作岗位,各自的技能需求是什么?
- 中国移动研究院常耀斌:商用大数据平台的研发之路
- 这些数据科学家必备的技能,你拥有哪些?
- 自学成才的开发者有何优势和劣势?
- Gartner报告:正处于数据科学与机器学习工具 “大爆炸”的时代
- Ready Computing借助InterSystems IRIS医疗版为医疗机构提供具有高度互操作性和可扩展性的解决方案