
深度强化学习中的对抗攻击和防御
01 前言
该论文是关于深度强化学习对抗攻击的工作。在该论文中,作者从鲁棒优化的角度研究了深度强化学习策略对对抗攻击的鲁棒性。在鲁棒优化的框架下,通过最小化策略的预期回报来给出最优的对抗攻击,相应地,通过提高策略应对最坏情况的性能来实现良好的防御机制。
考虑到攻击者通常无法 在训练环境中 攻击,作者提出了一种贪婪攻击算法,该算法试图在不与环境交互的情况下最小化策略的预期回报;另外作者还提出一种防御算法,该算法以最大-最小的博弈来对深度强化学习算法进行对抗训练。
在Atari游戏环境中的实验结果表明,作者提出的对抗攻击算法比现有的攻击算法更有效,策略回报率更差。论文中提出的对抗防御算法生成的策略比现有的防御方法对一系列对抗攻击更具鲁棒性。
02 预备知识
2.1对抗攻击
给定任何一个样本(x,y)和神经网络f,生成对抗样本的优化目标为:
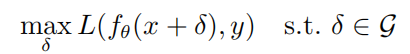
其中 是神经网络f的参数,L是损失函数, 是对抗扰动集合, 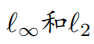 是以x为中心, 为半径的范数约束球。通过PGD攻击生成对抗样本的计算公式如下所示:
是以x为中心, 为半径的范数约束球。通过PGD攻击生成对抗样本的计算公式如下所示:
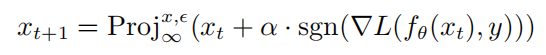
其中 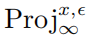 表示的是投影操作,如果输入在范数球外,则将输入投影到以x中心, 为半径的 球上, 表示的是PGD攻击的单步扰动大小。
表示的是投影操作,如果输入在范数球外,则将输入投影到以x中心, 为半径的 球上, 表示的是PGD攻击的单步扰动大小。
2.2强化学习和策略梯度
一个强化学习问题可以被描述为一个马尔可夫决策过程。马尔可夫决策过程又可以被定义为一个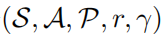 的五元组,其中S表示的是一个状态空间,A表示的是一个动作空间,
的五元组,其中S表示的是一个状态空间,A表示的是一个动作空间,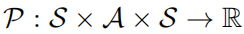 表示的是状态转移概率,r表示的是奖励函数, 表示的是折扣因子。强学学习的目标是去学习一个参数策略分布
表示的是状态转移概率,r表示的是奖励函数, 表示的是折扣因子。强学学习的目标是去学习一个参数策略分布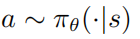 使得价值函数最大化
使得价值函数最大化
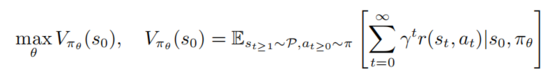
其中 表示的是初始状态。强学学习包括评估动作值函数
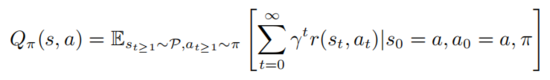
以上公式描述了在状态 执行 后服从策略 的数学期望。由定义可知值函数和动作值函数满足如下关系:
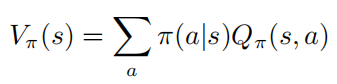
为了便于表示,作者主要关注的是离散动作空间的马尔可夫过程,但是所有的算法和结果都可以直接应用于连续的设定。
03 论文方法
深度强化学习策略的对抗攻击和防御是建立在是鲁棒优化PGD的框架之上的
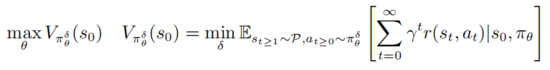
其中 表示的是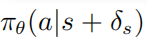 , 表示的是对抗扰动序列集合
, 表示的是对抗扰动序列集合 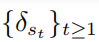 ,并且对于所有的
,并且对于所有的 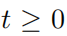 ,满足
,满足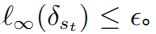 以上公式提供了一个深度强化学习对抗攻击和防御的统一框架。
以上公式提供了一个深度强化学习对抗攻击和防御的统一框架。
一方面内部最小化优化去寻找对抗扰动序列 使得当前策略 做出错误的决策。另一方面外部最大化的目的是找到策略分布参数 使得在扰动策略下期望回报最大。经过以上对抗攻击和防御博弈,会使得训练过程中的策略参数 能够更加抵御对抗攻击。
目标函数内部最小化的目的是生成对抗扰动 ,但是对于强化学习算法来说学习得到最优对抗扰动是非常耗时耗力的,而且由于训练环境对攻击者来说是一个黑盒的,所以在该论文中,作者考虑一个实际的设定,即攻击者在不同的状态下去注入扰动。不想有监督学习攻击场景中,攻击者只需要欺骗分类器模型使得它分类出错产生错误的标签;在强化学习的攻击场景中,动作值函数攻击者提供了额外的信息,即小的行为值会导致一个小的期望回报。相应的,作者在深度强化学习中定义了最优对抗扰动如下所示
定义1: 一个在状态s上最优的对抗扰动 能够最小化状态的期望回报
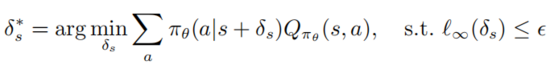
需要注意的是优化求解以上公式的是非常棘手的,它需要确保攻击者能够欺骗智能体使得其选择最差的决策行为,然而对于攻击者来说智能体的动作值函数是不可知的,所以无法保证对抗扰动是最优的。以下的定理能够说明如果策略是最优的,最优对抗扰动能够用不通过访问动作值函数的方式被生成
定理1: 当控制策略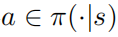 是最优的,动作值函数和策略满足以下关系
是最优的,动作值函数和策略满足以下关系
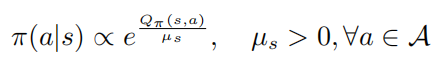
其中 表示的是策略熵, 是一个状态依赖常量,并且当 变化到0的时候, 也会随之变为0,进而则有以下公式
证明: 当随机策略 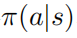 达到最优的时候,值函数
达到最优的时候,值函数 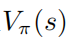 也达到了最优,这也就是说,在每个状态s下,找不到任何其它的行为分布使得值函数
也达到了最优,这也就是说,在每个状态s下,找不到任何其它的行为分布使得值函数 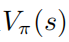 增大。相应的,给定最优的动作值函数
增大。相应的,给定最优的动作值函数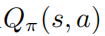 ,可以通过求解约束优化问题获得最优策略
,可以通过求解约束优化问题获得最优策略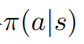
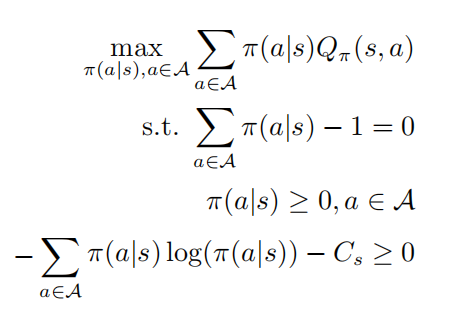
其中第二和第三行表示 是一个概率分布,最后一行表示策略 是一个随机策略,根据KKT条件则可以将以上优化问题转化为如下形式:
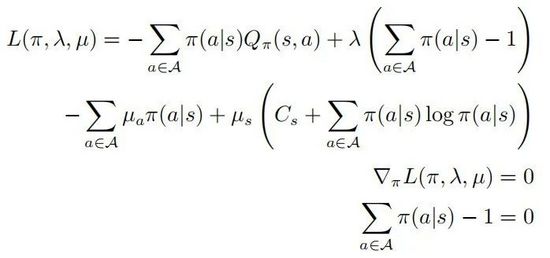
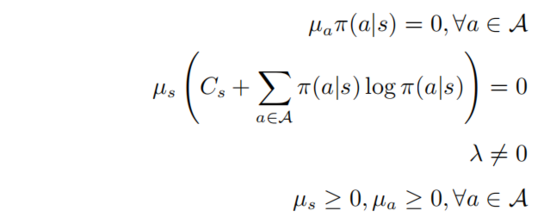
其中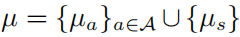 。假定
。假定 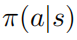 对于所有的行为
对于所有的行为 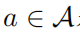 是正定的,则有:
是正定的,则有:
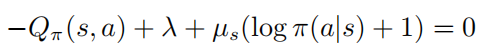
当 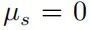 ,则必有
,则必有 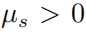 ,进而则有对于任意的
,进而则有对于任意的 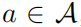 ,则有
,则有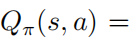 从而会得到动作值函数和策略的softmax的关系
从而会得到动作值函数和策略的softmax的关系
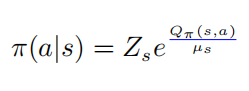
其中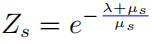 ,进而有
,进而有
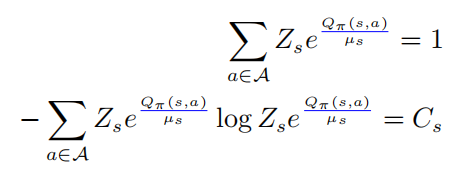
将以上的第一个等式带入到第二中,则有
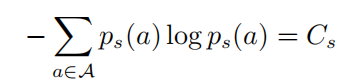
其中
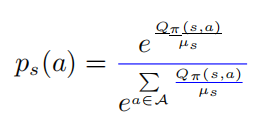
以上公式中 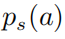 表示的是一个softmax形式的概率分布,并且它的熵等于 。当 等于0的时候, 也变为0.在这种情况下, 是要大于0的,则此时
表示的是一个softmax形式的概率分布,并且它的熵等于 。当 等于0的时候, 也变为0.在这种情况下, 是要大于0的,则此时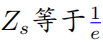 。
。
定理1展示了如果策略是最优的情况下,最优扰动可以通过最大化扰动策略和原始策略的交叉熵来获得。为了讨论的简便,作者将定理1的攻击称之为策略攻击,而且作者使用PGD算法框架去计算最优的策略攻击,具体的算法流程图如下算法1所示。

作者提出的防御对抗扰动的鲁棒优化算法的流程图如下算法2所示,该算法被称之为策略攻击对抗训练。在训练阶段,扰动策略 被用作去和环境交互,与此同时扰动策略的动作值函数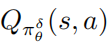 被估计去帮助策略训练。
被估计去帮助策略训练。
具体的细节为,首先在训练阶段作者使用策略攻击去生成扰动,即使值函数没有保证被减小。在训练的早期阶段,策略也许跟动作值函数不相关,随着训练的进行,它们会慢慢满足softmax 的关系。
另一方面作者需要精确评估动作值函数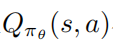 很难处理,因为轨迹是通过运行受干扰的策略收集的,而使用这些数据估计未受干扰策略的作用值函数可能非常不准确。
很难处理,因为轨迹是通过运行受干扰的策略收集的,而使用这些数据估计未受干扰策略的作用值函数可能非常不准确。

使用PPO的优化扰动策略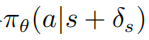 的目标函数为
的目标函数为
其中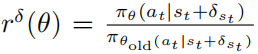 ,并且
,并且 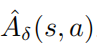 是扰动策略平均函数
是扰动策略平均函数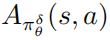 的一个估计。在实际中,
的一个估计。在实际中,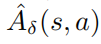 是由方法GAE估计得来的。具体的算法流程图如下图所示。
是由方法GAE估计得来的。具体的算法流程图如下图所示。

04 实验结果
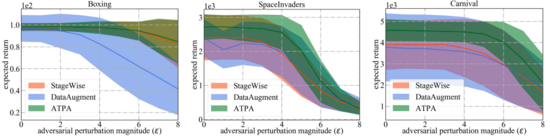
如下右侧的三个子图显示了不同攻击扰动的结果。可以发现经过逆向训练的策略和标准策略都能抵抗随机扰动。相反,对抗攻击会降低不同策略的性能。结果取决于测试环境和防御算法,进一步可以发现三种对抗性攻击算法之间的性能差距很小。
相比之下,在相对困难的设置环境中,论文作者提出的策略攻击算法干扰的策略产生的回报要低得多。总体而言,论文中提出的策略攻击算法在大多数情况下产生的回报最低,这表明它确实是所有经过测试的对抗攻击算法中效率最高的。

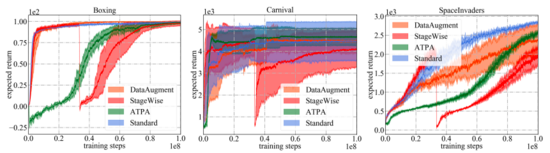
如下图所示显示了不同防御算法以及标准PPO的学习曲线。需要注意的是性能曲线仅表示用于与环境交互的策略的预期回报。在所有的训练算法中,论文中提出的ATPA具有最低的训练方差,因此比其他算法更稳定。另外还能注意到,ATPA的进度比标准PPO慢得多,尤其是在早期训练阶段。这导致了这样一个事实,即在早期的训练阶段,受不利因素干扰会使得策略训练非常不稳定。
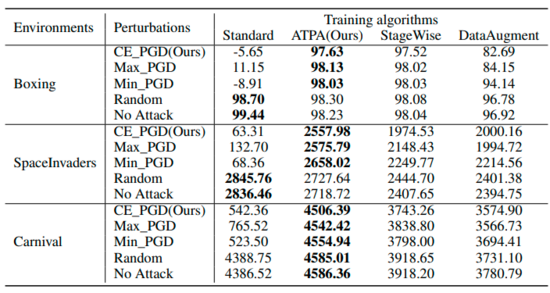
表总结了使用不同算法在不同扰动下的策略预期回报。可以发现经过ATPA训练的策略能够抵抗各种对抗干扰。相比之下,尽管StageWise和DataAugment在某种程度上学会了处理对抗攻击,但它们在所有情况下都不如ATPA有效。
为了进行更广泛的比较,作者还评估了这些防御算法对最有效的策略攻击算法产生的不同程度的对抗干扰的鲁棒性。如下图所示,ATPA再次在所有情况下获得最高分数。此外,ATPA的评估方差远小于StageWise和DataAugment,表明ATPA具有更强的生成能力。
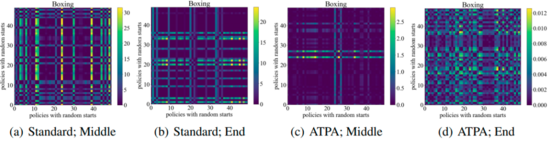
为了达到类似的性能,ATPA需要比标准PPO算法更多的训练数据。作者通过研究扰动策略的稳定性来深入研究这个问题。作者计算了通过在训练过程中间和结束时使用不同随机初始点的PGD执行策略攻击而获得的扰动策略的KL散度值。如下图所示,在没有对抗训练的情况下,即使标准PPO已经收敛,也会不断观察到较大的KL 散度值,这表明策略对于使用不同初始点执行PGD所产生的扰动非常不稳定。
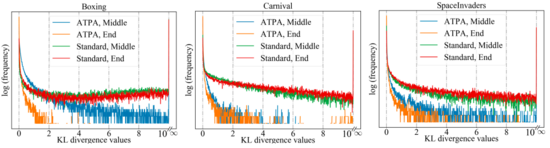
下图显示了具有不同初始点的扰动策略的KL散度图,可以发现图中的每个像素表示两个扰动策略的KL散度值,这两个扰动策略通过最大化ATPA算法的核心公式给出。需要注意的是由于KL散度是一个非对称度量,因此这些映射也是不对称的。
相关文章
- 金融服务领域的大数据:即时分析
- 影响大数据、机器学习和人工智能未来发展的8个因素
- 从0开始构建一个属于你自己的PHP框架
- 如何将Hadoop集成到工作流程中?这6个优秀实践必看
- SEO公司使用大数据优化其模型的5种方法
- 关于Web Workers你需要了解的七件事
- 深入理解HTTPS原理、过程与实践
- 增强分析:数据和分析的未来
- PHP协程实现过程详解
- AI专家:大数据知识图谱——实战经验总结
- 关于PHP的错误机制总结
- 利用数据分析量化协同过滤算法的两大常见难题
- 怎么做大数据工作流调度系统?大厂架构师一语点破!
- 2019大数据处理必备的十大工具,从Linux到架构师必修
- OpenCV中的KMeans算法介绍与应用
- 教大家如果搭建一套phpstorm+wamp+xdebug调试PHP的环境
- CentOS下三种PHP拓展安装方法
- Go语言HTTP Server源码分析
- Go语言HTTP Server源码分析
- 2017年4月编程语言排行榜:Hack首次进入前五十