
联邦学习:按病态非独立同分布划分Non-IID样本
在博文《分布式机器学习、联邦学习、多智能体的区别和联系》中我们提到论文[1]联邦学习每个client具有数据不独立同分布(Non-IID)的性质。
联邦学习的论文多是用FEMNIST、CIFAR10、Shakespare、Synthetic等数据集对模型进行测试,这些数据集包括CV、NLP、普通分类/回归这三种不同的任务。在单次实验时,我们对原始数据集进行非独立同分布(Non-IID) 的随机采样,为(T)个不同非任务生成(T)个不同分布的数据集。
我们在博文《联邦学习:按Dirichlet分布划分Non-IID样本》中已经介绍了按照Dirichlet分布划分non-IID样本。
然而联邦学习最开始采用的数据划分方法却不是这种。这里我们重新回顾联邦学习开山论文[1],它所采用的的是一种病态非独立同分布(Pathological Non-IID)划分算法。以下我们以CIFAR10数据集的生成为例,来详细地对该论文的数据集划分与采样算法进行分析。
首先,如果选择这种划分方式,需要指定则每个client上数据集所需要的标签类型数做为超参, 该划分算法的函数原型一般如下:
def pathological_non_iid_split(dataset, n_classes, n_clients, n_classes_per_client):
我们解释一下函数的参数,这里dataset是torch.utils.Dataset类型的数据集,n_classes表示数据集里样本分类数,n_client表示client节点的数量,该函数返回一个由n_client各自所需样本索引组成的列表client_idcs。
接下来我们看这个函数的内容。该函数完成的功能可以概括为:先将样本按照标签进行排序;再将样本划分为n_client * n_classes_per_client个shards(每个shard大小相等),对n_clients中的每一个client分配n_classes_per_client个shards(分配到client后,每个client中的shards要合并)。
首先,从数据集索引data_idcs建立一个key为类别({0,1,...,n\_classes-1}),value为对应样本集索引列表的字典,这在实际上这就相当于按照label对样本进行排序了。
data_idcs = list(range(len(dataset)))
label2index = {k: [] for k in range(n_classes)}
for idx in selected_idcs:
_, label = dataset[idx]
label2index[label].append(idx)
sorted_idcs = []
for label in label2index:
sorted_idcs += label2index[label]
然后该函数将数据分为n_clients * n_classes_per_client 个独立同分布的shards,每个shards大小相等。然后给n_clients中的每一个client分配n_classes_per_client个shards(分配到client后,每个client中的shards要合并),代码如下:
def iid_divide(l, g):
"""
将列表`l`分为`g`个独立同分布的group(其实就是直接划分)
每个group都有 `int(len(l)/g)` 或者 `int(len(l)/g)+1` 个元素
返回由不同的groups组成的列表
"""
num_elems = len(l)
group_size = int(len(l) / g)
num_big_groups = num_elems - g * group_size
num_small_groups = g - num_big_groups
glist = []
for i in range(num_small_groups):
glist.append(l[group_size * i: group_size * (i + 1)])
bi = group_size * num_small_groups
group_size += 1
for i in range(num_big_groups):
glist.append(l[bi + group_size * i:bi + group_size * (i + 1)])
return glist
n_shards = n_clients * n_classes_per_client
# 一共分成n_shards个独立同分布的shards
shards = iid_divide(sorted_idcs, n_shards)
np.random.shuffle(shards)
# 然后再将n_shards拆分为n_client份
tasks_shards = iid_divide(shards, n_clients)
clients_idcs = [[] for _ in range(n_clients)]
for client_id in range(n_clients):
for shard in tasks_shards[client_id]:
# 这里shard是一个shard的数据索引(一个列表)
# += shard 实质上是在列表里并入列表
clients_idcs[client_id] += shard
最后,返回clients_idcs
return clients_idcs
接下来我们在EMNIST数据集上调用该函数进行测试,并进行可视化呈现。我们设client数量(N=10),每个client规定有两种标签类型样本。
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
np.random.seed(42)
if __name__ == "__main__":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1.0
N_CLASSES_PER_CLIENT=2 # 每个client规定有两种标签类型样本
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# 按照病态独立同分布划分
client_idcs = pathological_non_iid_split(train_data, num_cls, N_CLIENTS, N_CLASSES_PER_CLIENT)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
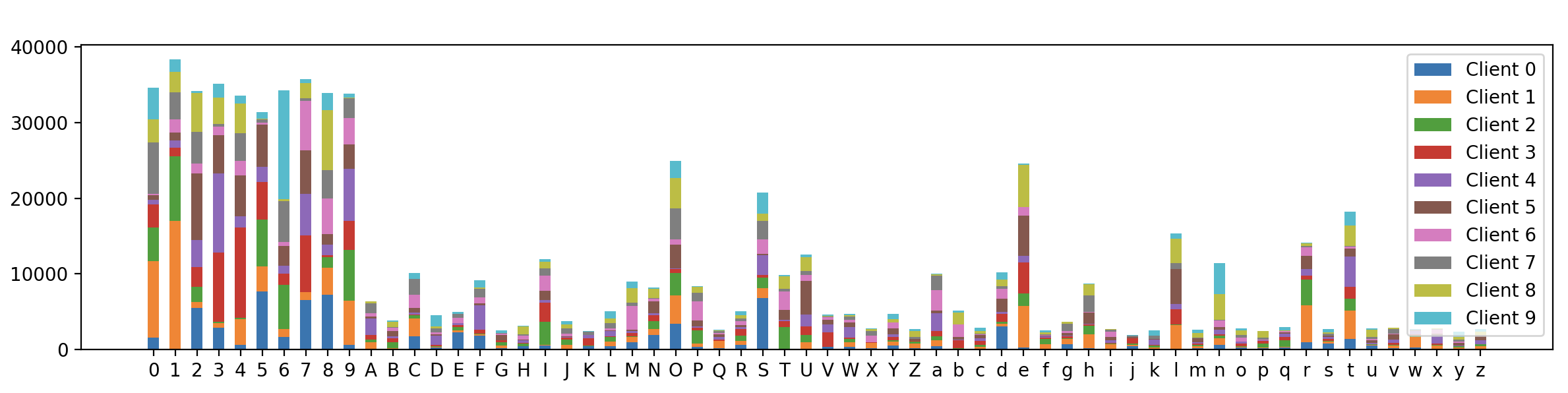
最终的可视化结果如下:

可以看到,62个类别标签在不同client上的分布确实不同,且每个client上的样本类型近似数量为两个,但不能保证每个client的绝对类别数是两个,因为该算法对两个类别的话是直接将标签切分为n_client*2个块(然而并不能保证每个块只有一个类别),然后每个client分得2个块。不过,该算法相比下面按照Dirichlet分布划分的样本仍然具有大大的不同。这证明我们的样本划分算法是有效的。
参考
- [1] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
相关文章
- 一篇运维老司机的大数据平台监控宝典(2)-联通大数据集群平台监控体系详解
- 一篇运维老司机的大数据平台监控宝典(1)-联通大数据集群平台监控体系进程详解
- 空中换引擎 博时基金数字化转型经验谈
- 如何高效地学习编程语言
- 作为一名阿里巴巴数据分析大牛,送给学弟学妹的经验积分
- 为什么要学习R语言
- Hadoop大数据分析平台的介绍性讨论
- 最全面的Spring学习笔记
- 16个用于数据科学和机器学习的顶级平台
- 给有抱负的数据科学家的六条建议
- 如何做一枚合格的数据产品经理
- 除Kaggle外,还有哪些顶级数据科学竞赛平台
- 一个鲜为人知却可以保护隐私的训练方法:联合学习
- 干货 :送你12个关于数据科学学习的关键提示(附链接)
- 大数据行业有多少种工作岗位,各自的技能需求是什么?
- 中国移动研究院常耀斌:商用大数据平台的研发之路
- 这些数据科学家必备的技能,你拥有哪些?
- 自学成才的开发者有何优势和劣势?
- Gartner报告:正处于数据科学与机器学习工具 “大爆炸”的时代
- Ready Computing借助InterSystems IRIS医疗版为医疗机构提供具有高度互操作性和可扩展性的解决方案