
Intel超级GPU计算卡亮相:六十三个小芯片合体、六百瓦功耗
ISSCC 2022国际固态电路会议期间,Intel不但公布了初代“矿卡”的细节,还深入介绍了Ponte Vecchio计算加速卡的情况。Ponte Vecchio计算加速卡是基于Xe HPC高性能计算架构的第一款产品,专门面向超级计算机,将在今年晚些时候按计划出货,首批供给美国能源部的超算“Aurora”。
Intel此前曾经披露过,它使用了5种不同的制造工艺,内部封装多达47个芯片/单元(Tile),晶体管数量突破1000亿个。

根据最新资料,Ponte Vecchio整体面积达77.5×62.5=4844平方毫米,多达4468个针脚,采用了特殊的空腔封装(Cavity Package),共有四个186平方毫米的空腔,共分为24层(11-2-11的布局),还有11个2.5D互连通道。
它通过Foveros、EMIB等先进封装技术,集成了总共多达63个Tile,其中47个是功能性的,包括16个计算单元、8个RAMBO缓存单元、2个Foveros封装基础单元、8个HBM2E单元、2个Xe链路单元、11个EMIB互连单元,总面积2330平方毫米。
它们还负责提供内存控制器、FIVR、电源管理、16条PCIe 5.0、CXL。
另外还有16个Tile,是专门是辅助散热的,总面积770平方毫米,合计达到了惊人的3100平方毫米。
为什么设置这么多散热Tile?因为整体功耗达到了恐怖的600W!
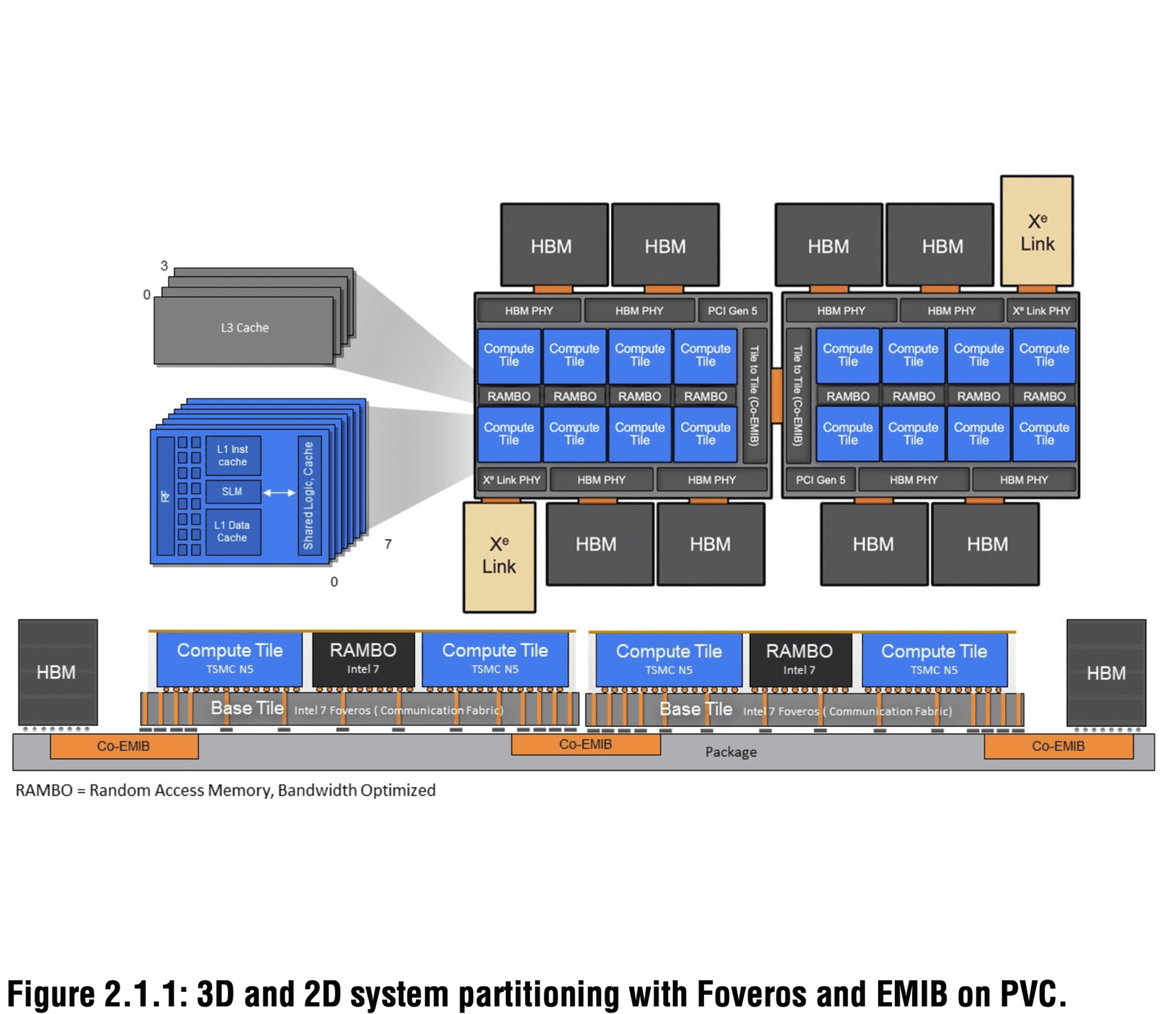
这是不同Tile布局的顶视图、侧视图。
蓝色的是核心计算单元,台积电N5 5nm工艺制造,每个集成8个Xe核心、4MB一级缓存。
位于计算单元中间的,是特殊的RAMBO缓存,可以称之为三级缓存,Intel 7工艺制造(10nm ESF),是一种专门针对高带宽优化的RAM缓存,每个TIle 15MB,合计120MB。
承载它们的是基础单元(Base Tile),负责通信传输,Intel 7工艺加Foveros封装,面积646平方毫米,共有17层。
基础单元和HBM2E高带宽内存、Xe Link链路单元之间,则通过Co-EMIB来封装、通信,其中Xe Link链路单元是台积电N7 7nm工艺,负责链接不同的Ponte Vecchio GPU。
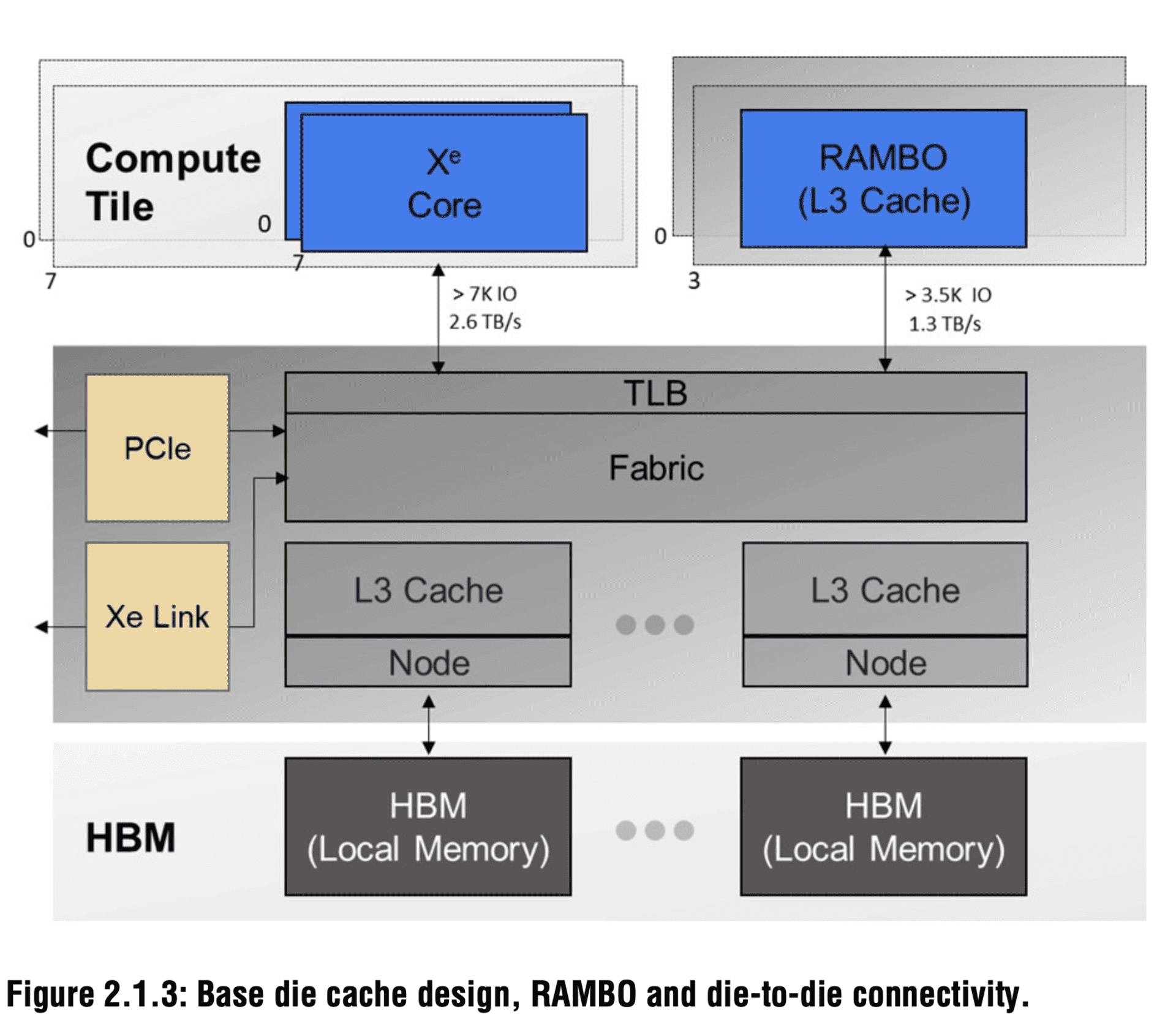
带宽方面,计算单元对外高达2.6TB/s,RAMBO缓存对外则是1.3TB/s。
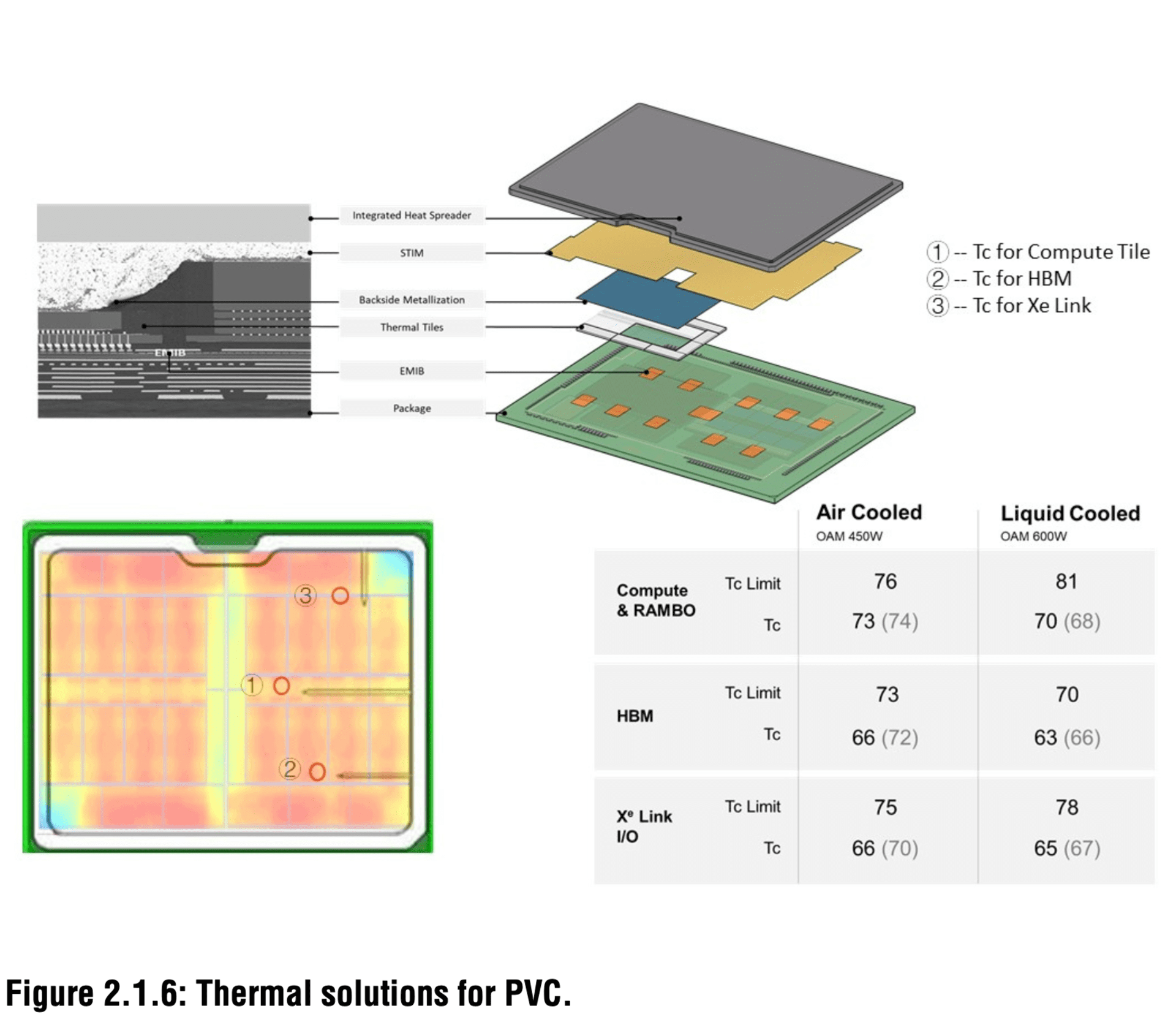
Ponte Vecchio其实有两种功耗指标,风冷下最高450W,水冷最高才是600W。
风冷模式下,计算单元、RAMBO缓存、HBM内存、Xe Link等不同部位的最高允许温度66-73℃不等,水冷模式下则是63-70℃。


相关文章
- 从本体论开始说起——运营商关系图谱的构建及应用
- 如何成为一名数据科学家?
- 从未见过的堂兄杀了人,你的DNA是关键证据
- 20个安全可靠的免费数据源,各领域数据任你挑
- 20个安全可靠的免费数据源,各领域数据任你挑
- 阿里云李飞飞:All in Cloud时代,云原生数据库优势明显
- 基于Hadoop生态系统的一高性能数据存储格式CarbonData(性能篇)
- 大数据告诉你:10年漫威,到底有多少角色
- TigerGraph:实时图数据库助力金融风控升级
- Splunk利用Splunk Connected Experiences和Splunk Business Flow 扩大数据访问
- 大数据开发常见的9种数据分析手段
- 以免在景区看人,我爬了5W条全国景点门票数据...
- 【实战解析】基于HBase的大数据存储在京东的应用场景
- 数据科学家告诉你哪些计算机科学书籍是你应该看的
- Kafka作为大数据的核心技术,你了解多少?
- Spring Boot 整合 Redis 实现缓存操作
- 大数据学习必须掌握的五大核心技术有哪些?
- 基于Antlr在Apache Flink中实现监控规则DSL化的探索实践
- 甲骨文再次被Gartner评为分析型数据管理解决方案魔力象限领导者
- 爬取吴亦凡微博102118条转发数据,扒一扒流量的真假