
(数据科学学习手札95)elyra——jupyter lab平台最强插件集
本文示例文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
jupyter lab是我最喜欢的编辑器,在过往的文章中也给大家介绍过很多相关资源和实用插件,但本文要给大家介绍的jupyter lab插件elyra,绝对是我使用过的最强大的jupyter lab插件没有之一,因为它的核心功能就是帮助我们解决数据分析工作中非常重要的问题——搭建工作流。

2 利用elyra搭建工作流
在安装elyra插件集之前,请确保你的jupyter lab版本在2.0及以上,并且已经安装好了nodejs也就是所有jupyter lab拓展插件都需要的依赖。
不像常规的jupyter lab插件的安装方法,我们执行下列命令即可安装elyra下集成的多个插件:
pip install --upgrade elyra && jupyter lab build
安装完之后,你的jupyter lab操作界面外观会发生一些变化,我们先记住在安装elyra之前我们的jupyter lab界面长啥样(我使用的主题感兴趣的朋友可以通过jupyter labextension install jupyterlab-tailwind-theme来安装):
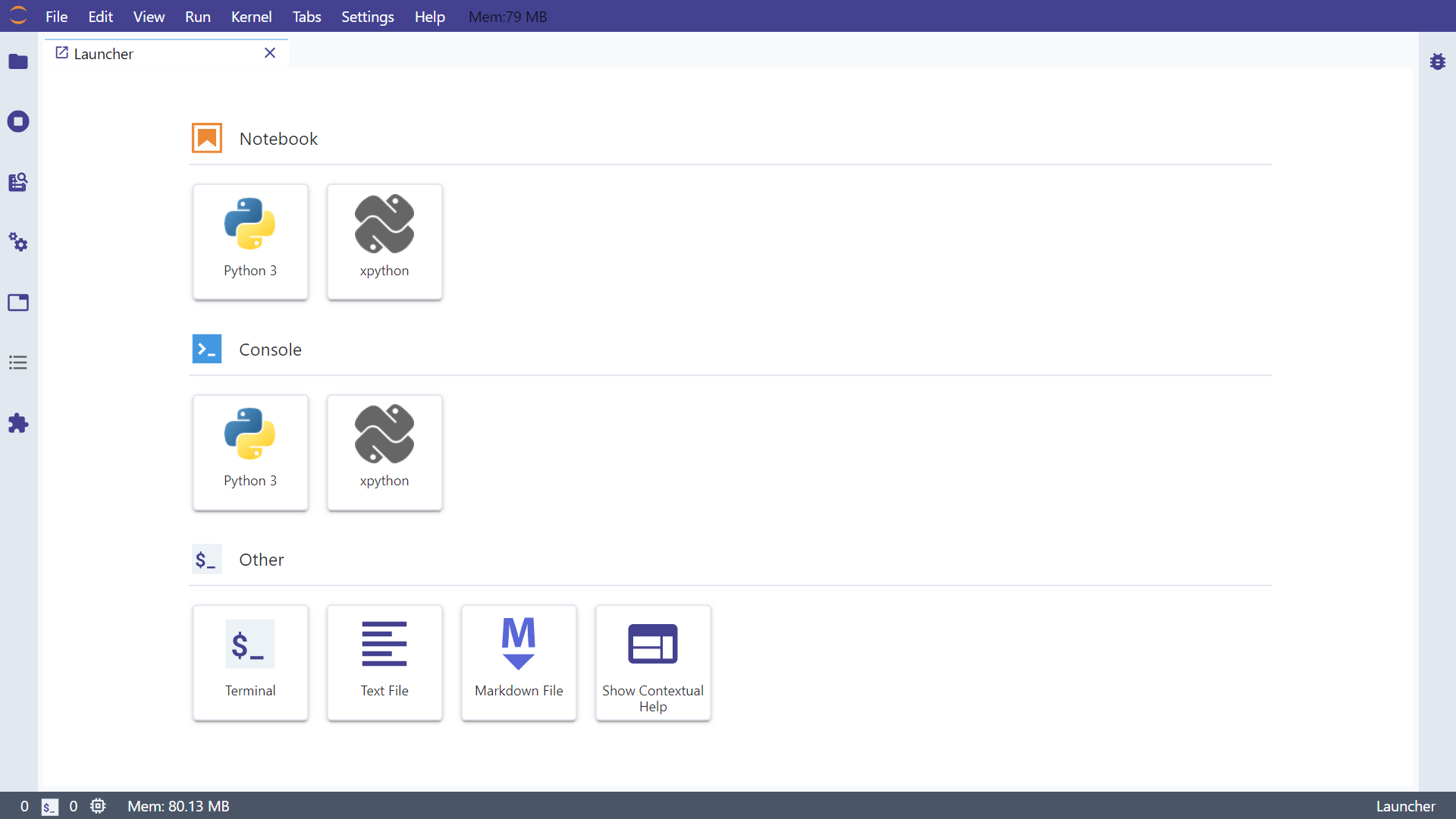
而在安装完成重启jupyter lab之后,除了左上角的jupyterlogo变化了之外,还新增了图中我用红框框选出来的地方:
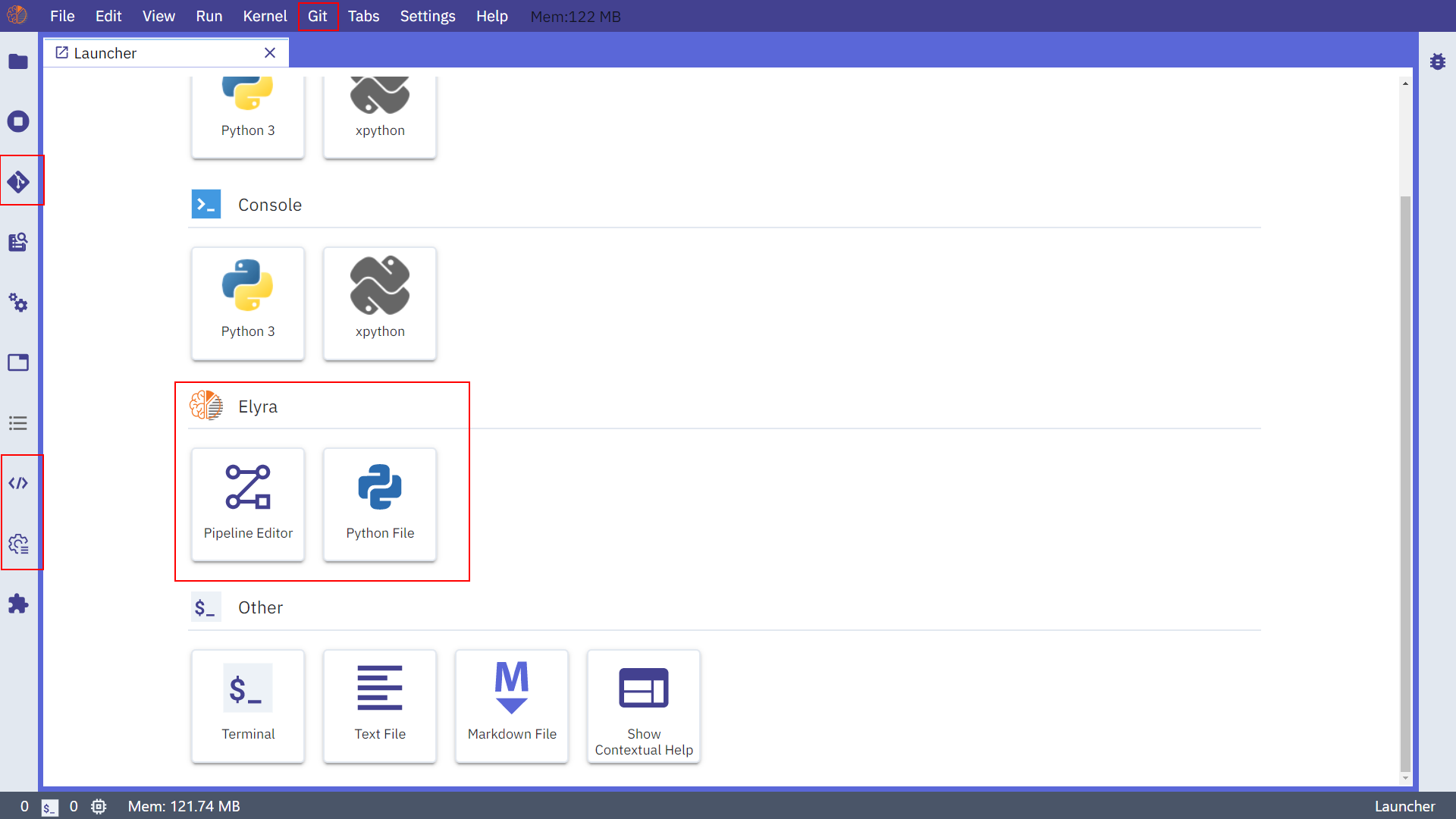
接下来我们就来介绍如何利用elyra交互式地搭建工作流。
elyra赋予了我们通过交互的方式将若干个ipynb文件组织成工作流的能力,为了方便演示,这里我们创建几个带有简单流程代码的ipynb文件:




接着我们在Launcher页面点击Pipeline Editor打开用来交互式编辑notebook流水线的界面:

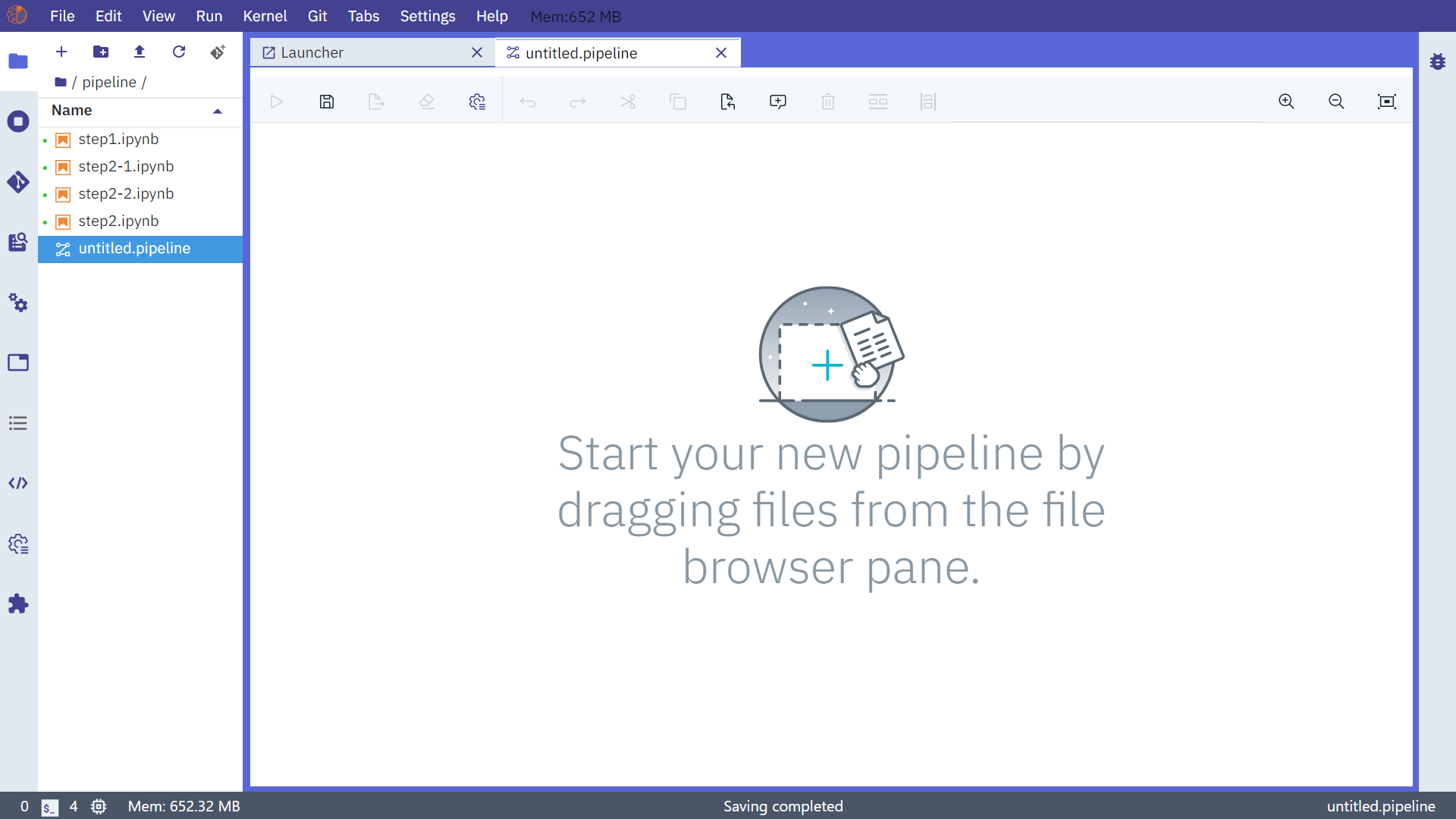
直接将侧边栏中对应的step1.ipynb文件拖拽进来:

点击流水线界面中ipynb文件对应节点右侧的三个圆点,可以打开更多功能选项:

因为我们是本地环境,所以这里只需要在properties下必填参数Runtime Image中随便选一个就行:

保存之后,就完成了本地环境下单个节点的必要参数设置,同样的将其他ipynb文件拖拽进来,各自配置好必要参数再如图13所示将各节点联结起来:

这样我们的流水线就搭建好了,是不是非常滴好玩~,接着点击左上角的运行按钮,输入流水线名称后即可开始运行我们的工作流:
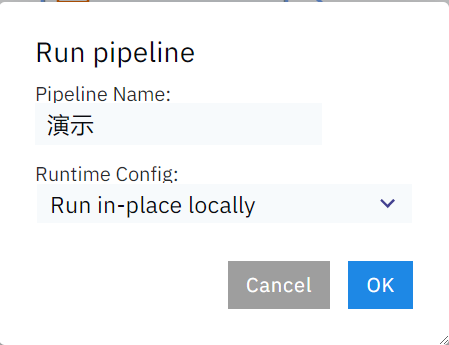
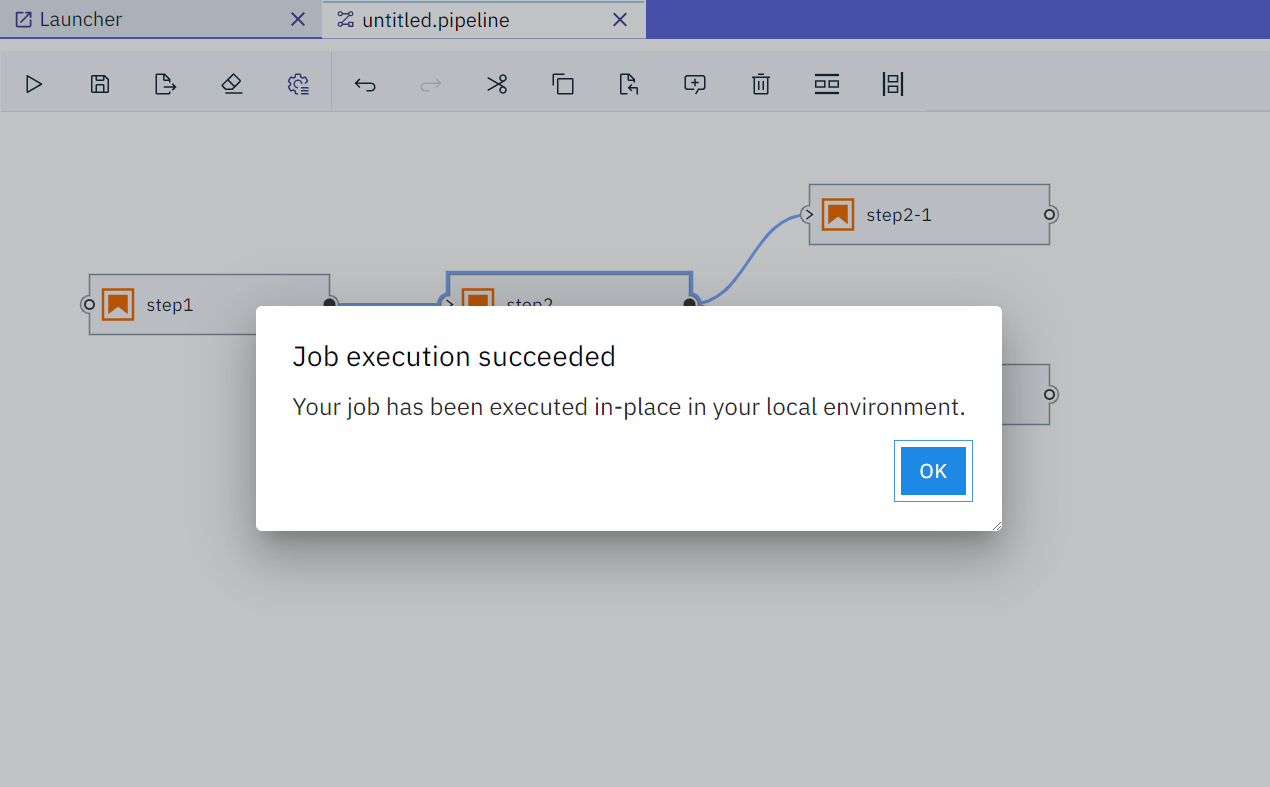
工作流执行成功之后也会有提示:
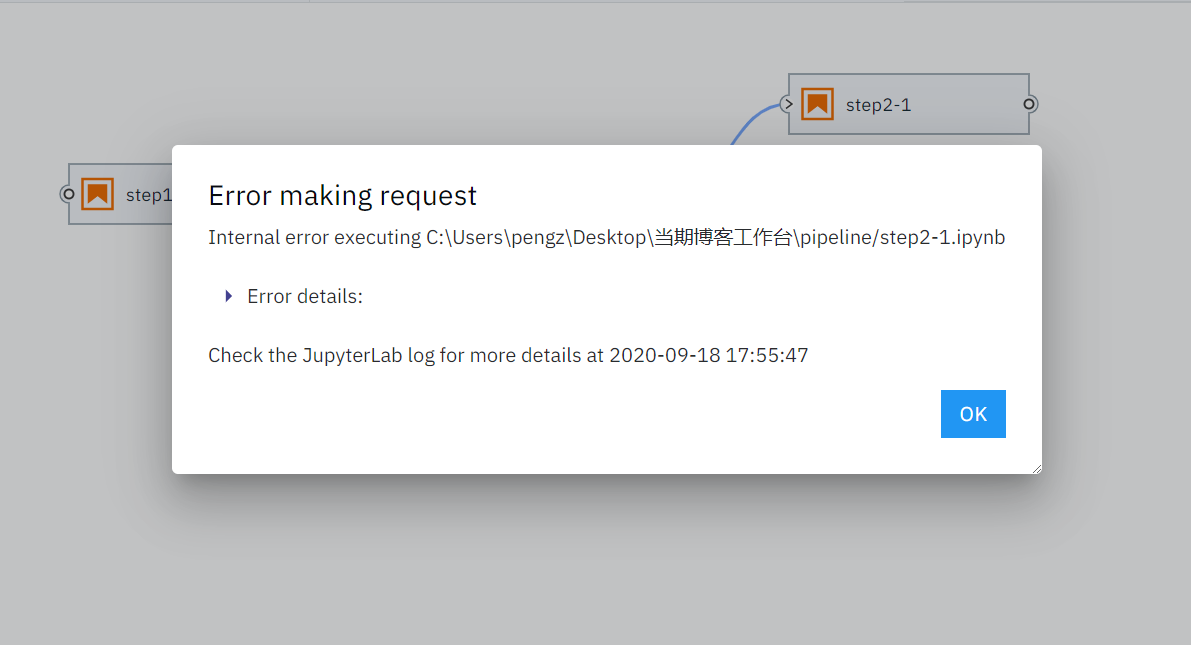
如果工作流执行到某个节点发生程序错误,也会有非常人性化的提示:
对应出错的ipynb错误代码块上方,elyra也会帮我们创建记录错误信息的markdown单元格:

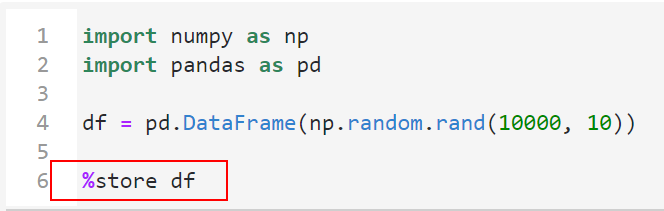
最好用的是,配合魔术命令%store,我们就可以跨notebook传递全局变量,而不需要再往外写出先前节点的结果文件:
利用%store 变量名将某个变量转化为跨kernel的全局变量:
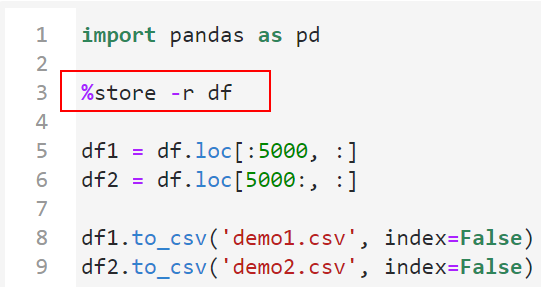
利用%store -r 变量名将跨kernel全局变量中的指定变量加载到当前kernel中:
而除了搭建工作流这个核心功能外,elyra还有很多其他的实用功能,感兴趣的朋友可以前往官方文档(https://elyra.readthedocs.io/en/latest/)自行阅读学习。

以上就是本文的全部内容,欢迎在评论区与我进行讨论~
相关文章
- 一篇运维老司机的大数据平台监控宝典(2)-联通大数据集群平台监控体系详解
- 一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解
- 空中换引擎 博时基金数字化转型经验谈
- 如何高效地学习编程语言
- 作为一名阿里巴巴数据分析大牛,送给学弟学妹的经验积分
- 为什么要学习R语言
- Hadoop大数据分析平台的介绍性讨论
- 最全面的Spring学习笔记
- 16个用于数据科学和机器学习的顶级平台
- 给有抱负的数据科学家的六条建议
- 如何做一枚合格的数据产品经理
- 除Kaggle外,还有哪些顶级数据科学竞赛平台
- 一个鲜为人知却可以保护隐私的训练方法:联合学习
- 干货 :送你12个关于数据科学学习的关键提示(附链接)
- 大数据行业有多少种工作岗位,各自的技能需求是什么?
- 中国移动研究院常耀斌:商用大数据平台的研发之路
- 这些数据科学家必备的技能,你拥有哪些?
- 自学成才的开发者有何优势和劣势?
- Gartner报告:正处于数据科学与机器学习工具 “大爆炸”的时代
- Ready Computing借助InterSystems IRIS医疗版为医疗机构提供具有高度互操作性和可扩展性的解决方案